數據挖掘 SPSS Modeler 腳本功能的應用場景和編寫技巧
數據挖掘軟件 IBM SPSS Modeler 以用戶界面友好����、可視化功能強大著稱��。關于其腳本功能�,參考資料很少�����。作者認為�,腳本功能實際上旨在實現數據處理和分析建模過程的自動化���。在需要動態改變數據處理過程���、數據流自動執行和自動執行批量任務等應用場景下�����,必須補充編寫一些腳本才能完成某些特定功能��。所以��,腳本功能是用戶界面的必要補充��,而不僅僅是用戶界面鼠標操作功能的代碼化�����。
SPSS Modeler 自帶的腳本編寫用戶指南沒有按照腳本功能的常用應用場景組織內容���,這給腳本編寫人員參考查閱造成一定的不便�。同時��,缺少完整的實用的例子��,給出的例子多數是模擬用戶界面上的常用操作���。而實際情況是編寫腳本通常是為了補充用戶界面上很少使用或者不能實現的功能��。作者就經常為找不到可以參考的例子而苦惱�����。
本文首先介紹用戶界面上無法或者不便實現而必須編寫腳本的常見的五種應用場景�。每種場景下均給出完整的應用實例�,重點介紹腳本編寫的方法和技巧���。在第二節��,基于作者經驗�����,總結了編寫腳本的常用技巧��。本文所附的實例均來自實際項目��,且在 SPSS Modeler 15.0 環境下測試通過��。
腳本功能的應用場景
什么情況下需要腳本功能�?根據作者的經驗����,遇到下列情況應考慮使用腳本功能:需要重復執行某些數據處理�����;需要動態改變數據處理的過程���;數據流最終需要部署到第三方環境�����;數據流需要自動執行 ( 而不是鼠標操作執行 )����;需要批量修改已有的數據流或者自動執行批量任務���。
重復執行的數據處理
我們知道�����,Modeler 數據流默認都是順序執行的����,多個節點的依次連接而成的數據流提前指定了數據處理的順序��。然而�����,實際建模中經常會遇到部分數據流需要重復多次執行��,且可能帶參數���,這時手工執行就很不方便�。同時���,可能需要根據某個變量的取值重復執行一段數據流 ( 實現動態循環 )���,這種情況下就必須借助腳本來實現�。
圖 1 所示的數據流來自是一個預測產品銷售的時間序列模型�����。需要分別預測每個銷售分支機構 (IMT) 在未來一個季度的銷售總額����。當銷售機構較多 (=21) 且動態變化時�,需要根據 Table 節點 IMT_List 的輸出結果���,循環多次逐行取出 IMT 的取值���,然后根據此值設置 Select1 和 IMT 節點�,從而實現動態的重復執行的數據處理�����。這里的主要技巧是從 Table 節點循環取數�。
圖 1. 從 Table 節點循環取數

點擊查看大圖
圖 1 中方框內的三個節點是腳本涉及的主要部分����,對應的腳本內容如下:
清單 1 腳本內容 - 從 Table 節點循環取數
清單 1. 腳本內容 - 從 Table 節點循環取數

腳本編寫的要點:執行 Table 節點讀取所有的循環變量取值�����。利用 Result 對象的 output 屬性和 Value 命令逐個讀取循環變量的取值����。使用 set 命令為多個節點動態賦值���。
動態改變的數據處理過程
SPSS Modeler 數據流默認都是順序執行的����,多個節點的依次連接而成的數據流預先指定了數據處理過程�。如果需要改變順序執行為根據條件執行不同的流分支�����,則需要使用腳本 if...then...else... 命令�。
下面的實例來自一個銷售績效評估項目��,需要根據用戶命令行參數的設置自動選擇執行不同的數據流分支����。具體來說�,根據命令行參數��,自動選擇是否重新訓練模型和根據不同季度選擇不同的數據調整方法���。
圖 2. 根據命令行參數選擇是否訓練模型和季度調整方法
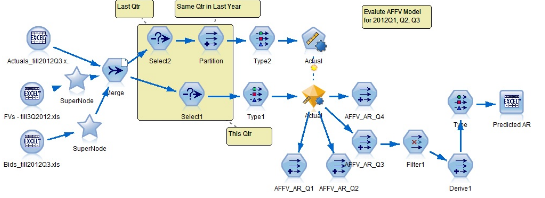
這個數據流在用戶界面上調試時�����,不需要腳本�,但是當部署完成集成到生產環境下自動執行時��,就必須編寫一些腳本以實現根據命令行參數動態選擇不同的數據處理過程��。本例的腳本如下:
清單 2. 帶命令行參數的腳本

腳本編寫的要點:使用 if...then...else... 命令��,結合 CLEM 表達式和腳本參數��,實現根據命令行參數動態選擇不同的數據處理過程�。
部署到第三方環境的數據流
構建好的數據流可能需要部署到第三方環境下使用����。此時�,數據流的執行往往不同于 SPSS Modeler 環境��,有些情況下必須編寫一點腳本���,以實現預設的功能��。
最簡單的部署數據流的方法是使用 SPSS Modeler 批處理方式 (Batch Mode) 在第三方環境通過執行批命令來執行數據流����。另外一種常用的部署方法是使用 Solution Publisher 在第三方環境執行數據流����。下面就這兩種部署方法分別給出一個應用實例�。圖 3 是一個資產效能優化項目中展示變壓器報警分布情況的數據流���。
圖 3. 部署到第三方環境的數據流 (Batch Mode)
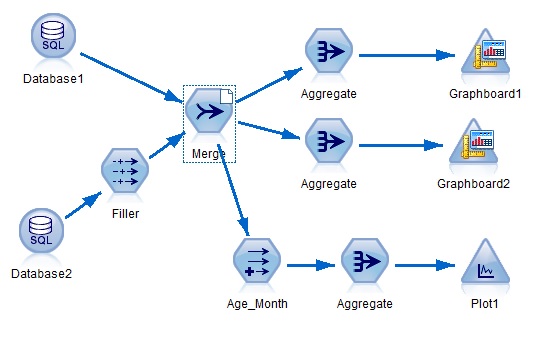
清單 3. 批處理方式部署

在用戶界面上操作時不需要右邊圖示的腳本�,但如果需要把這個流文件部署到第三方環境執行時����,就必須增加這些腳本��,且必須設置為與數據流同步執行 ( 選擇 Run this script)���。否則會提示輸入數據庫源節點的 Password 且不會自動執行三個圖形輸出節點��。對應的執行這個數據流的批命令文件的內容如下:
批處理命令
...\clemb.exe -hostname IP -port 28052 -username UN -password PW -stream "...\Alarm Distribution Pattern Transformer.str" -execute -server -appendlog
下面的例子是一個資產效能優化項目中預測鐵路設備故障的數據流��。
圖 4. 部署到第三方環境的數據流 (Solution Publisher)
清單 4. Solution Publisher 部署

這些腳本在部署環境下執行必須編寫�,否則提問密碼����,而且不能更新模型和輸出預測結果���。所以�,用戶界面下正常執行的數據流����,在完成部署并自動執行的情況下���,有些功能必須借助腳本來實現���。特別需要注意的是:如果沒有 insert model 這行腳本����,模型就不能正常更新����。沒有腳本 execute 'Alarm Rail'����,預測結果就不能輸出到指定的數據庫表���。對應的調用 Solution Publisher 執行這個數據流的批命令文件的內容如下:
批處理命令
"...\modelerrun.exe" -p "...\Alarm_Prediction_Rail.par" "...\Alarm_Prediction_Rail.pim"
自動執行的數據流
構建好的數據流可能需要部署到正式的生產環境��,這時通常需要定期地自動執行這些數據流��。直接復制用戶界面調試好的數據流 ( 手工執行 )���,當在生產環境自動執行時�����,有些功能就可能不能實現����。
自動執行數據流有三種模式:Batch 模式��、Client 模式和 Solution Publisher 模式����。對應的可執行文件分別為:clemb.exe�����、modelerclient.exe 和 modelerrun.exe���。前兩種模式的典型命令行命令如下:
命令
clemb/modelerclient -server -hostname myserver -port 80 -username dminer -password 1234 -stream mystream.str -execute
對于 Solution Publisher 模式��,在 Command Line 窗口下的執行命令如下:
命令
modelerrun – p *.par *.pim
當需要自動執行數據流時�,原先在用戶界面上調試好的�����,即手工執行的數據流可能需要補充一些腳本以實現指定的功能�����。例如�����,建模節點的自動執行�、模型節點的自動更新�����、導出類節點 (Export) 的結果導出等都需要編寫腳本��。
圖 5 所示是一個資產效能優化項目中挖掘變壓器失效與 DCS 監控數據異常的關聯規則的數據流���。這個數據流需要使用 Solution Publisher 部署到第三方環境自動執行���,同時需要輸出關聯規則到數據庫����。由于 Solution Publisher 只支持二維數據的輸出而不能輸出關聯規則模型本身����,所以難點在于如何自動更新模型并輸出關聯規則模型本身的結果到 Oracle 數據庫表�,這就需要編寫腳本���。這個實例的特點是同時實現了建模節點的自動執行���、模型節點的自動更新和導出節點的結果保存����。
圖 5. 關聯規則的自動輸出
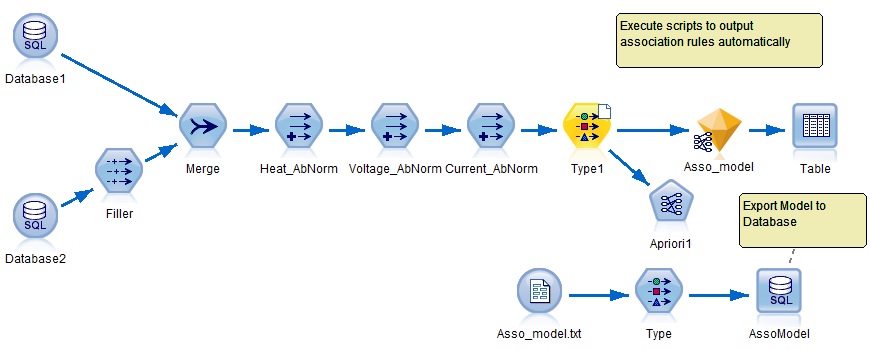
點擊查看大圖
清單 5. 關聯規則自動輸出的腳本

腳本編寫的要點:使用 set 命令提前設置數據庫密碼�����。使用 export model 命令輸出關聯規則模型為純文本文件����。使用 Export 節點把純文本格式的關聯規則輸出到數據庫����。
自動執行的批量任務
實際應用中可能會遇到需要批量修改已有的數據流�,以提高模型構建效率或者適用不同的客戶項目�����。例如�,可能需要把所有字段名修改為大寫字母�����。手工修改對于節點或字段較多時就不方便�。
下面的例子來自一個資產效能優化項目��。以前調試好的數據流���,原先數據導出到 Excel 表����,現在客戶環境發生變化需要導出到 Oracle 數據庫�。由于 Oracle 數據庫的庫表名稱和字段名稱必須用大寫字母且不能有空格�,所以需要批量替換所有的 Filter 節點的小寫字母和中間空格���。手工修改對于 Filter 節點較多或字段較多時不方便�����,可以使用腳本自動修改���。下面一段腳本�����,可以實現類似于圖 6 所示的 Filter 節點 (Filter_Out) 的所有 Filter 節點的字段名稱的大寫轉換和空格到下劃線的轉換�。
圖 6. 字段名稱大寫和空格的自動轉換
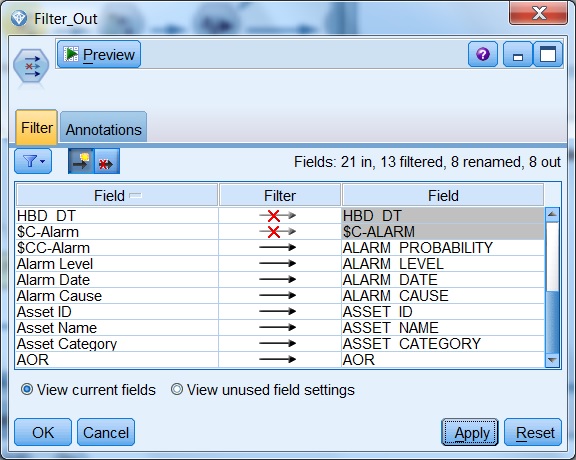
清單 6. 批量任務的腳本

腳本編寫的要點:搜索當前數據流中包含的所有 Filter 節點�����,然后逐個節點對新的字段名稱逐個進行大寫轉換�����,并把中間空格替換為下劃線���。使用了 set 命令����、循環語句和條件語句����。
腳本編寫的常用技巧
腳本運行不同于鼠標操作的情況
SPSS Modeler 腳本功能是輔助的�����,鼠標操作是其基本的使用方式����。所以���,有些看似功能類似的腳本在實際運行時的效果不同于鼠標操作���。常見情況可分為三種:
? 腳本中使用的節點需要重新命名�����。不同于鼠標操作模式����,在運行腳本時不能出現重名的節點���,否則報錯��。
? 建模節點的腳本執行不會自動更新模型節點 (Nugget)�����。例如���,圖 5 所示腳本的命令 execute 'Apriori1'僅執行建模節點'Apriori1'并把建好的模型節點放到管理器��,而不自動更新工作區的模型節點���,需要編寫腳本把模型節點插入 ( 使用命令 insert model)��。
? 使用腳本執行數據流時�����,末端的圖形或數據的輸出節點不會自動執行��。例如�����,本文“1.3 部署到第三方環境的數據流”一節圖 3 所示的例子��,在用戶界面上�����,點擊按鈕“運行當前流”(Run the current stream)����,所有末端的輸出節點自動執行�,但當部署到第三方環境執行這個數據流時�,就需要在這個數據流上附加腳本才能完成輸出�����。
腳本編寫的常用技巧
屏蔽文件覆蓋的提問:腳本自動執行時不希望中間跳出窗口提問是否覆蓋文件��。這個功能沒有對應的腳本命令���,只能使用菜單改變該數據流的用戶選項 (Tools...Options...User Options)��,不選 Warn when a node overwrites a file��。
調試方法:沒有提供調試功能���,只能點擊按鈕 Run selected lines only��,選擇部分腳本運行��。
自動刷新數據源節點:當原始數據改變時����,需要刷新對應的數據源節點����。使用命令 set ^stream.refresh_source_nodes = True 實現所有數據源節點的自動刷新���。
屏蔽數據源密碼提問:對應通過 ODBC 連接的數據庫數據源�,數據流自動執行時會提問密碼��。屏蔽這種提問的命令:set 'Database1':databasenode.password = "mypassword"
模型節點的自動更新:不同于鼠標操作��,腳本執行建模節點不會自動更新對應的模型節點���。需要使用 insert model 命令更新模型���。如果需要同時更新多個模型節點�,還需使用 duplicate 命令�����。例如�����,下列腳本根據建模節點 AutoNumeric 的執行結果��,自動更新 Actual2 和 Actual3 兩個模型節點:
execute 'AutoNumeric'
insert model Actual2 connected between 'Type2':typenode and 'AFFV_AR_Q1':derivenode
duplicate Actual2 as Actual3 connected between 'Type3':typenode and 'Filter3':filternode
清除已有的模型節點:常用命令有三種����,注意它們的區別����。
delete Actual2 ( 命令 delete NODE) 從工作區上刪除模型節點�;
clear generated palette 清除管理器上的所有模型節點�;
delete model Actual2 清除管理器上而不是刪除工作區的模型節點��。
高級腳本功能需要使用對象 (Object):常用的對象有四種:Output; Node; Model; Result���。每類對象都有一些專用的命令用于定義和檢索這些對象��,例如 get output; execute 'Node1'; export model; value 'Result1' at Row1 Column1��。詳細命令參見用戶指南第四章內容 (Scripting Commands)��。例如�,根據 Table 節點的輸出讀取循環變量��,就可使用 Result 對象的 value 命令����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
