2017校招正在火熱的進行�����,后面會不斷更新涉及到的相關知識點�����。
盡管聽說今年幾個大互聯網公司招的人超少��,但好像哪一年都說是就業困難���,能夠進去當然最好�,不能進去是不是應該也抱著好的期望去找自己滿意的呢�����?
最近筆試了很多家公司校招的數據分析和數據挖掘崗位�,今天(9.18r)晚上做完唯品會的筆試題���,才忽然意識過來��,不管題目簡單也好���、難也好����,都要去切切實實的去掌握��。畢竟不能永遠眼高手低�,否則最后吃虧的一定是自己��。
知識點1:貝葉斯公式
貝葉斯公式:P(B|A)=P(A|B)*P(B)/P(A)
其中P(A)可以展開為
P(A)=P(A|B1)P(B1)+P(A|B2)P(B2)+...+P(A|Bn)*P(Bn)
(這在很多問答題或者選擇題中都有用到)
知識點2:關聯規則分析
主要考的是支持度和置信度�����。
 知識點3:聚類
聚類之間類的度量是分距離和相似系數來度量的����,距離用來度量樣品之間的相似性(K-means聚類���,系統聚類中的Q型聚類)�,相似系數用來度量變量之間的相似性(系統聚類中的R型聚類)����。
最常用的是K-means聚類�,適用于大樣本���,但需要事先指定分為K個類�����。
處理步驟:
1)��、從n個數據對象中任意選出k個對象作為初始的聚類中心
2)����、計算剩余的各個對象到聚類中心的距離��,將它劃分給最近的簇
3)�����、重新計算每一簇的平均值(中心對象)
4)�����、循環2-3直到每個聚類不再發生變化為止����。
系統聚類適用于小樣本�。
知識點4:分類
有監督就是給的樣本都有標簽��,分類的訓練樣本必須有標簽���,所以分類算法都是有監督算法��。
監督機器學習問題無非就是“minimizeyour error while regularizing your parameters”����,也就是在規則化參數的同時最小化誤差��。最小化誤差是為了讓我們的模型擬合我們的訓練數據���,而規則化參數是防止我們的模型過分擬合我們的訓練數據���,提高泛化能力�。
1.樸素貝葉斯
1)基礎思想:
對于給出的待分類項�����,求解在此項出現的條件下各個類別出現的概率�����,哪個最大��,就認為此分類項屬于哪個類別���。
2)優點:
可以和決策樹�、神經網絡分類算法相媲美�,能運用于大型數據庫中����。
方法簡單����,分類準確率高���,速度快����,所需估計的參數少��,對于缺失數據不敏感����。
3)缺點:
假設一個屬性對定類的影響獨立于其他的屬性值��,這往往并不成立���。(喜歡吃番茄��、雞蛋�,卻不喜歡吃番茄炒蛋)�����。
需要知道先驗概率��。
2.決策樹
1)基礎思想:
決策樹是一種簡單但廣泛使用的分類器���,它通過訓練數據構建決策樹�,對未知的數據進行分類�。決策樹的每個內部節點表示在一個屬性上的測試����,每個分枝代表該測試的一個輸出�����,而每個葉結點存放著一個類標號��。
在決策樹算法中���,ID3基于信息增益作為屬性選擇的度量�����,C4.5基于信息增益比作為屬性選擇的度量���,CART基于基尼指數作為屬性選擇的度量��。
2)優點 :
不需要任何領域知識或參數假設����。
適合高維數據�����。
簡單易于理解���。
短時間內處理大量數據��,得到可行且效果較好的結果�����。
3)缺點:
對于各類別樣本數量不一致數據��,信息增益偏向于那些具有更多數值的特征�。
易于過擬合���。
忽略屬性之間的相關性���。
3.支持向量機
1)基礎思想:
支持向量機把分類問題轉化為尋找分類平面的問題���,并通過最大化分類邊界點距離分類平面的距離來實現分類����。
2)優點 :
可以解決小樣本下機器學習的問題��。
提高泛化性能����。
可以解決文本分類�����、文字識別�����、圖像分類等方面仍受歡迎����。
避免神經網絡結構選擇和局部極小的問題���。
3)缺點:
缺失數據敏感�。
內存消耗大����,難以解釋�����。
4.K近鄰
1)基礎思想:
通過計算每個訓練樣例到待分類樣品的距離�����,取和待分類樣品距離最近的K個訓練樣例��,K個樣品中哪個類別的訓練樣例占多數����,則待分類樣品就屬于哪個類別���。
2)優點 :
適用于樣本容量比較大的分類問題
3)缺點:
計算量太大
對于樣本量較小的分類問題�����,會產生誤分�。
5.邏輯回歸(LR)
1)基礎思想:
回歸模型中��,y是一個定型變量�����,比如y=0或1��,logistic方法主要應用于研究某些事件發生的概率�。
2)優點 :
速度快���,適合二分類問題�����。
簡單易于理解����,直接看到各個特征的權重�����。
能容易地更新模型吸收新的數據�。
3)缺點:
對數據和場景的適應能力有局限��,不如決策樹算法適應性那么強
知識點5:分類的評判指標
準確率和召回率廣泛用于信息檢索和統計分類領域
1)準確率(precision rate):提取出的正確信息條數/提取出的信息條數
2)召回率(recall rate):提取出的正確信息條數/樣本中的信息條數
知識點3:聚類
聚類之間類的度量是分距離和相似系數來度量的����,距離用來度量樣品之間的相似性(K-means聚類���,系統聚類中的Q型聚類)�,相似系數用來度量變量之間的相似性(系統聚類中的R型聚類)����。
最常用的是K-means聚類�,適用于大樣本���,但需要事先指定分為K個類�����。
處理步驟:
1)��、從n個數據對象中任意選出k個對象作為初始的聚類中心
2)����、計算剩余的各個對象到聚類中心的距離��,將它劃分給最近的簇
3)�����、重新計算每一簇的平均值(中心對象)
4)�����、循環2-3直到每個聚類不再發生變化為止����。
系統聚類適用于小樣本�。
知識點4:分類
有監督就是給的樣本都有標簽��,分類的訓練樣本必須有標簽���,所以分類算法都是有監督算法��。
監督機器學習問題無非就是“minimizeyour error while regularizing your parameters”����,也就是在規則化參數的同時最小化誤差��。最小化誤差是為了讓我們的模型擬合我們的訓練數據���,而規則化參數是防止我們的模型過分擬合我們的訓練數據���,提高泛化能力�。
1.樸素貝葉斯
1)基礎思想:
對于給出的待分類項�����,求解在此項出現的條件下各個類別出現的概率�����,哪個最大��,就認為此分類項屬于哪個類別���。
2)優點:
可以和決策樹�、神經網絡分類算法相媲美�,能運用于大型數據庫中����。
方法簡單����,分類準確率高���,速度快����,所需估計的參數少��,對于缺失數據不敏感����。
3)缺點:
假設一個屬性對定類的影響獨立于其他的屬性值��,這往往并不成立���。(喜歡吃番茄��、雞蛋�,卻不喜歡吃番茄炒蛋)�����。
需要知道先驗概率��。
2.決策樹
1)基礎思想:
決策樹是一種簡單但廣泛使用的分類器���,它通過訓練數據構建決策樹�,對未知的數據進行分類�。決策樹的每個內部節點表示在一個屬性上的測試����,每個分枝代表該測試的一個輸出�����,而每個葉結點存放著一個類標號��。
在決策樹算法中���,ID3基于信息增益作為屬性選擇的度量�����,C4.5基于信息增益比作為屬性選擇的度量���,CART基于基尼指數作為屬性選擇的度量��。
2)優點 :
不需要任何領域知識或參數假設����。
適合高維數據�����。
簡單易于理解���。
短時間內處理大量數據��,得到可行且效果較好的結果�����。
3)缺點:
對于各類別樣本數量不一致數據��,信息增益偏向于那些具有更多數值的特征�。
易于過擬合���。
忽略屬性之間的相關性���。
3.支持向量機
1)基礎思想:
支持向量機把分類問題轉化為尋找分類平面的問題���,并通過最大化分類邊界點距離分類平面的距離來實現分類����。
2)優點 :
可以解決小樣本下機器學習的問題��。
提高泛化性能����。
可以解決文本分類�����、文字識別�����、圖像分類等方面仍受歡迎����。
避免神經網絡結構選擇和局部極小的問題���。
3)缺點:
缺失數據敏感�。
內存消耗大����,難以解釋�����。
4.K近鄰
1)基礎思想:
通過計算每個訓練樣例到待分類樣品的距離�����,取和待分類樣品距離最近的K個訓練樣例��,K個樣品中哪個類別的訓練樣例占多數����,則待分類樣品就屬于哪個類別���。
2)優點 :
適用于樣本容量比較大的分類問題
3)缺點:
計算量太大
對于樣本量較小的分類問題�����,會產生誤分�。
5.邏輯回歸(LR)
1)基礎思想:
回歸模型中��,y是一個定型變量�����,比如y=0或1��,logistic方法主要應用于研究某些事件發生的概率�。
2)優點 :
速度快���,適合二分類問題�����。
簡單易于理解����,直接看到各個特征的權重�����。
能容易地更新模型吸收新的數據�。
3)缺點:
對數據和場景的適應能力有局限��,不如決策樹算法適應性那么強
知識點5:分類的評判指標
準確率和召回率廣泛用于信息檢索和統計分類領域
1)準確率(precision rate):提取出的正確信息條數/提取出的信息條數
2)召回率(recall rate):提取出的正確信息條數/樣本中的信息條數
 ROC和AUC是評價分類器的指標
3)ROC曲線:
ROC關注兩個指標
True Positive Rate ( TPR�����,真正率 ) = TP / [ TP + FN] ���,TPR代表預測為正實際也為正占總正實例的比例
False Positive Rate( FPR����,假正率 ) = FP / [ FP + TN] ���,FPR代表預測為正但實際為負占總負實例的比例
在ROC 空間中�,每個點的橫坐標是FPR����,縱坐標是TPR
4)AUC:AUC(Area Under Curve)
被定義為ROC曲線下的面積�,顯然這個面積的數值不會大于1���。又由于ROC曲線一般都處于y=x這條直線的上方����,所以AUC的取值范圍在0.5和1之間�����。使用AUC值作為評價標準是因為很多時候ROC曲線并不能清晰的說明哪個分類器的效果更好�����,而AUC作為數值可以直觀的評價分類器的好壞��,值越大越好����。
5)如何避免過擬合�?
過擬合表現在訓練數據上的誤差非常小�,而在測試數據上誤差反而增大��。其原因一般是模型過于復雜���,過分得去擬合數據的噪聲和outliers����。
常見的解決辦法是正則化是:增大數據集�����,正則化
正則化方法是指在進行目標函數或代價函數優化時�����,在目標函數或代價函數后面加上一個正則項�����,一般有L1正則與L2正則等��。規則化項的引入�,在訓練(最小化cost)的過程中�,當某一維的特征所對應的權重過大時��,而此時模型的預測和真實數據之間距離很小����,通過規則化項就可以使整體的cost取較大的值��,從而在訓練的過程中避免了去選擇那些某一維(或幾維)特征的權重過大的情況��,即過分依賴某一維(或幾維)的特征�。
L1正則與L2正則區別:
L1:計算絕對值之和��,用以產生稀疏性(使參數矩陣中大部分元素變為0)�����,因為它是L0范式的一個最優凸近似��,容易優化求解�;
L2:計算平方和再開根號����,L2范數更多是防止過擬合����,并且讓優化求解變得穩定很快速��;
所以優先使用L2 norm是比較好的選擇�����。
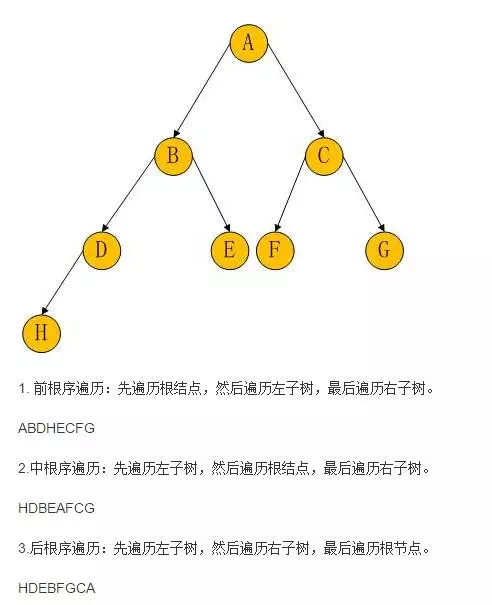
知識點6:二叉樹(前�����、中�����、后遍歷)
(這里的前中后是指的根節點的遍歷次序)
1)前序遍歷(DLR)��,首先訪問根結點�����,然后遍歷左子樹�,最后遍歷右子樹�;
2)中序遍歷(LDR)�,首先遍歷左子樹����,然后訪問根結點����,最后遍歷右子樹�����;
3)后序遍歷(LRD)�,首先遍歷左子樹�,然后訪問遍歷右子樹���,最后訪問根結點�。
ROC和AUC是評價分類器的指標
3)ROC曲線:
ROC關注兩個指標
True Positive Rate ( TPR�����,真正率 ) = TP / [ TP + FN] ���,TPR代表預測為正實際也為正占總正實例的比例
False Positive Rate( FPR����,假正率 ) = FP / [ FP + TN] ���,FPR代表預測為正但實際為負占總負實例的比例
在ROC 空間中�,每個點的橫坐標是FPR����,縱坐標是TPR
4)AUC:AUC(Area Under Curve)
被定義為ROC曲線下的面積�,顯然這個面積的數值不會大于1���。又由于ROC曲線一般都處于y=x這條直線的上方����,所以AUC的取值范圍在0.5和1之間�����。使用AUC值作為評價標準是因為很多時候ROC曲線并不能清晰的說明哪個分類器的效果更好�����,而AUC作為數值可以直觀的評價分類器的好壞��,值越大越好����。
5)如何避免過擬合�?
過擬合表現在訓練數據上的誤差非常小�,而在測試數據上誤差反而增大��。其原因一般是模型過于復雜���,過分得去擬合數據的噪聲和outliers����。
常見的解決辦法是正則化是:增大數據集�����,正則化
正則化方法是指在進行目標函數或代價函數優化時�����,在目標函數或代價函數后面加上一個正則項�����,一般有L1正則與L2正則等��。規則化項的引入�,在訓練(最小化cost)的過程中�,當某一維的特征所對應的權重過大時��,而此時模型的預測和真實數據之間距離很小����,通過規則化項就可以使整體的cost取較大的值��,從而在訓練的過程中避免了去選擇那些某一維(或幾維)特征的權重過大的情況��,即過分依賴某一維(或幾維)的特征�。
L1正則與L2正則區別:
L1:計算絕對值之和��,用以產生稀疏性(使參數矩陣中大部分元素變為0)�����,因為它是L0范式的一個最優凸近似��,容易優化求解�;
L2:計算平方和再開根號����,L2范數更多是防止過擬合����,并且讓優化求解變得穩定很快速��;
所以優先使用L2 norm是比較好的選擇�����。
知識點6:二叉樹(前�����、中�����、后遍歷)
(這里的前中后是指的根節點的遍歷次序)
1)前序遍歷(DLR)��,首先訪問根結點�����,然后遍歷左子樹�,最后遍歷右子樹�;
2)中序遍歷(LDR)�,首先遍歷左子樹����,然后訪問根結點����,最后遍歷右子樹�����;
3)后序遍歷(LRD)�,首先遍歷左子樹�,然后訪問遍歷右子樹���,最后訪問根結點�。
 知識點7:幾種基本排序算法
1)冒泡排序(Bubble Sort)
冒泡排序方法是最簡單的排序方法���。這種方法的基本思想是����,將待排序的元素看作是豎著排列的“氣泡”�����,較小的元素比較輕��,從而要往上浮�。
冒泡排序是穩定的����。算法時間復雜度是O(n^2)����。
2)插入排序(Insertion Sort)
插入排序的基本思想是��,經過i-1遍處理后��,L[1..i-1]己排好序�。第i遍處理僅將L[i]插入L[1..i-1]的適當位置���,使得L[1..i]又是排好序的序列�����。
直接插入排序是穩定的�。算法時間復雜度是O(n^2)�����。
3)堆排序
堆排序是一種樹形選擇排序�����,在排序過程中��,將A[n]看成是完全二叉樹的順序存儲結構�����,利用完全二叉樹中雙親結點和孩子結點之間的內在關系來選擇最小的元素���。
堆排序是不穩定的��。算法時間復雜度O(nlog n)�。
4)快速排序
快速排序是對冒泡排序的一種本質改進���?����?焖倥判蛲ㄟ^一趟掃描�,就能確保某個數(以它為基準點吧)的左邊各數都比它小�����,右邊各數都比它大�。
快速排序是不穩定的��。最理想情況算法時間復雜度O(nlog2n)�,最壞O(n ^2)����。
知識點8:SQL知識
1)左連接��、右連接����、inner連接�,full連接
2)修改表:
alter table 教師 add 獎金 int
alter table 教師 drop 獎金
alter table 教師 rename 獎金 to 津貼
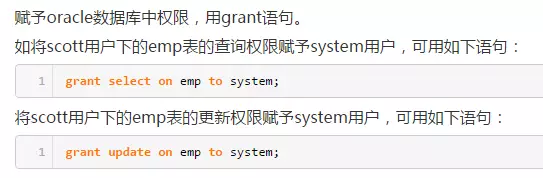
3)表權限的賦予:
知識點7:幾種基本排序算法
1)冒泡排序(Bubble Sort)
冒泡排序方法是最簡單的排序方法���。這種方法的基本思想是����,將待排序的元素看作是豎著排列的“氣泡”�����,較小的元素比較輕��,從而要往上浮�。
冒泡排序是穩定的����。算法時間復雜度是O(n^2)����。
2)插入排序(Insertion Sort)
插入排序的基本思想是��,經過i-1遍處理后��,L[1..i-1]己排好序�。第i遍處理僅將L[i]插入L[1..i-1]的適當位置���,使得L[1..i]又是排好序的序列�����。
直接插入排序是穩定的�。算法時間復雜度是O(n^2)�����。
3)堆排序
堆排序是一種樹形選擇排序�����,在排序過程中��,將A[n]看成是完全二叉樹的順序存儲結構�����,利用完全二叉樹中雙親結點和孩子結點之間的內在關系來選擇最小的元素���。
堆排序是不穩定的��。算法時間復雜度O(nlog n)�。
4)快速排序
快速排序是對冒泡排序的一種本質改進���?����?焖倥判蛲ㄟ^一趟掃描�,就能確保某個數(以它為基準點吧)的左邊各數都比它小�����,右邊各數都比它大�。
快速排序是不穩定的��。最理想情況算法時間復雜度O(nlog2n)�,最壞O(n ^2)����。
知識點8:SQL知識
1)左連接��、右連接����、inner連接�,full連接
2)修改表:
alter table 教師 add 獎金 int
alter table 教師 drop 獎金
alter table 教師 rename 獎金 to 津貼
3)表權限的賦予:
 4)怎樣清空表數據�����,但不刪除表結構
delete from tablename或者delete * from table_name
truncate table tablename
5)外鍵能不能為空
外鍵可以為空�,為空表示其值還沒有確定��;
如果不為空��,剛必須為主鍵相同�。
知識點9:統計學基礎知識
1)四分位極差����、左右偏分布����、p值
2)方差分析:
用于兩個及兩個以上樣本均數差別的顯著性檢驗����,基本思想是:通過分析研究不同來源的變異對總變異的貢獻大小�,從而確定控制變量對研究結果影響力的大小���。
3)主成分分析:
是一種統計方法�����。通過正交變換將一組可能存在相關性的變量轉換為一組線性不相關的變量���,轉換后的這組變量叫主成分���。
4)幸存者偏差:
意思是指��,當取得資訊的渠道�,僅來自于幸存者時(因為死人不會說話)���,此資訊可能會存在與實際情況不同的偏差���。
4)怎樣清空表數據�����,但不刪除表結構
delete from tablename或者delete * from table_name
truncate table tablename
5)外鍵能不能為空
外鍵可以為空�,為空表示其值還沒有確定��;
如果不為空��,剛必須為主鍵相同�。
知識點9:統計學基礎知識
1)四分位極差����、左右偏分布����、p值
2)方差分析:
用于兩個及兩個以上樣本均數差別的顯著性檢驗����,基本思想是:通過分析研究不同來源的變異對總變異的貢獻大小�,從而確定控制變量對研究結果影響力的大小���。
3)主成分分析:
是一種統計方法�����。通過正交變換將一組可能存在相關性的變量轉換為一組線性不相關的變量���,轉換后的這組變量叫主成分���。
4)幸存者偏差:
意思是指��,當取得資訊的渠道�,僅來自于幸存者時(因為死人不會說話)���,此資訊可能會存在與實際情況不同的偏差���。
本文為簡書作者是藍先生原創��,CDA數據分析師已獲得授權
CDA數據分析師課程��,全面講解商業數據分析領域技能和應用��,歡迎參加���!

CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
