機器學習����、數據挖掘��、人工智能����、統計模型這么多概念有何差異
在各種各樣的數據科學論壇上這樣一個問題經常被問到——機器學習和統計模型的差別是什么���?這確實是一個難以回答的問題����?���?紤]到機器學習和統計模型解決問題的相似性���,兩者的區別似乎僅僅在于數據量和模型建立者的不同��。這里有一張覆蓋機器學習和統計模型的數據科學維恩圖��。
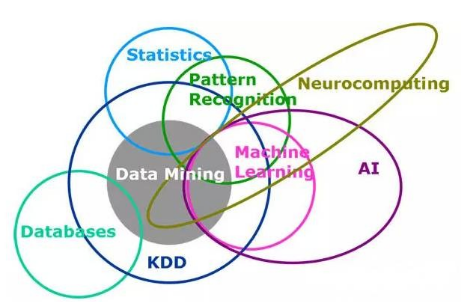
在這篇文章中�,我將盡最大的努力來展示機器學習和統計模型的區別�����,同時也歡迎業界有經驗的朋友對本文進行補充����。
在我開始之前���,讓我們先明確使用這些工具背后的目標��。無論采用哪種工具去分析問題���,最終的目標都是從數據獲得知識��。兩種方法都旨在通過分析數據的產生機制挖掘背后隱藏的信息��。
兩種方法的分析目標是相同的?�,F在讓我們詳細的探究一下其定義及差異��。
定義
機器學習:一種不依賴于規則設計的數據學習算法��。
統計模型:以數學方程形式表現變量之間關系的程式化表達
對于喜歡從實際應用中了解概念的人���,上述表達也許并不明確�����。讓我們看一個商務的案例�。
商業案例
讓我們用麥肯錫發布的一個有趣案例來區分兩個算法����。
案例:分析理解電信公司一段時間內客戶的流失水平�����。
可獲得數據:兩個驅動-A&B;
麥肯錫接下來的展示足夠讓人興奮����。盯住下圖來理解一下統計模型和機器學習算法的差別�����。
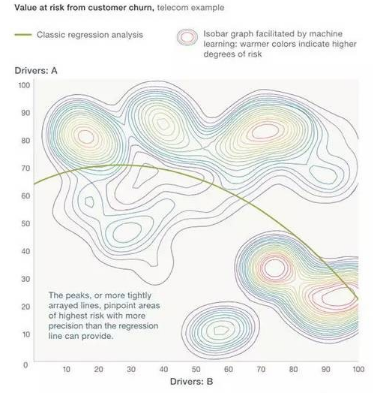
從上圖中你觀察到了什么���?統計模型在分類問題中得到一個簡單的分類線����。一條非線性的邊界線區分了高風險人群和低風險人群��。但當我們看到通過機器學習產生的顏色時���,我們發現統計模型似乎沒有辦法和機器學習算法進行比較���。機器學習的方法獲得了任何邊界都無法詳細表征的信息���。這就是機器學習可以為你做的���。
機器學習還被應用在YouTube和Google的引擎推薦上�����,機器學習通過瞬間分析大量的觀測樣本給出近乎完美的推薦建議���。即使只采用一個16 G 內存的筆記本���,我每天處理數十萬行的數千個參數的模型也不會超過30分鐘����。然而一個統計模型需要在一臺超級計算機跑一百萬年來來觀察數千個參數�����。
機器學習和統計模型的差異:
在給出了兩種模型在輸出上的差異后�,讓我們更深入的了解兩種范式的差異���,雖然它們所做的工作類似�����。
1���、所屬的學派
2��、產生時間
3�、基于的假設
4���、處理數據的類型
5�����、操作和對象的術語
6�����、使用的技術
7�、預測效果和人力投入
以上提到的方面都能從每種程度上區分機器學習和統計模型����,但并不能給出機器學習和統計模型的明確界限���。
分屬不同的學派
機器學習:計算機科學和人工智能的一個分支,通過數據學習構建分析系統�����,不依賴明確的構建規則���。統計模型:數學的分支用以發現變量之間相關關系從而預測輸出���。
誕生年代不同
統計模型的歷史已經有幾個世紀之久�。但是機器學習卻是最近才發展起來的����。二十世紀90年代����,穩定的數字化和廉價的計算使得數據科學家停止建立完整的模型而使用計算機進行模型建立�����。這催生了機器學習的發展��。隨著數據規模和復雜程度的不斷提升��,機器學習不斷展現出巨大的發展潛力�。
假設程度差異
統計模型基于一系列的假設���。例如線性回歸模型假設:
(1) 自變量和因變量線性相關
(2) 同方差
(3) 波動均值為0
(4) 觀測樣本相互獨立
(5) 波動服從正態分布
Logistics回歸同樣擁有很多的假設�����。即使是非線性回歸也要遵守一個連續的分割邊界的假設����。然而機器學習卻從這些假設中脫身出來���。機器學習最大的好處在于沒有連續性分割邊界的限制����。同樣我們也并不需要假設自變量或因變量的分布����。
數據區別
機器學習應用廣泛�����。在線學習工具可飛速處理數據�����。這些機器學習工具可學習數以億計的觀測樣本�����,預測和學習同步進行����。一些算法如隨機森林和梯度助推在處理大數據時速度很快�����。機器學習處理數據的廣度和深度很大�。但統計模型一般應用在較小的數據量和較窄的數據屬性上����。
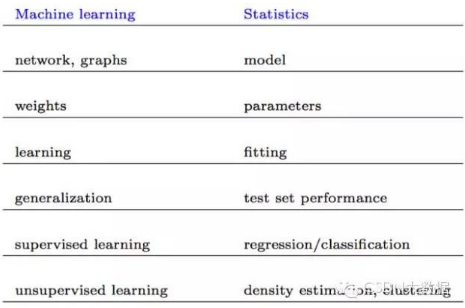
命名公約
下面一些命名幾乎指相同的東西:
公式:
雖然統計模型和機器學習的最終目標是相似的���,但其公式化的結構卻非常不同
在統計模型中�����,我們試圖估計f 函數 通過
因變量(Y)=f(自變量)+ 擾動 函數
機器學習放棄采用函數f的形式���,簡化為:
輸出(Y)——> 輸入(X)
它試圖找到n維變量X的袋子��,在袋子間Y的取值明顯不同�。
預測效果和人力投入
自然在事情發生前并不給出任何假設����。一個預測模型中越少的假設�����,越高的預測效率���。機器學習命名的內在含義為減少人力投入���。機器學習通過反復迭代學習發現隱藏在數據中的科學��。由于機器學習作用在真實的數據上并不依賴于假設�����,預測效果是非常好的����。統計模型是數學的加強���,依賴于參數估計�。它要求模型的建立者�����,提前知道或了解變量之間的關系�����。
結束語
雖然機器學習和統計模型看起來為預測模型的不同分支�,但它們近乎相同��。通過數十年的發展兩種模型的差異性越來越小���。模型之間相互滲透相互學習使得未來兩種模型的界限更加模糊����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
