大數據分析之—基于模型的復雜數據多維聚類分析
隨著現實和虛擬世界的數據產生速度越來越迅猛�����,人們開始關注如何從這些數據中獲取信息��,知識��,以及對于決策的支持���。這樣的任務通常被稱作大數據分析(BigData Analytics)���。大數據分析的難點很多���,比如�����,由于海量數據而帶來的分析效率瓶頸��,使用戶不能及時得到分析結果����;由于數據源太多而帶來的非結構化問題�,使傳統的數據分析工具不能直接利用�����。
本文討論大數據內部關系的復雜性���,以及復雜數據所帶來的對于聚類分析的挑戰���。聚類分析的目標是依據數據本身的分布特征(無監督)�����,把整個數據(空間)劃分成不同的類�?��;镜臏蕜t是同類的數據應該具有某種的相似性�����,而異類的數據應該具有某種差異性?��,F有工作假設在這些數據中存在單一的聚類劃分的方法��,而聚類目標就是找到這樣的一種劃分�。然而�����,我們在大數據中所面對的復雜數據是多側面的��,比如在網頁數據中既有關于內容的文本屬性��,也有指向這個網頁的鏈接屬性���。多側面數據本身就存在著多種有意義的劃分����,強制地將數據按照單一的方法聚類�,得不到有效的��、明確清晰的�、可詮釋的結果��。針對這個問題�����,多維聚類方法針對數據的不同側面��,得到數據聚類的多種方法���,最后讓使用者決定需要的聚類劃分����。
高維復雜數據的聚類分析是本文作者在香港科技大學跟隨Nevin Zhang教授攻讀博士期間的主要工作����。研究論文Model-based multidimensional clustering ofcategorical data發表在今年《ArtificialIntelligence》雜志的第176期���?��!禔rtificialIntelligence》從1970年開始出版�,是人工智能領域老牌頂級期刊�。因為版權原因����,可能網上下載不到免費的全文��,感興趣的同學可以聯系tao.chen2@emc.com��。關于文中所用的隱樹模型的介紹以及免費軟件參見隱樹模型項目主頁���。
(二)多維聚類的概念
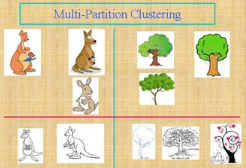
假設我們需要對圖中的所有圖片進行聚類�����,可能的聚類方法不止一種:按照圖片的內容��,我們可以把左邊的圖片標注成袋鼠�,而右邊的標注成樹���;而按照圖片風格屬性�����,我們可以把上面的圖片稱為色彩圖�,而下面的稱為線條圖����。簡而言之����,關注數據的不同側面��,有可能得到不同的聚類結果��。同時這些聚類結果也都是有意義���,可以解釋的��。
生活中多維聚類的例子很多�����,比如對于人群的劃分����,可以按照男女等人口統計學信息劃分��,也可以按照對于某個事件的看法劃分�。那么從機器學習的角度如何公式化這樣的問題���,之后又怎么利用概率統計的方法去解決這樣的問題呢��?下面我們先給出問題的定義����。
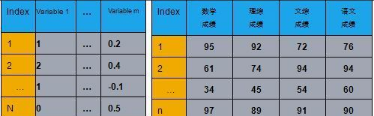
如圖所示����,在聚類分析這樣的無監督學習中����,輸入是一個數據表�����。表的每一行表示一個數據點��,而每一列表示描述這個點的一維屬性����。大數據的一個重要特征就是維度很高(包含很多列)����,從而帶來的維度災難(curseof dimensionality)����。在聚類分析中���,表現為:這些維度可能自然地分成一些組����,每組包含一些屬性����,反應了數據某一側面(facet)的特征�。用戶可以根據其中一個側面的屬性�,對這個數據進行聚類����。比如在右表的數據中����,一個學生的數據包含了數學成績����,理綜成績��,文綜成績����,和語文成績這些屬性�。我們可以關注學生的數學和理綜成績����,按照理科成績(分析能力)對學生進行聚類�����;同時也可以關注學生的文綜和語文成績��,按照文科成績(語言能力)對學生進行聚類���。
所以多維聚類的問題定義為:
如何發現數據中包含的多個側面�����,即屬性的自然分組�����,針對這些不同側面進行聚類���,從而得到多種聚類方法��。
(三)多維聚類分析的工具和原理
貝葉斯網絡是一種表示和處理隨機變量之間復雜關系的工具��。它是通過在隨機變量之間加箭頭而得到的有向無圈圖��。箭頭表示直接概率依賴關系�,具體依賴情況由條件概率分布所定量刻畫��。出于對計算復雜度的考慮�����,人們會對貝葉斯網絡進行一些限制����,在實際中使用一些特殊的網絡結構����。隱樹模型(latent tree model)是一類特殊的貝葉斯網��,也稱為多層隱類模型(hierarchical latent class model), 是一種樹狀貝葉斯網��, 其中葉節點代表觀察到的變量���,也稱為顯變量�����,其它節點代表數據中沒有觀察到的變量�,也稱為隱變量���。
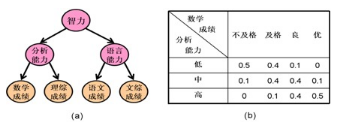
圖中給出了隱樹模型的一個例子����。其中�,學生的“數學成績”�����、“理綜成績”���、“語文成績”和“文綜成績”是顯變量�����,而“智力”���、“分析能力”和“語言能力”則是隱變量�����。從“分析能力”到“數學成績”有一個箭頭����, 表示“數學成績”直接依賴“分析能力”���,具體依賴情況由右圖中的條件概率表所定量所刻畫��。表中的內容是說�,分析能力低的學生在數學科有0.5的概率不及格��、0.4的概率及格�、0.1的概率得良��,而得優的概率則是0�; 等等���。模型中的其它箭頭代表其它變量之間直接依賴關系��,每個箭頭都有相應的條件概率分布���。
在隱樹模型中����,一個隱變量對應一種數據聚類的方法���。隱樹模型允許模型中有多個隱變量����,所以自然地可以多維同時聚類��。在例子模型中���,可以按照分析能力或者語言能力對學生聚類�����,也可以按照智力對學生聚類�。在隱樹模型中�,聚類分析可以通過計算給定學生成績的后驗概率進行判斷�����。所以�,利用隱樹模型進行多維聚類分析的技術重點就在如何通過觀測數據學習一個最優的模型���。抽象地說��,就是找到能夠最好地解釋數據的一個生成隱樹模型(Generative Latent tree model)��。
(四)隱樹模型的學習
隱樹模型的學習是一個對模型逐步優化的過程��,優化的目標函數是一個稱為貝葉斯信息準則(Bayes information criterion���, 簡稱BIC) 的函數:
BIC(m|D) = max θ log P(D|m, θ) – d(m)logN/2
BIC準則要求模型與數據盡量緊密地擬合���,但其復雜不能過高���。所以式中第一項表示擬合程度��,而第二項是對于模型復雜度的一個懲罰項�。我們的優化過程是一個基于搜索的爬山算法(Hill-Climbing)����。以只包含一個隱變量的簡單的隱樹模型作為搜索的起始模型���,在搜索的過程中����,逐步引入新的隱變量���、增加隱變量的取值個數���、或者調整變量之間的連接����。這是一個逐步修改模型的過程�,在這個過程中��,模型與數據的擬合程度不斷改進��,從而BIC分逐步增加����。當模型就變得太復雜時���,BIC會不升反降��,于是搜索過程停止�����。
隱樹模型的學習是一個非常耗時的過程����,主要原因在于對于BIC分數的計算����。BIC函數的第一項叫做最大似然函數�����,在模型包含缺失值或者隱變量時�����,計算最大似然函數需要調用EM(Expectation-Maximization)算法���。盡管我們已經對于限制了模型結構為簡單的樹狀結構����,但是在這樣的模型上進行EM的計算依然是非常困難����。圍繞隱樹模型的很多工作都是在研究如何對模型學習進行加速的���,這兒就不贅述了�。
(五)基于隱樹模型的多維聚類分析實例

我們以一個真實的數據分析實例來展現多維聚類分析���。數據來自某地區的關于貪污的社會調查問卷�。通過一些數據預處理�,我們的數據(如圖所示)包含了1200份的問卷�����,以及31個問題�。比如說C_City表示被訪問者對于該地區的貪污普遍性的看法����,可以有4個選項�����,分別是非常普遍����,普遍��,不普遍����,以及非常不普遍�。C_Gov和C_Bus分別表示受訪者對于該地區政府部門或商業部門的貪污普遍性的看法��,同樣也有四個選項�。Tolerance_C_Gov和Tolerance_C_Bus則分別表示受訪者對于該地區的政府部門以及商業部門的貪污的容忍程度�,可以選擇完全不能容忍���,不能容忍��,能容忍���,完全能容忍���。數據表里面的-1表示受訪者對該問題的回答缺失�����。
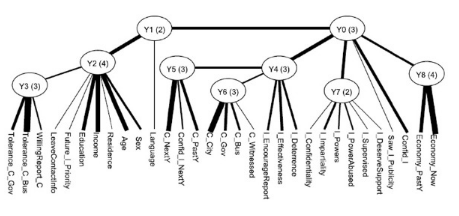
利用隱樹的學習算法�,我們從這個數據得到了一個如圖所示的模型����。葉節點對應問卷問題��,即顯變量�。中間結點����,Y0-Y8是從數據中發現的隱變量�����,括號里面的數字表示這個變量所取的狀態個數���。我們發現這些隱變量都有一定的意義���,比如�����,Y2和問卷中的Sex����,Age���,Income���,Education這些問題緊密連接�,說明Y2應該是表示受訪人的人口統計信息�����。Y3和問卷中的Tolerance_C_Gov和Tolerance_C_Bus緊密聯系��,說明Y3是反映受訪者總體對于貪污的看法�。
模型中的每個隱變量表示數據聚類的一種方式���。比如��,變量Y2有4個值����,說明Y2提示數據可以分成四個類��。這種聚類主要基于Sex�����,Age����,Income����,Education這些人口統計信息相關變量的�,所以可以說當我們關注人群的人口統計信息這個側面時�,我們可以根據Y2把人群分成四類���。具體地研究這四類的類條件概率(Class-Conditional ProbabilityDistribution)特性���,我們進一步發現它們分別代表:低收入的年輕人群�����,低收入的女性人群����,受過高等教育的高收入人群���,以及只接受初等教育的一般收入人群�。同時���,我們看到Y3有3個取值�����,這說明從人群對于貪污總體看法這個側面出發�,可以把人群分成三類���,分別是對于貪污完全不能容忍的人群����,對于貪污比較不能容忍的人群��,對于貪污可以容忍的人群��。同樣地��,我們的聚類也可以基于其他隱變量所代表的側面�。這樣從模型中我們得到了9種聚類的方法�,達到了多維同時聚類的效果��。
除了聚類��,對于這個數據的分析還告訴我們一些隱藏很深的關系��。比如在模型中變量Y2和Y3有連線�����,這表明一個人的背景信息和他對于貪污的容忍程度應該有一定的關聯關系�。具體地說�,在Y2所表示的4類人中�,你覺得哪一類是最能容忍貪污�����,而哪一類是最不能容忍貪污的呢�����?在模型中�,通過對這兩個變量的條件概率的分析���,我們得到了一個答案���,有興趣的同學可以去論文中驗證一下自己的猜測���。
(六)相關學術工作
隱樹模型在密度估計�����,近似推理及隱結構發現等方面都有具體的應用���。在多維聚類分析的應用上��,我們分析過市場學數據(COILChallenge 2000)��,某地區的社會調查數據(ICAC)�,NBA籃球運動員比賽統計數據�����。最近���,隨著算法的提速���,隱樹模型開始被嘗試用于文本分析���,比如對于網頁數據�,博客數據等的話題分析����。隱樹模型最開始的提出是為了對中醫的證候分析提供統計解釋��,有興趣的同學可以參考隱結構模型與中醫證研究���。
最近兩年�����,多維聚類分析引起了很多機器學習研究人員的興趣���。從2010年開始的MultiClust Workshop已經舉辦了兩屆��,其中第一屆是和KDD2010一起舉辦���,第二屆是和ECML/PKDD2011一起舉辦����。而第三屆也會與SDM2012一起舉辦�����。具體參考文獻這兒也不羅列了��。
多維聚類分析和基于多視圖的學習不應該混淆�����。多視圖學習假設數據的多個視圖已知�����,要求視圖之間存在充分性(Sufficiency)和冗余性(Redundancy)�����,通過協同訓練等技術��,主要提高半監督學習�,主動學習的性能�����。多視圖學習中針對聚類這樣的無監督任務的研究很少��,而且它的目標也是如何提高單一的聚類劃分的質量��,而不是找到多種劃分方法�����。多視圖學習也極少涉及如何發現多個視圖����,而不是假設他們已知���。這方面南京大學周志華教授在今年的中國機器學習及其應用研討會上提到一些初步研究��。實際中��,可以考慮先用多維聚類分析找到數據的多個側面(視圖)�,然后再應用多視圖學習的方法����。
(七)總結
對于一個復雜數據���,比如文本��,視頻����,圖像�,或者生物實驗數據��,人們可以從不同的角度去詮釋這樣的數據��。數據分析家們已經有了這樣的共識����,那就是以前的單維聚類方法不再適合大數據的多樣性特征�����。多維聚類分析通過對單維聚類問題的擴展����,為復雜數據提供了一種新的探索性分析的方式��。我們通過找到數據的不同側面�,按照這些側面進行分別聚類�����,然后把各種聚類結果全部以一種簡單的方式呈現給領域專家�,由專家決定他認為最合適的聚類方法�����。這樣的工作流程清晰定義數據科學家和領域專家的職能�����,通過兩者的合作���,提高數據的聚類結果��,并且提升數據的可解釋性���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
