R語言多項式回歸
含有x和y這兩個變量的線性回歸是所有回歸分析中最常見的一種��;而且��,在描述它們關系的時候��,也是最有效�����、最容易假設的一種模型��。然而���,有些時候�,它的實際情況下某些潛在的關系是非常復雜的�,不是二元分析所能解決的����,而這時��,我們需要多項式回歸分析來找到這種隱藏的關系�����。
讓我們看一下經濟學里的一個例子:假設你要買一個具體的產品����,而你要買的個數是q��。如果產品的單價是p�����,然后�����,你要給y元�。其實�����,這就是一個很典型的線性關系�。而總價和產品數量呈正比例關系���。下面�����,根據這個實例��,我們敲擊行代碼來作它們的線性關系圖:
-
p <- 0.5
-
q <- seq(0,100,1)
-
y <- p*q
-
plot(q,y,type='l',col='red',main='Linear relationship')
下面是它的線性關系圖:
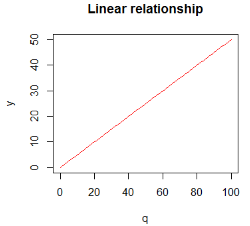
現在�,我們看到這確實是一個不錯的估計��,這個圖很好的模擬成q和y的線性關系���。然而���,當我們在做買賣要考慮別的因素的時候����,諸如這種商品要買多少����,很有可能����,我們可以通過詢問和討價賺得折扣����,或者����,當我們越來越多的買一種具體的商品的時候����,我們也可能讓這種商品升價了����。
這樣��,我們根據上面的條件���,我們在寫腳本的時候�����,我們要注意����,總價與產品的數量不再具有線性關系了:
-
y <- 450 + p*(q-10)^3
-
plot(q,y,type='l',col='navy',main='Nonlinear relationship',lwd=3)
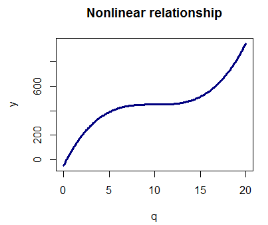
利用多項式回歸�����,我們可以擬合n>1張訂單所產生的數據的模型�,并且能試著建一個非線性模型�。
怎樣擬合一個多項式回歸
首先�,當我們要創建一串虛擬隨機數的時候��,我們必須總要記得寫set.seed(n)���。這樣做�����,隨機數生成器總能產生同等數目的數據��。
預測變量q:使用seq來快速產生等間距的序列:
-
q <- seq(from=0, to=20, by=0.1)
預測y值:
-
y <- 500 + 0.4 * (q-10)^3
我們現在產生一些噪音并把它添加到模型中:
-
noise <- rnorm(length(q), mean=10, sd=80)
-
noisy.y <- y + noise
對噪聲數據進行畫圖:
-
plot(q,noisy.y,col='deepskyblue4',xlab='q',main='Observed data')
-
lines(q,y,col='firebrick1',lwd=3)
下面的這個圖根據觀測數據進行模擬�����。其中�����,模擬的圖的散點是藍色的��,而紅色線則是信號(信號是一種術語���,它通常用于表示我們感興趣的東西的通常變化趨勢)��。
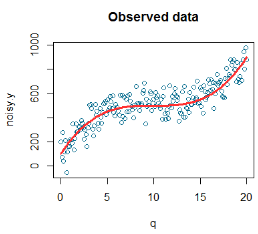
我們得出的模型應當是 y = aq + bq2 + c*q3 + cost�。
現在�����,我們用R對此進行模擬����。要擬合一個多項式模型�����,你也可以這樣用:
-
model <- lm(noisy.y ~ poly(q,3))
或者:
-
model <- lm(noisy.y ~ x + I(X^2) + I(X^3))
然而����,我們要知道q����,I(q^2)��,I(q^3)存在相關的關系����,而這些相關變量很有可能引起某些問題的產生��。這時�����,使用poly()可以避免這個問題�����,因為它是創建一個垂直的多項式�。因此���,我喜歡第一種方法:
-
summary(model)
-
Call:
-
lm(formula = noisy.y ~ poly(q, 3))
-
Residuals:
-
Min 1Q Median 3Q Max
-
-212.326 -51.186 4.276 61.485 165.960
-
Coefficients:
-
Estimate Std. Error t value Pr(>|t|)
-
(Intercept) 513.615 5.602 91.69 <2e-16 ***
-
poly(q, 3)1 2075.899 79.422 26.14 <2e-16 ***
-
poly(q, 3)2 -108.004 79.422 -1.36 0.175
-
poly(q, 3)3 864.025 79.422 10.88 <2e-16 ***
-
---
-
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
-
Residual standard error: 79.42 on 197 degrees of freedom
-
Multiple R-squared: 0.8031, Adjusted R-squared: 0.8001
-
F-statistic: 267.8 on 3 and 197 DF, p-value: 0
我們可以使用confint()來獲得一個模型的參數的置信區間�����。
以下是模型參數的置信區間:
-
confint(model, level=0.95)
-
2.5 % 97.5 %
-
(Intercept) 502.5676 524.66261
-
poly(q, 3)1 1919.2739 2232.52494
-
poly(q, 3)2 -264.6292 48.62188
-
poly(q, 3)3 707.3999 1020.65097
現在���,我們要作一個擬合VS殘差圖����。如果這是一個擬合效果比較不錯的模型�����,我們應該看不到任何一種模型的模式特征:
-
plot(fitted(model),residuals(model))
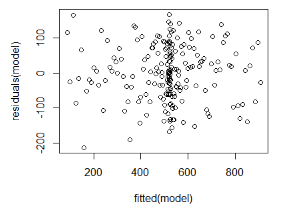
整體來說��,這個模型的擬合效果還是不錯的�,畢竟殘差為0.8�����。第一和第三個訂單序列的系數����,在統計學當中�����,是相當這樣的���,這樣在我們的意料之中?���,F在�����,我們可以使用predict()函數來獲得擬合數據以及置信區間��,這樣��,我們可以不按照數據來作圖����。 下面是預測值和預測置信區間:
-
predicted.intervals <- predict(model,data.frame(x=q),interval='confidence',level=0.99)
在已有的圖像中添加擬合線:
-
lines(q,predicted.intervals[,1],col='green',lwd=3)
-
lines(q,predicted.intervals[,2],col='black',lwd=1)
-
lines(q,predicted.intervals[,3],col='black',lwd=1)
添加圖例:
-
legend("bottomright",c("Observ.","Signal","Predicted"),
-
col=c("deepskyblue4","red","green"), lwd=3)
下面是它的擬合圖像:
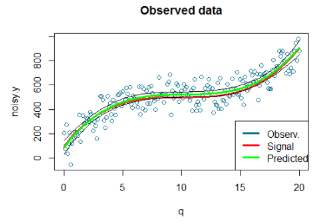
我們可以看到我們的模型在數據的擬合方面做的不錯��,我們也因此感到非常滿意����。
注意:多項式回歸是一種更能強大的工具��?�?墒?���,我們也可能得到事與愿違的結果:在這個例子中����,我們知道我們的信號是使用三次多項式而產生的���,然而���,當我們在分析實際數據的時候�,我們通常對此不知情�,因此���,正因為多項式次數n大于4的時候會產生過度擬合的情況��,我們要在這里注意一下����。但你的模型取了噪音而不是信號的時候會產生過擬合的情況�����;甚至��,當你在現有的數據進行模型優化的時候�����,當你要嘗試預測新的數據的時候就不好了��,它會導致缺失值的產生�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
