多元線性回歸實戰筆記
R語言中的線性回歸函數比較簡單�,就是lm()��,比較復雜的是對線性模型的診斷和調整�。這里結合Statistical Learning和杜克大學的Data Analysis and Statistical Inference的章節以及《R語言實戰》的OLS(Ordinary Least Square)回歸模型章節來總結一下�,診斷多元線性回歸模型的操作分析步驟�����。
1�����、選擇預測變量
因變量比較容易確定���,多元回歸模型中難在自變量的選擇��。自變量選擇主要可分為向前選擇(逐次加使RSS最小的自變量)�,向后選擇(逐次扔掉p值最大的變量)���。個人傾向于向后選擇法���,一來p值比較直觀���,模型返回結果直接給出了各變量的p值��,卻沒有直接給出RSS����;二來當自變量比較多時����,一個個加比較麻煩����。
-
Call:
-
lm(formula=Sales~.+Income:Advertising+Age:Price,data=Carseats)
-
-
Residuals:
-
Min1QMedian3QMax
-
-2.9208-0.75030.01770.67543.3413
-
-
Coefficients:
-
EstimateStd.Errort valuePr(>|t|)
-
(Intercept)6.57556541.00874706.5192.22e-10***
-
CompPrice0.09293710.004118322.567<2e-16***
-
Income0.01089400.00260444.1833.57e-05***
-
Advertising0.07024620.02260913.1070.002030**
-
Population0.00015920.00036790.4330.665330
-
Price-0.10080640.0074399-13.549<2e-16***
-
ShelveLocGood4.84867620.152837831.724<2e-16***
-
ShelveLocMedium1.95326200.125768215.531<2e-16***
-
Age-0.05794660.0159506-3.6330.000318***
-
Education-0.02085250.0196131-1.0630.288361
-
UrbanYes0.14015970.11240191.2470.213171
-
USYes-0.15755710.1489234-1.0580.290729
-
Income:Advertising0.00075100.00027842.6980.007290**
-
Price:Age0.00010680.00013330.8010.423812
-
---
-
Signif.codes:0‘***’0.001‘**’0.01‘*’0.05‘.’0.1‘’1
-
-
Residualstandard error:1.011on386degrees of freedom
-
MultipleR-squared:0.8761,AdjustedR-squared:0.8719
-
F-statistic:210on13and386DF,p-value:<2.2e-16
構建一個回歸模型后�����,先看F統計量的p值�,這是對整個模型的假設檢驗���,原假設是各系數都為0��,如果連這個p值都不顯著���,無法證明至少有一個自變量對因變量有顯著性影響���,這個模型便不成立���。然后看Adjusted R2��,每調整一次模型����,應該力使它變大�����;Adjusted R2越大說明模型中相關的自變量對因變量可解釋的變異比例越大��,模型的預測性就越好���。
構建了線性模型后����,如果是一元線性回歸���,可以畫模型圖初步判斷一下線性關系(多元回歸模型不好可視化):
-
par(mfrow=c(1,1))
-
plot(medv~lstat,Boston)
-
fit1=lm(medv~lstat,data=Boston)
-
abline(fit1,col="red")

2�、模型診斷
確定了回歸模型的自變量并初步得到一個線性回歸模型����,并不是直接可以拿來用的��,還要進行驗證和診斷��。診斷之前���,先回顧多元線性回歸模型的假設前提(by Data Analysis and Statistical Inference):
-
(數值型)自變量要與因變量有線性關系����;
-
殘差基本呈正態分布���;
-
殘差方差基本不變(同方差性)����;
-
殘差(樣本)間相關獨立�。
一個好的多元線性回歸模型應當盡量滿足這4點假設前提�。
用lm()構造一個線性模型fit后���,plot(fit)即可返回4張圖(可以par(mfrow=c(2,2))一次展現)���,這4張圖可作初步檢驗:

左上圖用來檢驗假設1��,如果散點看不出什么規律�����,則表示線性關系良好����,若有明顯關系�,則說明非線性關系明顯�。右上圖用來檢驗假設2��,若散點大致都集中在QQ圖中的直線上����,則說明殘差正態性良好���。左下圖用來檢驗假設3��,若點在曲線周圍隨機分布����,則可認為假設3成立����;若散點呈明顯規律���,比如方差隨均值而增大�����,則越往右的散點上下間距會越大���,方差差異就越明顯�����。假設4的獨立性無法通過這幾張圖來檢驗�,只能通過數據本身的來源的意義去判斷����。
右下圖是用來檢驗異常值��。異常值與三個概念有關:
離群點:y遠離散點主體區域的點
杠桿點:x遠離散點主體區域的點��,一般不影響回歸直線的斜率
強影響點:影響回歸直線的斜率��,一般是高杠桿點���。
對于多元線性回歸�,高杠桿點不一定就是極端點��,有可能是各個變量的取值都正常��,但仍然偏離散點主體����。
對于異常值����,可以謹慎地刪除��,看新的模型是否效果更好��。
《R語言實戰》里推薦了更好的診斷方法����,總結如下��。
(1)多元線性回歸假設驗證:
gvlma包的gvlma()函數可對擬合模型的假設作綜合驗證��,并對峰度���、偏度進行驗證���。
-
states<-as.data.frame(state.x77[,c("Murder","Population",
-
"Illiteracy","Income","Frost")])
-
fit<-lm(Murder~Population+Illiteracy+Income+
-
Frost,data=states)
-
library(gvlma)
-
gvmodel<-gvlma(fit)
-
summary(gvmodel)
-
-
Call:
-
lm(formula=Murder~Population+Illiteracy+Income+Frost,data=states)
-
-
Residuals:
-
Min1QMedian3QMax
-
-4.7960-1.6495-0.08111.48157.6210
-
-
Coefficients:
-
EstimateStd.Errort valuePr(>|t|)
-
(Intercept)1.235e+003.866e+000.3190.7510
-
Population2.237e-049.052e-052.4710.0173*
-
Illiteracy4.143e+008.744e-014.7382.19e-05***
-
Income6.442e-056.837e-040.0940.9253
-
Frost5.813e-041.005e-020.0580.9541
-
---
-
Signif.codes:0‘***’0.001‘**’0.01‘*’0.05‘.’0.1‘’1
-
-
Residualstandard error:2.535on45degrees of freedom
-
MultipleR-squared:0.567,AdjustedR-squared:0.5285
-
F-statistic:14.73on4and45DF,p-value:9.133e-08
-
-
-
ASSESSMENT OF THE LINEAR MODEL ASSUMPTIONS
-
USING THE GLOBAL TEST ON4DEGREES-OF-FREEDOM:
-
LevelofSignificance=0.05
-
-
Call:
-
gvlma(x=fit)
-
-
Valuep-valueDecision
-
GlobalStat2.77280.5965Assumptionsacceptable.
-
Skewness1.53740.2150Assumptionsacceptable.
-
Kurtosis0.63760.4246Assumptionsacceptable.
-
LinkFunction0.11540.7341Assumptionsacceptable.
-
Heteroscedasticity0.48240.4873Assumptionsacceptable.
最后的Global Stat是對4個假設條件進行綜合驗證���,通過了即表示4個假設驗證都通過了���。最后的Heterosceasticity是進行異方差檢測����。注意這里假設檢驗的原假設都是假設成立��,所以當p>0.05時�,假設才能能過驗證����。
如果綜合驗證不通過����,也有其他方法對4個假設條件分別驗證:
線性假設
library(car)
crPlots(fit)
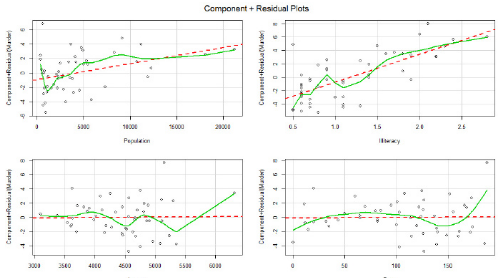
返回的圖是各個自變量與殘差(因變量)的線性關系圖����,若存著明顯的非線性關系�,則需要對自變量作非線性轉化���。書中說這張圖表明線性關系良好�����。
正態性
-
library(car)
-
qqPlot(fit,labels=row.names(states),id.method="identify",simulate=TRUE,main="Q-Q Plot")
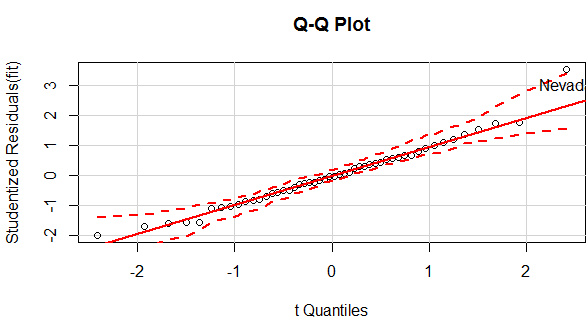
qqPlot()可以生成交互式的qq圖��,選中異常點���,就返回該點的名稱���。該圖中除了Nevad點����,其他點都在直線附近�����,可見正態性良好���。
同方差性
-
library(car)
-
ncvTest(fit)
-
-
Non-constantVarianceScoreTest
-
Varianceformula:~fitted.values
-
Chisquare=1.746514Df=1p=0.1863156
p值大于0.05�,可認為滿足方差相同的假設�。
獨立性
-
library(car)
-
durbinWatsonTest(fit)
-
-
lagAutocorrelationD-WStatisticp-value
-
1-0.20069292.3176910.258
-
Alternativehypothesis:rho!=0
p值大于0.05��,可認為誤差之間相互獨立���。
除了以上4點基本假設���,還有其他方面需要進行診斷����。
(2)多重共線性
理想中的線性模型各個自變量應該是線性無關的����,若自變量間存在共線性����,則會降低回歸系數的準確性����。一般用方差膨脹因子VIF(Variance Inflation Factor)來衡量共線性����,《統計學習》中認為VIF超過5或10就存在共線性�,《R語言實戰》中認為VIF大于4則存在共線性����。理想中的線性模型VIF=1����,表完全不存在共線性���。
-
library(car)
-
vif(fit)
-
-
PopulationIlliteracyIncomeFrost
-
1.2452822.1658481.3458222.082547
可見這4個自變量VIF都比較小��,可認為不存在多重共線性的問題����。
(3)異常值檢驗
離群點
離群點有三種判斷方法:一是用qqPlot()畫QQ圖���,落在置信區間(上圖中兩條虛線)外的即可認為是離群點�����,如上圖中的Nevad點�����;一種是判斷學生標準化殘差值�,絕對值大于2(《R語言實戰》中認為2���,《統計學習》中認為3)的可認為是離群點���。
plot(x=fitted(fit),y=rstudent(fit))
abline(h=3,col="red",lty=2)
abline(h=-3,col="red",lty=2)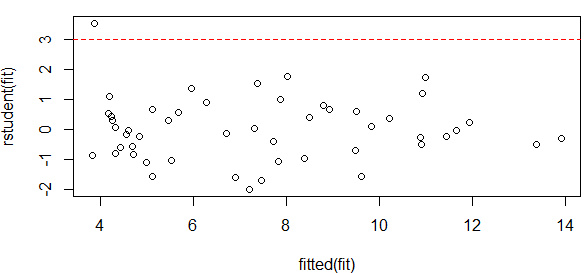
-
which(abs(rstudent(fit))>3)
-
Nevada
-
28
還有一種方法是利用car包里的outlierTest()函數進行假設檢驗:
-
library(car)
-
outlierTest(fit)
-
-
rstudent unadjusted p-valueBonferonnip
-
Nevada3.5429290.000950880.047544
這個函數用來檢驗最大的標準化殘差值�����,如果p>0.05�,可以認為沒有離群點����;若p<0.05���,則該點是離群點�,但不能說明只有一個離群點�,可以把這個點刪除之后再作檢驗��。第三種方法可以與第二種方法結合起來使用�����。
高杠桿點
高杠桿值觀測點���,即是與其他預測變量有關的離群點�。換句話說�����,它們是由許多異常的預測變量值組合起來的�����,與響應變量值沒有關系����?���!督y計學習》中給出了一個杠桿統計量���,《R語言實戰》中給出了一種具體的操作方法���。(兩本書也稍有出入���,《統計學習》中平均杠桿值為(p+1)/n�����,而在《R語言實戰》中平均杠桿值為p/n����;事實上在樣本量n比較大時�,幾乎沒有差別���。)
-
hat.plot<-function(fit){
-
p<-length(coefficients(fit))
-
n<-length(fitted(fit))
-
plot(hatvalues(fit),main="Index Plot of Hat Values")
-
abline(h=c(2,3)*p/n,col="red",lty=2)
-
identify(1:n,hatvalues(fit),names(hatvalues(fit)))
-
#這句產生交互效果����,選中某個點后�,關閉后返回點的名稱
-
}
-
hat.plot(fit)
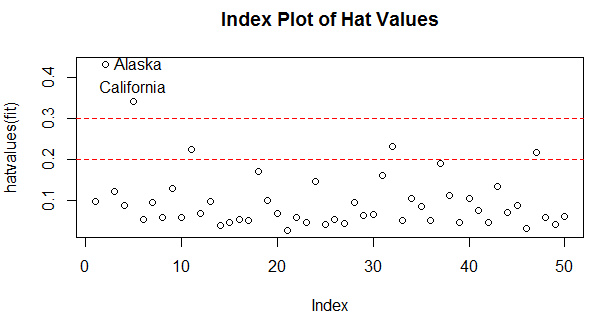
超過2倍或3倍的平均杠桿值即可認為是高杠桿點�����,這里把Alaska和California作為高杠桿點��。
強影響點
強影響點是那種若刪除則模型的系數會產生明顯的變化的點����。一種方法是計算Cook距離�,一般來說���, Cook’s D值大于4/(n-k -1)�,則表明它是強影響點�����,其中n 為樣本量大小�, k 是預測變量數目�����。
-
cutoff<-4/(nrow(states-length(fit$coefficients)-2))
-
#coefficients加上了截距項�,因此要多減1
-
plot(fit,which=4,cook.levels=cutoff)
-
abline(h=cutoff,lty=2,col="red")
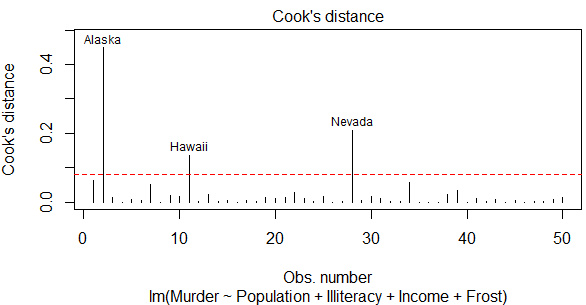
實際上這就是前面診斷的4張圖之一�,語句還是plot(fit)�����,which=4表示指定第4張圖�,cook.levels可設定標準值����。紅色虛線以上就返回了強影響點��。
car包里的influencePlot()函數能一次性同時檢查離群點����、高杠桿點��、強影響點�����。
-
library(car)
-
influencePlot(fit,id.method="identity",main="Influence Plot",sub="Circle size is proportional to Cook's distance")
-
-
StudResHatCookD
-
Alaska1.7536920.432473190.4480510
-
Nevada3.5429290.095089770.2099157

縱坐標超過+2或小于-2的點可被認為是離群點��,水平軸超過0.2或0.3的州有高杠桿值(通常為預測值的組合)����。圓圈大小與影響成比例���,圓圈很大的點可能是對模型參數的估計造成的不成比例影響的強影響點��。
3����、模型調整
到目前為止��,《統計學習》中提到的多元線性回歸模型潛在的問題��,包括4個假設不成立�����、異常值��、共線性的診斷方法在上面已經全部得到解決���。這里總結�����、延伸《R語言實戰》里提到的調整方法——
刪除觀測點
對于異常值一個最簡單粗暴又高效的方法就是直接刪除�����,不過有兩點要注意�����。一是當數據量大的時候可以這么做�����,若數據量較小則應慎重�����;二是根據數據的意義判斷�����,若明顯就是錯誤就可以直接刪除�����,否則需判斷是否會隱藏著深層的現象����。
另外刪除觀測點后要與刪除之前的模型作比較�����,看模型是否變得更好���。
變量變換

在進行非線性變換之前�,先看看4個假設是否成立�,如果成立可以不用變換��;沒必要追求更好的擬合效果而把模型搞得太復雜�,這有可能出現過擬合現象�。如果連假設檢驗都不通過����,可以通過變量變換來調整模型�。這里只討論線性關系不佳的情況���,其他情況遇到了再說���。
(1)多項式回歸
如果殘差圖中呈現明顯的非線性關系����,可以考慮對自變量進行多項式回歸���。舉一個例子:
-
library(MASS)
-
library(ISLR)
-
fit1=lm(medv~lstat,data=Boston)
-
plot(fit1,which=1)
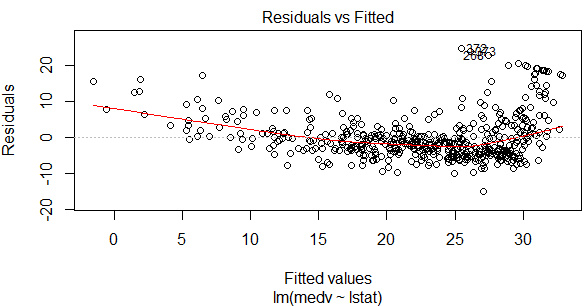
可以看到這個一元線性回歸模型的殘差圖中��,散點的規律還是比較明顯���,說明線性關系較弱�。
-
fit1_1<-lm(medv~poly(lstat,2),data=Boston)
-
plot(fit1_1,which=1)

將自變量進行2次多項式回歸后��,發現現在的殘差圖好多了���,散點基本無規律����,線性關系較明顯��。
再看看兩個模型的整體效果——
-
summary(fit1)

-
summary(fit1_1)

可見多項式回歸的模型Adjusted R2也增大了��,模型的解釋性也變強了��。
多項式回歸在《統計學習》后面的非線性模型中還會提到�����,到時候再討論�。
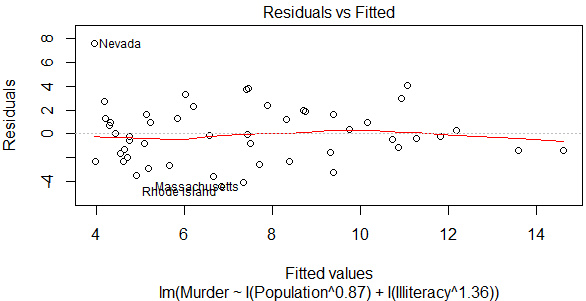
(2)Box-Tidwell變換
car包中的boxTidwell() 函數通過獲得預測變量冪數的最大似然估計來改善線性關系���。
-
library(car)
-
boxTidwell(Murder~Population+Illiteracy,data=states)
-
-
ScoreStatisticp-value MLE oflambda
-
Population-0.32280030.74684650.8693882
-
Illiteracy0.61938140.53566511.3581188
-
-
iterations=19
-
#這里看lambda�,表示各個變量的冪次數
-
lmfit<-lm(Murder~Population+Illiteracy,data=states)
-
lmfit2<-lm(Murder~I(Population^0.87)+I(Illiteracy^1.36),data=states)
-
plot(lmfit,which=1)
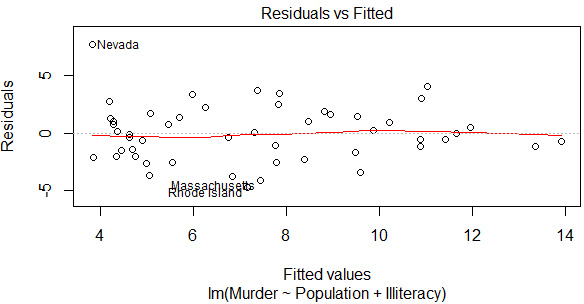
-
plot(lmfit2,which=1)
-
summary(lmfit)

-
summary(lmfit2)

可以發現殘差圖和Adjusted R2的提升都甚微���,因此沒有必要作非線性轉換�����。
4�����、模型分析
(1)模型比較
前面只是簡單得用Adjusted R2來比較模型�,《R語言實戰》里介紹了可以用方差分析來比較嵌套模型(即它的一些項完全包含在另一個模型中)有沒有顯著性差異����。方差分析的思想是:如果線性模型y~x1+x2+x3與y~x1+x2沒有顯著性差異���,若同時x3變量對模型也不顯著�����,那就沒必要加上變量x3���。下面進行試驗:
-
aovfit1<-lm(Murder~Population+Illiteracy+Income+Frost,data=states)
-
aovfit2<-lm(Murder~Population+Illiteracy,data=states)
-
anova(aovfit1,aovfit2)
-
-
AnalysisofVarianceTable
-
-
Model1:Murder~Population+Illiteracy+Income+Frost
-
Model2:Murder~Population+Illiteracy
-
Res.DfRSSDfSumofSqFPr(>F)
-
145289.17
-
247289.25-2-0.0785050.00610.9939
-
-
summary(aovfit1)
-
-
Coefficients:
-
EstimateStd.Errort valuePr(>|t|)
-
(Intercept)1.235e+003.866e+000.3190.7510
-
Population2.237e-049.052e-052.4710.0173*
-
Illiteracy4.143e+008.744e-014.7382.19e-05***
-
Income6.442e-056.837e-040.0940.9253
-
Frost5.813e-041.005e-020.0580.9541
-
-
Residualstandard error:2.535on45degrees of freedom
-
MultipleR-squared:0.567,AdjustedR-squared:0.5285
-
F-statistic:14.73on4and45DF,p-value:9.133e-08
-
-
summary(aovfit2)
-
-
Coefficients:
-
EstimateStd.Errort valuePr(>|t|)
-
(Intercept)1.652e+008.101e-012.0390.04713*
-
Population2.242e-047.984e-052.8080.00724**
-
Illiteracy4.081e+005.848e-016.9788.83e-09***
-
-
Residualstandard error:2.481on47degrees of freedom
-
MultipleR-squared:0.5668,AdjustedR-squared:0.5484
-
F-statistic:30.75on2and47DF,p-value:2.893e-09
Income和Frost兩個變量不顯著��,兩個模型之間沒有顯著性差異�����,就可以不加這兩個變量����。刪去這兩個不顯著的變量后����,R2略微減少���,Adjusted R2增大����,這也符合二者的定義���。
《R語言實戰》里還介紹到了用AIC(Akaike Information Criterion����,赤池信息準則)值來比較模型�����,AIC值越小的模型優先選擇��,原理不明��。
-
aovfit1<-lm(Murder~Population+Illiteracy+Income+Frost,data=states)
-
aovfit2<-lm(Murder~Population+Illiteracy,data=states)
-
AIC(aovfit1,aovfit2)
-
-
df AIC
-
aovfit16241.6429
-
aovfit24237.6565
第二個模型AIC值更小���,因此選第二個模型(真是簡單粗暴)����。注:ANOVA需限定嵌套模型��,AIC則不需要�����??梢夾IC是更簡單也更實用的模型比較方法���。
(2)變量選擇
這里的變量選擇與最開始的變量選擇同也不同�,雖然是一回事�,但一開始是一個粗略的變量的選擇�����,主要是為了構建模型�;這里則要進行細致的變量選擇來調整模型���。
逐步回歸
前面提到的向前或向后選擇或者是同時向前向后選擇變量都是逐步回歸法��。MASS包中的stepAIC() 函數可以實現逐步回歸模型(向前����、向后和向前向后)����,依據的是精確AIC準則��。以下實例是向后回歸法:
-
library(MASS)
-
aovfit1<-lm(Murder~Population+Illiteracy+Income+Frost,data=states)
-
stepAIC(aovfit1,direction="backward")
-
# “forward”為向前選擇���,"backward"為向后選擇���,"both"為混合選擇
-
-
Start:AIC=97.75
-
Murder~Population+Illiteracy+Income+Frost
-
-
DfSumofSqRSS AIC
-
-Frost10.021289.1995.753
-
-Income10.057289.2295.759
-
289.1797.749
-
-Population139.238328.41102.111
-
-Illiteracy1144.264433.43115.986
-
-
Step:AIC=95.75
-
Murder~Population+Illiteracy+Income
-
-
DfSumofSqRSS AIC
-
-Income10.057289.2593.763
-
289.1995.753
-
-Population143.658332.85100.783
-
-Illiteracy1236.196525.38123.605
-
-
Step:AIC=93.76
-
Murder~Population+Illiteracy
-
-
DfSumofSqRSS AIC
-
289.2593.763
-
-Population148.517337.7699.516
-
-Illiteracy1299.646588.89127.311
-
-
Call:
-
lm(formula=Murder~Population+Illiteracy,data=states)
-
-
Coefficients:
-
(Intercept)PopulationIlliteracy
-
1.65154970.00022424.0807366
可見原本的4元回歸模型向后退了兩次�����,最終穩定成了2元回歸模型��,與前面模型比較的結果一致��。
全子集回歸
《R語言實戰》里提到了逐步回歸法的局限:不是每個模型都評價了�����,不能保證選擇的是“最佳”模型�。比如上例中�����,從Murder ~ Population + Illiteracy + Income + Frost到Murder ~ Population + Illiteracy + Income再到Murder~Population+Illiteracy雖然AIC值確實在減少����,但Murder ~ Population + Illiteracy + Frost沒評價�,如果遇到變量很多的情況下���,逐步回歸只沿一個方向回歸��,就有可能錯過最優的回歸方向�。
-
library(leaps)
-
leaps<-regsubsets(Murder~Population+Illiteracy+Income+Frost,data=states,nbest=4)
-
plot(leaps,scale="adjr2")
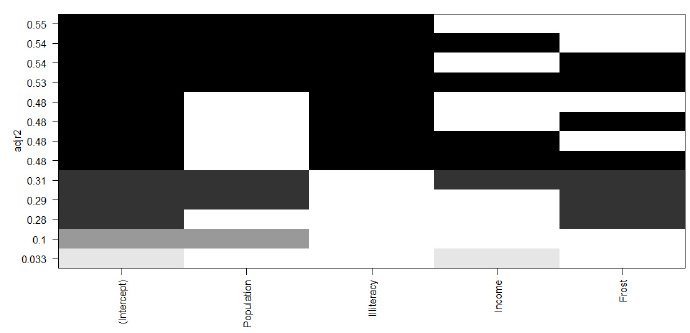
橫坐標是變量���,縱坐標是Adjusted R2����,可見除截距項以外����,只選定Population和Illiteracy這兩個變量��,可以使線性模型有最大的Adjusted R2�����。
全子集回歸比逐步回歸范圍更廣���,模型優化效果更好��,但是一旦變量數多了之后�����,全子集回歸迭代的次數就很多����,就會很慢����。
事實上���,變量的選擇不是機械式地只看那幾個統計指標�����,更主要的是根據數據的實際意義����,從業務角度上來選擇合適的變量�。
線性模型變量的選擇在《統計學習》后面的第6章還會繼續講到����,到時繼續綜合討論�。
(3)交互項
交互項《統計學習》中花了一定篇幅來描寫�����,但在《R語言實戰》是在方差分析章節中討論�����。添加變量間的交互項有時可以改善線性關系�����,提高Adjusted R2�。針對數據的實際意義�,如果兩個基本上是獨立的�,也很難產生交互�、產生協同效應的變量�,那就不必考慮交互項�;只有從業務角度分析��,有可能產生協同效應的變量間才考慮交互項���。
涉及到交互項有一個原則:如果交互項是顯著的���,那么即使變量不顯著�����,也要放在回歸模型中���;若變量和交互項都不顯著�����,則可以都不放�����。
(4)交叉驗證
Andrew Ng的Machine Learning中就提到了�����,模型對舊數據擬合得好不一定就對新數據預測得好���。因此一個數據集應當被分兩訓練集和測試集兩部分(或者訓練集����、交叉驗證集�、測試集三部分)�,訓練好的模型還要在新數據中測試性能�。
所謂交叉驗證����,即將一定比例的數據挑選出來作為訓練樣本�����,另外的樣本作保留樣本�,先在訓練樣本上獲取回歸方程�,然后在保留樣本上做預測���。由于保留樣本不涉及模型參數的選擇�����,該樣本可獲得比新數據更為精確的估計���。
在k 重交叉驗證中����,樣本被分為k個子樣本�����,輪流將k-1個子樣本組合作為訓練集��,另外1個子樣本作為保留集���。這樣會獲得k 個預測方程�����,記錄k 個保留樣本的預測表現結果���,然后求其平均值����。
bootstrap包中的crossval()函數可以實現k重交叉驗證�����。
-
shrinkage<-function(fit,k=10){
-
require(bootstrap)
-
# define functions
-
theta.fit<-function(x,y){
-
lsfit(x,y)
-
}
-
theta.predict<-function(fit,x){
-
cbind(1,x)%*%fit$coef
-
}
-
-
# matrix of predictors
-
x<-fit$model[,2:ncol(fit$model)]
-
# vector of predicted values
-
y<-fit$model[,1]
-
-
results<-crossval(x,y,theta.fit,theta.predict,ngroup=k)
-
r2<-cor(y,fit$fitted.values)^2
-
r2cv<-cor(y,results$cv.fit)^2
-
cat("Original R-square =",r2,"\n")
-
cat(k,"Fold Cross-Validated R-square =",r2cv,"\n")
-
cat("Change =",r2-r2cv,"\n")
-
}
這個自定義的shrinkage()函數用來做k重交叉驗證�����,比計算訓練集和交叉驗證集的R方差異��。這個函數里涉及到一個概念:復相關系數���。復相關系數實際上就是y和fitted(y)的簡單相關系數�。對于一元線性回歸���,R2就是簡單相關系數的平方�����;對于多元線性回歸���,R2是復相關系數的平方����。這個我沒有成功地從公式上推導證明成立����,就記下吧���。這個方法用到了自助法的思想�����,這個在統計學習后面會細致講到���。
-
fit<-lm(Murder~Population+Income+Illiteracy+
-
Frost,data=states)
-
shrinkage(fit)
-
-
OriginalR-square=0.5669502
-
10FoldCross-ValidatedR-square=0.441954
-
Change=0.1249963
可見這個4元回歸模型在交叉驗證集中的R2下降了0.12之多����。若換成前面分析的2元回歸模型——
-
fit2<-lm(Murder~Population+Illiteracy,data=states)
-
shrinkage(fit2)
-
-
OriginalR-square=0.5668327
-
10FoldCross-ValidatedR-square=0.517304
-
Change=0.04952868
這次R2下降只有約0.05�����。R2減少得越少�����,則預測得越準確���。
5��、模型應用
(1)預測
最重要的應用毫無疑問就是用建立的模型進行預測了�。構建好模型后�,可用predict()函數進行預測——
-
fit2<-lm(Murder~Population+Illiteracy,data=states)
-
predict(fit2,
-
newdata=data.frame(Population=c(2000,3000),Illiteracy=c(1.7,2.2)),
-
interval="confidence")
-
-
fit lwr upr
-
19.0371748.00491110.06944
-
211.3017299.86685112.73661
這里newdata提供了兩個全新的點供模型來預測����。還可以用interval指定返回置信區間(confidence)或者預測區間(prediction)���,這也反映了統計與機器學習的一個差異——可解釋性���。注意置信區間考慮的是平均值�,而預測區間考慮的是單個觀測值���,所以預測區間永遠比置信區間廣�,因此預測區間考慮了單個觀測值的不可約誤差���;而平均值同時也把不可約誤差給抵消掉了����。
(2)相對重要性
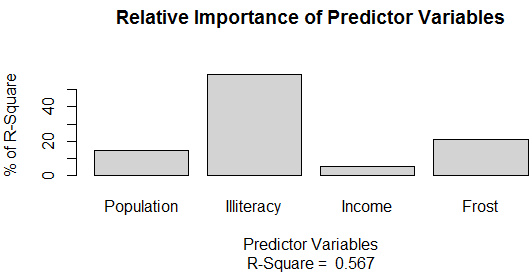
有的時候需要解釋模型中各個自變量對因變量的重要程度�����,簡單處理可以直接看系數即可�����,《R語言實戰》里自定義了一個relweights()函數可以計算各個變量的權重:
-
relweights<-function(fit,...){
-
R<-cor(fit$model)
-
nvar<-ncol(R)
-
rxx<-R[2:nvar,2:nvar]
-
rxy<-R[2:nvar,1]
-
svd<-eigen(rxx)
-
evec<-svd$vectors
-
ev<-svd$values
-
delta<-diag(sqrt(ev))
-
-
# correlations between original predictors and new orthogonal variables
-
lambda<-evec%*%delta%*%t(evec)
-
lambdasq<-lambda^2
-
-
# regression coefficients of Y on orthogonal variables
-
beta<-solve(lambda)%*%rxy
-
rsquare<-colSums(beta^2)
-
rawwgt<-lambdasq%*%beta^2
-
import<-(rawwgt/rsquare)*100
-
lbls<-names(fit$model[2:nvar])
-
rownames(import)<-lbls
-
colnames(import)<-"Weights"
-
-
# plot results
-
barplot(t(import),names.arg=lbls,ylab="% of R-Square",
-
xlab="Predictor Variables",main="Relative Importance of Predictor Variables",
-
sub=paste("R-Square = ",round(rsquare,digits=3)),
-
...)
-
return(import)
-
}
不要在意算法原理和代碼邏輯這種細節�����,直接看結果:
-
fit<-lm(Murder~Population+Illiteracy+Income+
-
Frost,data=states)
-
relweights(fit,col="lightgrey")
-
-
Weights
-
Population14.723401
-
Illiteracy59.000195
-
Income5.488962
-
Frost20.787442
-
fit$coefficients
-
-
(Intercept)PopulationIlliteracyIncomeFrost
-
1.23456341120.00022367544.14283659030.00006442470.0005813055
-
-
barplot(fit$coefficients[2:5])
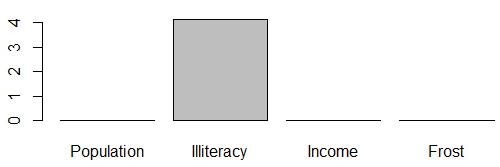
在本例中����,相對權重與系數的排序結果一致��。推薦用相對權重�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
