一�、什么是數據分析�����?
數據分析既是一門藝術���,所謂藝術就是結合技術�����、想象��、經驗和意愿等綜合因素的平衡和融合�����。數據分析的目的就是幫助我們把數據(Data)變成信息(Information)���,再從信息變成知識(Knowledge)���,最后從知識變成智慧(Wisdom)���。
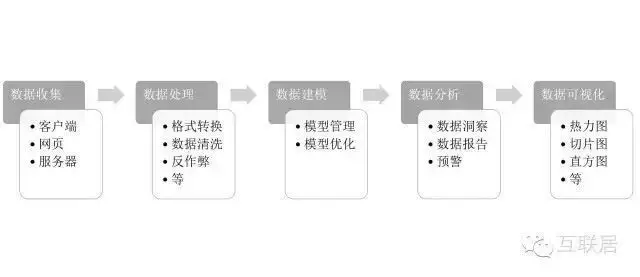 在數據分析的領域����,商務智能(BI:Business Intelligence)�����、數據挖掘(DM:Data Mining)�、聯機分析處理(OLAP:On-Line Analytical Processing)等概念在名稱上和數據分析字面非常接近�����,容易混淆�,如下做個簡單介紹���。
· 商務智能(BI):商務智能是在商業數據上進行價值挖掘的過程���,BI的歷史很長��,很多時候會特別指通過數據倉庫的技術進行業務報表制作和分析的過程��,分析方法上通常使用聚合(Aggregation)�、分片(Slice)等方式進行數據處理��。技術上���,BI包括ETL(數據的抽取����、轉換�、加載)����,數據倉庫(Data Warehouse)��,OLAP(聯機分析處理)����,數據挖掘(Data Mining)等技術����。
· 數據挖掘:數據挖掘是指在大量數據中自動搜索隱藏于其中的有著特殊關系性(屬于Association rule learning)的信息的過程�����。相比商務智能�,數據挖掘是一種更加學術的說法�,范圍也廣��,深淺皆宜��,強調技術和方法��。
· 聯機分析處理:聯機分析處理(OLAP)是一個建立數據系統的方法�����,其核心思想即建立多維度的數據立方體���,以維度(Dimension)和度量(Measure)為基本概念��,輔以元數據實現可以鉆?。―rill-down/up)����、切片(Slice)��、切塊(Dice)等靈活�、系統和直觀的數據展現�����。
在數據分析的領域����,商務智能(BI:Business Intelligence)�����、數據挖掘(DM:Data Mining)�、聯機分析處理(OLAP:On-Line Analytical Processing)等概念在名稱上和數據分析字面非常接近�����,容易混淆�,如下做個簡單介紹���。
· 商務智能(BI):商務智能是在商業數據上進行價值挖掘的過程���,BI的歷史很長��,很多時候會特別指通過數據倉庫的技術進行業務報表制作和分析的過程��,分析方法上通常使用聚合(Aggregation)�、分片(Slice)等方式進行數據處理��。技術上���,BI包括ETL(數據的抽取����、轉換�、加載)����,數據倉庫(Data Warehouse)��,OLAP(聯機分析處理)����,數據挖掘(Data Mining)等技術����。
· 數據挖掘:數據挖掘是指在大量數據中自動搜索隱藏于其中的有著特殊關系性(屬于Association rule learning)的信息的過程�����。相比商務智能�,數據挖掘是一種更加學術的說法�,范圍也廣��,深淺皆宜��,強調技術和方法��。
· 聯機分析處理:聯機分析處理(OLAP)是一個建立數據系統的方法�����,其核心思想即建立多維度的數據立方體���,以維度(Dimension)和度量(Measure)為基本概念��,輔以元數據實現可以鉆?。―rill-down/up)����、切片(Slice)��、切塊(Dice)等靈活�、系統和直觀的數據展現�����。
數據分析就是以業務為導向��,從數據中發掘提升業務能力的洞察��。
二���、數據分析軟件的發展
數據分析軟件市場從來都是活躍的市場�����,從兩個視角來看����,一個是商業軟件市場���,充滿了大魚吃小魚的故事���;另一個是開源數據存儲處理軟件�����,在互聯網精神和開源情懷的引導下�,各種專業領域的開源軟件日益壯大���,通用數據存儲系統也不斷升級���。
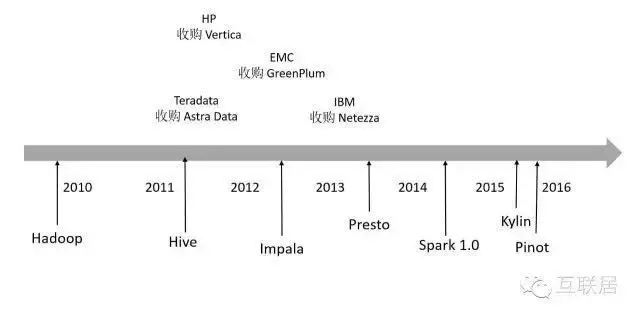
舉例來說�,2011年��,Teradata收購了Aster Data 公司����, 同年惠普收購實時分析平臺Vertica等����;2012年�����,EMC收購數據倉庫軟件廠商Greenplum���;2013年�����,IBM宣布以17億美元收購數據分析公司Netezza�����;這些收購事件指向的是同一個目標市場———大數據分析����。傳統的數據庫軟件����,處理TB級數據非常費勁���,而這些新興的數據庫正式瞄準TB級別�����,乃至PB級別的數據分析���。
在開源世界�����,Hadoop將人們引入了大數據時代��,處理TB級別大數據成為一種可能����,但實時性能一直是Hadoop的一個傷痛�。2014年�,Spark橫空出世����,通過最大利用內存處理數據的方式��,大大改進了數據處理的響應時間�����,快速發展出一個較為完備的生態系統�。另外�����,大量日志數據都存放在HDFS中�����,如何提高數據處理性能���,支持實時查詢功能則成為了不少開源數據軟件的核心目標����。例如Hive利用MapReduce作為計算引擎�,Presto自己開發計算引擎�����,Druid使用自己開發索引和計算引擎等�����,都是為了一個目標:處理更多數據�,獲取更高性能�。
 三����、數據分析軟件的分類
為了全面了解分類數據分析軟件�,我們按照以下幾個分類來介紹���。
· 商業數據庫 開源時序數據庫
· 開源計算框架
· 開源數據分析軟件
· 開源SQL on Hadoop
三����、數據分析軟件的分類
為了全面了解分類數據分析軟件�,我們按照以下幾個分類來介紹���。
· 商業數據庫 開源時序數據庫
· 開源計算框架
· 開源數據分析軟件
· 開源SQL on Hadoop
· 云端數據分析SaaS
四����、商業軟件
商用數據庫軟件種類繁多����,但是真正能夠支持TB級別以上的數據存儲和分析并不太多�,這里介紹幾個有特點的支持大數據的商用數據庫軟件����。
1.HP Vertica
Vertica公司成立于2005年��,創立者為數據庫巨擘Michael Stonebraker(2014年圖靈獎獲得者�����,INGRES�,PostgreSQL���,VoltDB等數據庫發明人)����。2011年Vertica被惠普收購���。Vertica軟件是能提供高效數據存儲和快速查詢的列存儲數據庫實時分析平臺�,還支持大規模并行處理(MPP)�����。產品廣泛應用于高端數字營銷�����、互聯網客戶(比如Facebook�、AOL����、Twitter��、 Groupon)分析處理�,數據達到PB級����。Facebook利用Vertica進行快速的用戶數據分析�����,據稱Facebook超過300節點(Node)和處理超過6PB數據�����。
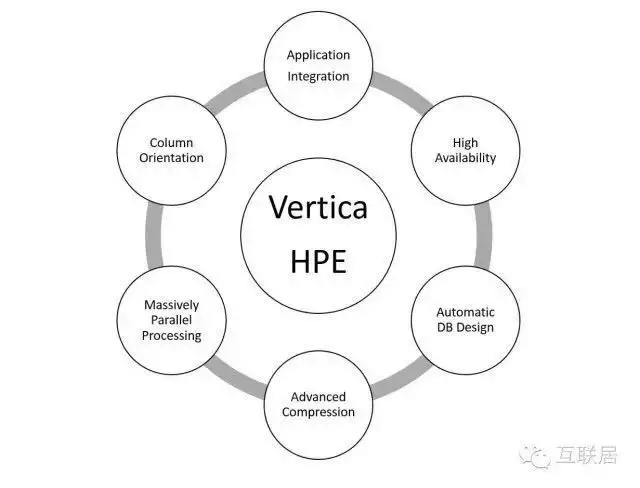
Vertica有以下幾個特點:
· 面向列的存儲
· 靈活的壓縮算法�����,根據數據的排序性和基數決定壓縮算法
· 高可用數據庫和查詢
· MPP架構�,分布式存儲和任務負載����,Share Nothing架構
· 支持標準的SQL查詢����,ODBC/JDBC等
· 支持Projection(數據投射)功能
 Vertica的Projection技術����,原理是將數據的某些列提取出來進行專門的存儲���,以加快后期的訪問數據�,同一個列可以在不同的Projection中����。
Vertica的Projection技術����,原理是將數據的某些列提取出來進行專門的存儲���,以加快后期的訪問數據�,同一個列可以在不同的Projection中����。

2.Oracle Exadata
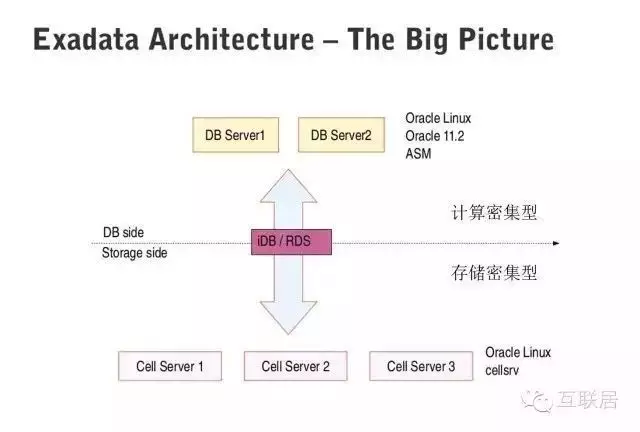
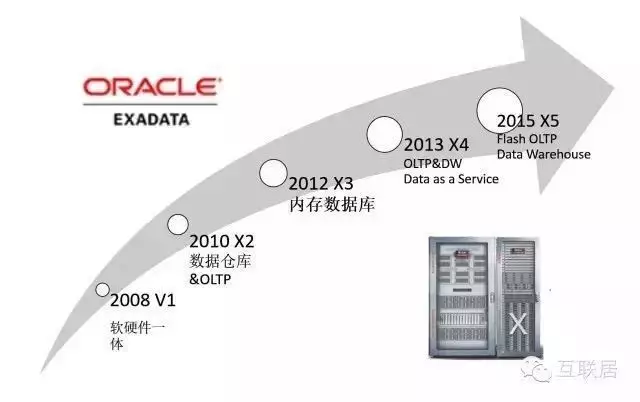
Oracle Exadata是數據庫發展史上一個傳奇��,它是數據庫軟件和最新硬件的完美結合��。其提供最快最可靠的數據庫平臺��,不僅支持常規的數據庫應用�����,也支持聯機分析處理(OLAP)和數據倉庫(DW)的場景�����。
Exadata采用了多種最新的硬件技術�,例如40Gb/秒的InfiniBand網絡( InfiniBand 是超高速的專用數據網絡協議���,主要專用硬件支持)����,3.2TB PCI閃存卡(每個閃存卡都配有Exadata智能緩存����,X6型號)��。Oracle Exadata 數據庫云服務器允許將新一代服務器和存儲無縫部署到現有Oracle Exadata 數據庫云服務器中���。它包含兩套子系統����,一套處理計算密集型的查詢����,一套處理存儲密集型的查詢����,Exadata能夠做到智能查詢分配�����。
 Oracle Exadata有如下幾個技術特點:
· 采用InfiniBand高速網絡 采用極速閃存方案�。+ 全面的Oracle數據庫兼容性����。
· 針對所有數據庫負載進行了優化�,包括智能掃描���。
· Oracle Exadata支持混合列壓縮���。
Oracle Exadata2008年推出����,軟硬件一體��,不斷發展壯大�����,漸漸形成高性能數據庫的代名詞��。
Oracle Exadata有如下幾個技術特點:
· 采用InfiniBand高速網絡 采用極速閃存方案�。+ 全面的Oracle數據庫兼容性����。
· 針對所有數據庫負載進行了優化�,包括智能掃描���。
· Oracle Exadata支持混合列壓縮���。
Oracle Exadata2008年推出����,軟硬件一體��,不斷發展壯大�����,漸漸形成高性能數據庫的代名詞��。
 Oracle Exadata混合列存儲是介于行存儲和列存儲之間的一個方案��,主要思想是對列進行分段處理�����,每一段都使用列式存儲放在Block中��,而后按照不同的壓縮策略處理���。
3.Teredata
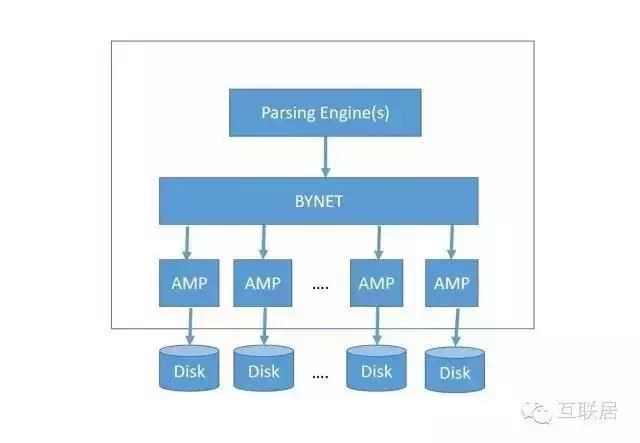
Teradata(天睿)公司專注于大數據分析�、數據倉庫和整合營銷管理解決方案的供應商��。Teredata采用純粹的Share Nothing架構��,支持MPP����。對于多維度的查詢更加靈活�����,專注與數據倉庫的應用領域�����。下面是TereData的架構���,其中PE用于查詢的分析引擎�,分析SQL查詢�,制定查詢計劃��,聚合查詢結果等��;BYNET是一個高速的互聯層�,是一個軟件和硬件結合的解決方案���。
AMP(Access Module Processor)是存儲和查詢數據的節點�����,支持排序和聚合等操作��。
Oracle Exadata混合列存儲是介于行存儲和列存儲之間的一個方案��,主要思想是對列進行分段處理�����,每一段都使用列式存儲放在Block中��,而后按照不同的壓縮策略處理���。
3.Teredata
Teradata(天睿)公司專注于大數據分析�、數據倉庫和整合營銷管理解決方案的供應商��。Teredata采用純粹的Share Nothing架構��,支持MPP����。對于多維度的查詢更加靈活�����,專注與數據倉庫的應用領域�����。下面是TereData的架構���,其中PE用于查詢的分析引擎�,分析SQL查詢�,制定查詢計劃��,聚合查詢結果等��;BYNET是一個高速的互聯層�,是一個軟件和硬件結合的解決方案���。
AMP(Access Module Processor)是存儲和查詢數據的節點�����,支持排序和聚合等操作��。
 另外Teredata還提出了一個統一的數據數據分析框架����,其中包括兩個核心產品���,一個是Teredata數據倉庫����,另外是一個Teredata Aster數據分析產品�����。這兩個產品分別走不同的路線:Teredata是傳統數據倉庫���,滿足通用的數據需求��,Aster實際上是一種基于MapReduce的數據分析解決方案�����,可以支持更加靈活的數據結構的處理����,例如非結構化數據的處理����。
另外Teredata還提出了一個統一的數據數據分析框架����,其中包括兩個核心產品���,一個是Teredata數據倉庫����,另外是一個Teredata Aster數據分析產品�����。這兩個產品分別走不同的路線:Teredata是傳統數據倉庫���,滿足通用的數據需求��,Aster實際上是一種基于MapReduce的數據分析解決方案�����,可以支持更加靈活的數據結構的處理����,例如非結構化數據的處理����。
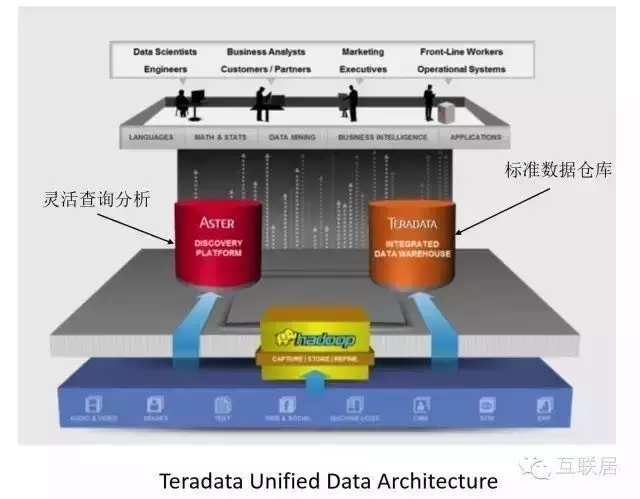 Teredata提供了一個完整的數據解決方案��,包括數據倉庫和MapReduce��。
五�����、時序數據庫
時序數據庫用于記錄在過去時間的各個數據點的信息�����,典型的應用是服務器的各種性能指標����,例如CPU�����,內存使用情況等等���。目前也廣泛應用于各種傳感器的數據收集分析工作��,這些數據的收集都有一個特點���,對時間的依賴非常大���,每天產生的數據量都非常大���,因此寫入的量非常大����,一般的關系數據庫無法滿足這些場景��。因此時序數據庫����,在設計上需要支持高吞吐��,高效數據壓縮�,支持歷史查詢�,分布式部署等特點�。
1.OpenTSDB
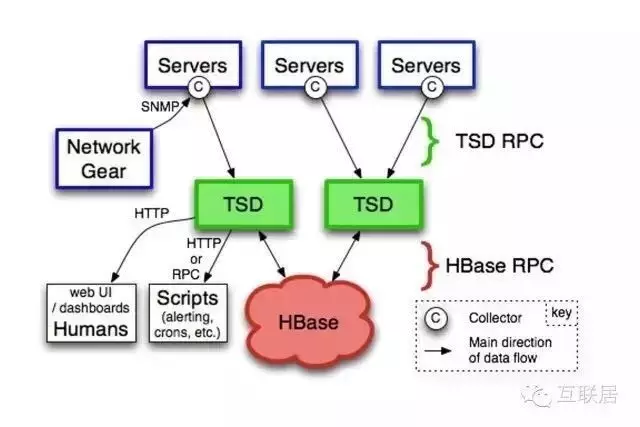
OpenTSDB是一個開源的時序數據庫���,支持存儲數千億的數據點��,并提供精確查詢功能���。它采用Java語言編寫��,通過基于HBase的存儲實現橫向擴展����。它廣泛用于服務器性能的監控和度量���,包括網絡和服務器�����,傳感器����,IoT����,金融數據的實時監控領域�����。OpenTSDB應用于很多互聯網公司的運維系統����,例如Pinterest公司有超過100個節點的部署��,Yahoo��!公司也有超過50節點的部署�����。它的設計思路是利用HBase的Key存儲一些tag信息�����,將同一個小時數據放在一行存儲��,方便查詢的速度�����。
Teredata提供了一個完整的數據解決方案��,包括數據倉庫和MapReduce��。
五�����、時序數據庫
時序數據庫用于記錄在過去時間的各個數據點的信息�����,典型的應用是服務器的各種性能指標����,例如CPU�����,內存使用情況等等���。目前也廣泛應用于各種傳感器的數據收集分析工作��,這些數據的收集都有一個特點���,對時間的依賴非常大���,每天產生的數據量都非常大���,因此寫入的量非常大����,一般的關系數據庫無法滿足這些場景��。因此時序數據庫����,在設計上需要支持高吞吐��,高效數據壓縮�,支持歷史查詢�,分布式部署等特點�。
1.OpenTSDB
OpenTSDB是一個開源的時序數據庫���,支持存儲數千億的數據點��,并提供精確查詢功能���。它采用Java語言編寫��,通過基于HBase的存儲實現橫向擴展����。它廣泛用于服務器性能的監控和度量���,包括網絡和服務器�����,傳感器����,IoT����,金融數據的實時監控領域�����。OpenTSDB應用于很多互聯網公司的運維系統����,例如Pinterest公司有超過100個節點的部署��,Yahoo��!公司也有超過50節點的部署�����。它的設計思路是利用HBase的Key存儲一些tag信息�����,將同一個小時數據放在一行存儲��,方便查詢的速度�����。
 2.InfluxDB
InfluxDB是最近非常流行的一個時序數據庫��,由GoLang語言開發�,目前社區非?���;钴S��,它也是GoLang的一個非常成功的開源應用����。其技術特點包括:支持任意數量的列�����、支持方便強大的查詢語言����、集成了數據采集���、存儲和可視化功能��。它支持高效存儲�����,使用高壓縮比的算法等����。早期設計中�,存儲部分使用LevelDB為存儲��,后來改成Time Series Merge Tree作為內部存儲�����,支持SQL類似的查詢語言�����。
六���、開源分布式計算平臺
1.Hadoop
Hadoop 是一個分布式系統基礎架構���,由Apache基金會開發�����。用戶可以在不了解分布式底層細節的情況下�,開發分布式程序�����。充分利用集群的威力高速運算和存儲�����。Hadoop實現了一個分布式文件系統(Hadoop Distributed File System)���,簡稱HDFS����。除了文件存儲�����,Hadoop還有最完整的大數據生態����,包括機器管理��、NoSQL KeyValue存儲(如HBase)�、協調服務(Zookeeper等)��、SQL on Hadoop(Hive)等�����。
2.InfluxDB
InfluxDB是最近非常流行的一個時序數據庫��,由GoLang語言開發�,目前社區非?���;钴S��,它也是GoLang的一個非常成功的開源應用����。其技術特點包括:支持任意數量的列�����、支持方便強大的查詢語言����、集成了數據采集���、存儲和可視化功能��。它支持高效存儲�����,使用高壓縮比的算法等����。早期設計中�,存儲部分使用LevelDB為存儲��,后來改成Time Series Merge Tree作為內部存儲�����,支持SQL類似的查詢語言�����。
六���、開源分布式計算平臺
1.Hadoop
Hadoop 是一個分布式系統基礎架構���,由Apache基金會開發�����。用戶可以在不了解分布式底層細節的情況下�,開發分布式程序�����。充分利用集群的威力高速運算和存儲�����。Hadoop實現了一個分布式文件系統(Hadoop Distributed File System)���,簡稱HDFS����。除了文件存儲�����,Hadoop還有最完整的大數據生態����,包括機器管理��、NoSQL KeyValue存儲(如HBase)�、協調服務(Zookeeper等)��、SQL on Hadoop(Hive)等�����。
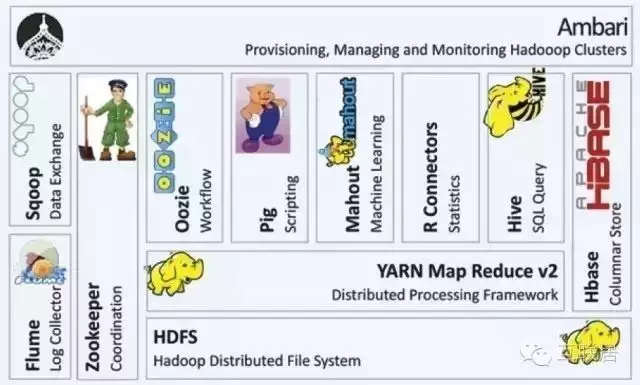 Hadoop基于可靠的分布式存儲���,通過MapReduce進行迭代計算�����,查詢批量的數據����。Hadoop是高吞吐的批處理系統�,適合大型任務的運行�,但對任務響應時間和實時性上有嚴格要求的需求方面Hadoop并不擅長��。
2.Spark
Spark是UC Berkeley AMP lab開源的類Hadoop MapReduce的通用的并行計算框架�,Spark同樣也是基于分布式計算����,擁有Hadoop MapReduce的所有優點����;不同的是Spark任務的中間計算結果可以緩存在內存中����,這樣迭代計算時可從內存直接獲取中間結果而不需要頻繁讀寫HDFS���,因此Spark運行速度更快����,適用于對性能有要求的數據挖掘與數據分析的場景�����。
Hadoop基于可靠的分布式存儲���,通過MapReduce進行迭代計算�����,查詢批量的數據����。Hadoop是高吞吐的批處理系統�,適合大型任務的運行�,但對任務響應時間和實時性上有嚴格要求的需求方面Hadoop并不擅長��。
2.Spark
Spark是UC Berkeley AMP lab開源的類Hadoop MapReduce的通用的并行計算框架�,Spark同樣也是基于分布式計算����,擁有Hadoop MapReduce的所有優點����;不同的是Spark任務的中間計算結果可以緩存在內存中����,這樣迭代計算時可從內存直接獲取中間結果而不需要頻繁讀寫HDFS���,因此Spark運行速度更快����,適用于對性能有要求的數據挖掘與數據分析的場景�����。
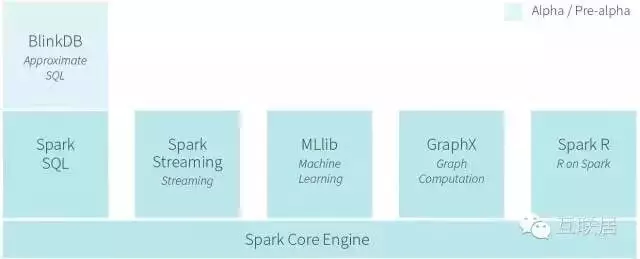 Spark是實現彈性的分布式數據集概念的計算集群系統�����,可以看做商業分析平臺���。 RDDs能復用持久化到內存中的數據�,從而為迭代算法提供更快的計算速度����。這對一些工作流例如機器學習格外有用����,比如有些操作需要重復執行很多次才能達到結果的最終收斂��。同時�����,Spark也提供了大量的算法用來查詢和分析大量數據����,其開發語言采用scala�����,因此直接在上面做數據處理和分析���,開發成本會比較高�,適合非結構化的數據查詢處理����。
七���、開源大數據實時分析數據庫
1.Druid
Druid是我非常喜歡的一個開源分析數據庫:簡單���,高效���,穩定�����,支持大型數據集上進行實時查詢的開源數據分析和存儲系統����。它提供了低成本�����,高性能����,高可靠性的解決方案�����,整個系統支持水平擴展���,管理方便�。實際上��,Druid的很多設計思想來源于Google的秘密分析武器PowerDrill����,從功能上��,和Apache開源的Dremel也有幾分相似�。
Druid被設計成支持PB級別數據量��,現實中有數百TB級別的數據應用實例���,每天處理數十億流式事件�。Druid廣泛應用在互聯網公司中����,例如阿里�����,百度��,騰訊�����,小米�����,愛奇藝��,優酷等�����,特別是用戶行為分析�����,個性化推薦的數據分析����,物聯網的實時數據分析�,互聯網廣告交易分析等領域�����。
從架構上解釋�,Druid是一個典型的Lambda架構���,分為實時數據流和批處理數據流��。全部節點使用MySQL管理MetaData����,并且使用Zookeeper管理狀態等�����。
Spark是實現彈性的分布式數據集概念的計算集群系統�����,可以看做商業分析平臺���。 RDDs能復用持久化到內存中的數據�,從而為迭代算法提供更快的計算速度����。這對一些工作流例如機器學習格外有用����,比如有些操作需要重復執行很多次才能達到結果的最終收斂��。同時�����,Spark也提供了大量的算法用來查詢和分析大量數據����,其開發語言采用scala�����,因此直接在上面做數據處理和分析���,開發成本會比較高�,適合非結構化的數據查詢處理����。
七���、開源大數據實時分析數據庫
1.Druid
Druid是我非常喜歡的一個開源分析數據庫:簡單���,高效���,穩定�����,支持大型數據集上進行實時查詢的開源數據分析和存儲系統����。它提供了低成本�����,高性能����,高可靠性的解決方案�����,整個系統支持水平擴展���,管理方便�。實際上��,Druid的很多設計思想來源于Google的秘密分析武器PowerDrill����,從功能上��,和Apache開源的Dremel也有幾分相似�。
Druid被設計成支持PB級別數據量��,現實中有數百TB級別的數據應用實例���,每天處理數十億流式事件�。Druid廣泛應用在互聯網公司中����,例如阿里�����,百度��,騰訊�����,小米�����,愛奇藝��,優酷等�����,特別是用戶行為分析�����,個性化推薦的數據分析����,物聯網的實時數據分析�,互聯網廣告交易分析等領域�����。
從架構上解釋�,Druid是一個典型的Lambda架構���,分為實時數據流和批處理數據流��。全部節點使用MySQL管理MetaData����,并且使用Zookeeper管理狀態等�����。
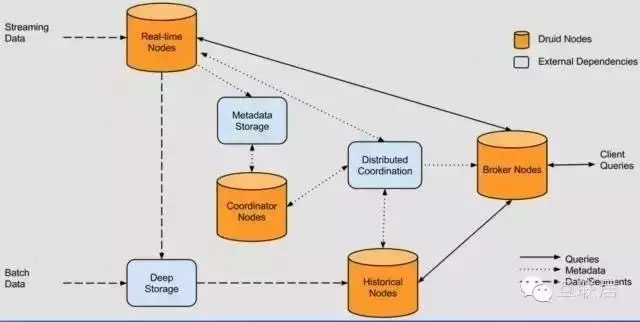 Druid的架構圖顯示Druid自身包含以下四類節點:
· 實時節點(Realtime Node):及時攝入實時數據�����,以及生成Segment數據文件��。
· 歷史節點(Historical Node):加載已生成好的數據文件以供數據查詢���。
· 查詢節點(Broker Node):對外提供數據查詢服務����,并同時從實時節點與歷史節點查詢數據��、合并后返回給調用方�����。
· 協調節點(Coordinator Node):負責歷史節點的數據負載均衡����,以及通過Rules管理數據的生命周期�����。
同時�,集群還包含以下三類外部依賴:
· 元數據庫(Metastore):存儲Druid集群的原數據信息���,比如segment的相關信息��,一般用MySQL或PostgreSQL���。
· 分布式協調服務(Coordination):為Druid集群提供一致性協調服務的組件���,通常為Zookeeper��。
· 數據文件存儲庫(DeepStorage):存放生成的Segment數據文件����,并供歷史節點下載�。
對于單節點集群來說可以是本地磁盤�,而對于分布式集群一般來說是HDFS或NFS�����。
從數據流轉的角度來看��,數據從架構圖的左側進入系統��,分為實時流數據與批量數據��。實時流數據會被實時節點消費���,然后實時節點將生成的Segment數據文件上傳到數據文件存儲庫���;而批量數據經過Druid集群消費后(具體方法后面的章節會做介紹)會被直接上傳到數據文件存儲庫�����。同時���,查詢節點會響應外部的查詢請求���,并將分別從實時節點與歷史節點查詢到的結果合并后返回��。
2.Pinot
如果要找一個與Druid最接近的系統��,那么非LinkedIn Pinot莫屬�����。Pinot是Linkedin公司于2015年底開源的一個分布式列式數據存儲系統����。Linkedin在開源界頗有盛名��,大名鼎鼎的Kafka就是來源于LinkedIn�,因此Pinot在推出后就備受關注和追捧����。
Pinot的技術特點如下:
· 一個面向列式存儲的數據庫���,支持多種壓縮技術+ 可插入的索引技術 – SortedIndex���、Bitmap Index����、Inverted Index
· 可以根據Query和Segment元數據進行查詢和執行計劃的優化
· 從kafka的準實時數據灌入和從hadoop的批量數據灌入
· 類似于SQL的查詢語言和各種常用聚合
· 支持多值字段
· 水平擴展和容錯
在架構上�,Pinot也采用了Lambda的架構����,將實時數據流和批處理數據分開處理��。其中Realtime Node 處理實時數據查詢�����,Historical Nodes處理歷史數據��。
Druid的架構圖顯示Druid自身包含以下四類節點:
· 實時節點(Realtime Node):及時攝入實時數據�����,以及生成Segment數據文件��。
· 歷史節點(Historical Node):加載已生成好的數據文件以供數據查詢���。
· 查詢節點(Broker Node):對外提供數據查詢服務����,并同時從實時節點與歷史節點查詢數據��、合并后返回給調用方�����。
· 協調節點(Coordinator Node):負責歷史節點的數據負載均衡����,以及通過Rules管理數據的生命周期�����。
同時�,集群還包含以下三類外部依賴:
· 元數據庫(Metastore):存儲Druid集群的原數據信息���,比如segment的相關信息��,一般用MySQL或PostgreSQL���。
· 分布式協調服務(Coordination):為Druid集群提供一致性協調服務的組件���,通常為Zookeeper��。
· 數據文件存儲庫(DeepStorage):存放生成的Segment數據文件����,并供歷史節點下載�。
對于單節點集群來說可以是本地磁盤�,而對于分布式集群一般來說是HDFS或NFS�����。
從數據流轉的角度來看��,數據從架構圖的左側進入系統��,分為實時流數據與批量數據��。實時流數據會被實時節點消費���,然后實時節點將生成的Segment數據文件上傳到數據文件存儲庫���;而批量數據經過Druid集群消費后(具體方法后面的章節會做介紹)會被直接上傳到數據文件存儲庫�����。同時���,查詢節點會響應外部的查詢請求���,并將分別從實時節點與歷史節點查詢到的結果合并后返回��。
2.Pinot
如果要找一個與Druid最接近的系統��,那么非LinkedIn Pinot莫屬�����。Pinot是Linkedin公司于2015年底開源的一個分布式列式數據存儲系統����。Linkedin在開源界頗有盛名��,大名鼎鼎的Kafka就是來源于LinkedIn�,因此Pinot在推出后就備受關注和追捧����。
Pinot的技術特點如下:
· 一個面向列式存儲的數據庫���,支持多種壓縮技術+ 可插入的索引技術 – SortedIndex���、Bitmap Index����、Inverted Index
· 可以根據Query和Segment元數據進行查詢和執行計劃的優化
· 從kafka的準實時數據灌入和從hadoop的批量數據灌入
· 類似于SQL的查詢語言和各種常用聚合
· 支持多值字段
· 水平擴展和容錯
在架構上�,Pinot也采用了Lambda的架構����,將實時數據流和批處理數據分開處理��。其中Realtime Node 處理實時數據查詢�����,Historical Nodes處理歷史數據��。
 3.Kylin
Kylin是一個Apache開源的分布式分析引擎��,提供了Hadoop之上的SQL查詢接口及多維分析(OLAP)能力��,可以支持超大規模數據���。最初由eBay公司開發并于2015年貢獻至開源社區��。它能在亞秒內查詢巨大的Hive表�����。
Kylin的優勢很明顯����,它支持標準的ANSI SQL接口�����,可以復用很多傳統的數據集成系統�,支持標準的OLAP Cube�����,數據查詢更加方便���,與大量BI工具無縫整合�。另外它提供很多管理功能����,例如Web管理�,訪問控制���,支持LDAP��,支持HyperLoglog的近似算法�。
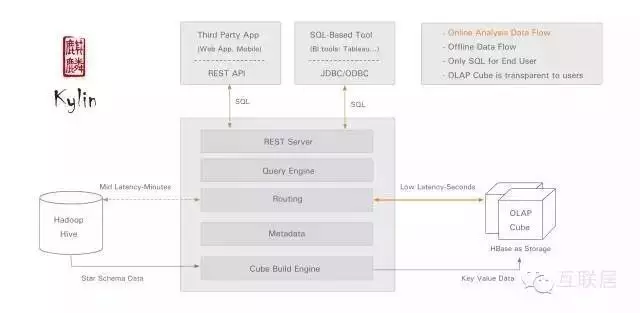
從技術上理解��,Kylin在Hadoop Hive表上做了一層緩存�����,通過預計算和定期任務�����,把很多數據事先存儲在HBase為基礎的OLAP Cube中����,大部分查詢可以直接訪問HBase拿到結果����,而不需訪問Hive原始數據�。雖然數據緩存�、預計算可以提高查詢效率�����,另外一個方面��,這種方式的缺點也很明顯�����,查詢缺乏靈活性��,需要預先定義好查詢的一些模式��,一些表結構�����。目前�,Kylin缺少實時數據注入的能力����。Druid使用Bitmap Index作為統一的內部數據結構���;Kylin使用Bitmap Index作為實時處理部分的數據結構�����,而使用MOLAP Cube為歷史數據的數據結構�����。
3.Kylin
Kylin是一個Apache開源的分布式分析引擎��,提供了Hadoop之上的SQL查詢接口及多維分析(OLAP)能力��,可以支持超大規模數據���。最初由eBay公司開發并于2015年貢獻至開源社區��。它能在亞秒內查詢巨大的Hive表�����。
Kylin的優勢很明顯����,它支持標準的ANSI SQL接口�����,可以復用很多傳統的數據集成系統�,支持標準的OLAP Cube�����,數據查詢更加方便���,與大量BI工具無縫整合�。另外它提供很多管理功能����,例如Web管理�,訪問控制���,支持LDAP��,支持HyperLoglog的近似算法�。
從技術上理解��,Kylin在Hadoop Hive表上做了一層緩存�����,通過預計算和定期任務�����,把很多數據事先存儲在HBase為基礎的OLAP Cube中����,大部分查詢可以直接訪問HBase拿到結果����,而不需訪問Hive原始數據�。雖然數據緩存�、預計算可以提高查詢效率�����,另外一個方面��,這種方式的缺點也很明顯�����,查詢缺乏靈活性��,需要預先定義好查詢的一些模式��,一些表結構�����。目前�,Kylin缺少實時數據注入的能力����。Druid使用Bitmap Index作為統一的內部數據結構���;Kylin使用Bitmap Index作為實時處理部分的數據結構�����,而使用MOLAP Cube為歷史數據的數據結構�����。
 另外����,Kylin開發成員中很多開發人員來自中國�,因此PMC成員中�����,中國人占了大部分�,所以使用Kylin很容易得到很好的中文支持�����。Kylin的愿景就是創建一個分布式的高可擴展的OLAP引擎�。
4.Druid����、Pinot和Kylin比較
Druid�,Pinot和Kylin是數據分析軟件選型經常碰到的問題��。Druid和Pinot解決的業務問題非常類似��。Pinot架構設計比較規范���,系統也比較復雜一些�����,由于開源時間短��,社區的支持力度弱于Druid��。Druid的設計輕巧��,代碼庫也比較容易懂�,支持比較靈活的功能增強����。Kylin的最大優勢是支持SQL訪問��,可以兼容傳統的BI工具和報表系統�,性能上沒有太大優勢�。
下面是這幾個軟件的簡單比較:
另外����,Kylin開發成員中很多開發人員來自中國�,因此PMC成員中�����,中國人占了大部分�,所以使用Kylin很容易得到很好的中文支持�����。Kylin的愿景就是創建一個分布式的高可擴展的OLAP引擎�。
4.Druid����、Pinot和Kylin比較
Druid�,Pinot和Kylin是數據分析軟件選型經常碰到的問題��。Druid和Pinot解決的業務問題非常類似��。Pinot架構設計比較規范���,系統也比較復雜一些�����,由于開源時間短��,社區的支持力度弱于Druid��。Druid的設計輕巧��,代碼庫也比較容易懂�,支持比較靈活的功能增強����。Kylin的最大優勢是支持SQL訪問��,可以兼容傳統的BI工具和報表系統�,性能上沒有太大優勢�。
下面是這幾個軟件的簡單比較:
 5.神秘的Google Dremel
Dremel 是Google 的“交互式”數據分析系統���?�?梢越M建成規模上千的集群�,處理PB級別的數據��。由于Map Reduce的實時性缺陷����,Google開發了Dremel將處理時間縮短到秒級���,作為Map Reduce的有力補充�。Dremel作為Google BigQuery的Report引擎���,獲得了很大的成功�。
Dremel 支持上千臺機器的集群部署�,處理PB級別的數據���,可以對于網狀數據的只讀數據�,進行隨機查詢訪問����,幫助數據分析師提供Ad Hoc查詢功能�����,進行深度的數據探索(Exploration)����。Google開發了Dremel將處理時間縮短到秒級�,它也成為Map Reduce的一個有利補充����。Dremel也應用在Google Big Query的Report引擎�,也非常成功���。Dremel的應用如下��。
· 抓取的網頁文檔的分析�,主要是一些元數據+ 追蹤Android市場的所有安裝數據
· 谷歌產品的Crash報告
· 作弊(Spam)分析
· 谷歌分布式構建(Build)系統中的測試結果
· 上千萬的磁盤 I/O 分析
· 谷歌數據中心中任務的資源分析
· 谷歌代碼庫中的Symbols和依賴分析
· 其他
Google公開的論文《Dremel: Interactive Analysis of WebScaleDatasets》�,總體介紹了一下Dremel的設計原理����。論文寫于2006年�����,公開于2010年����,Dremel為了支持Nested Data����,做了很多設計的優化和權衡��。
Dremel系統有以下幾個主要技術特點:
· Dremel是一個大規模高并發系統����。舉例來說��,磁盤的順序讀速度在100MB/s上下��,那么在1s內處理1TB數據���,意味著至少需要有1萬個磁盤的并發讀��,在如此大量的讀寫�,需要復雜的容錯設計�����,少量節點的讀失?�。ɑ蚵僮鳎┎荒苡绊懻w操作����。
· Dremel支持嵌套的數據結構���。互聯網數據常常是非關系型的�����。Dremel還支持靈活的數據模型��,一種嵌套(Nested)的數據模型��,類似于Protocol Buffer定義的數據結構���。Dremel采用列式方法存儲這些數據�,由于嵌套數據結構��,Dremel引入了一種樹狀的列式存儲結構��,方便嵌套數據的查詢��。論文詳細解釋了嵌套數據類型的列存儲�����,這個特性是Druid缺少的��,實現也是非常復雜的���。
· Dremel采用層級的執行引擎��。Dremel在執行過程中��,SQL查詢輸入會轉化成執行計劃��,并發處理數據����。和MapReduce一樣���,Dremel也需要和數據運行在一起�,將計算移動到數據上面�。所以它需要GFS這樣的文件系統作為存儲層��。在設計之初���,Dremel并非是MapReduce的替代品��,它只是可以執行非?���?斓姆治?����,在使用的時候�,常常用它來處理MapReduce的結果集或者用來建立分析原型��。
在使用Dremel時���,工程師需要通過Map Reduce將數據導入到Dremel����,可以通過定期的MapReduce的定時任務完成導入���。在數據的實時性方面���,論文并沒有討論太多���。
6.Apache Drill
Apache Drill 通過開源方式實現了 Google’s Dremel��。Apache Drill的架構�,整個思想還是通過優化查詢引擎�����,進行快速全表掃描��,以快速返回結果�。
5.神秘的Google Dremel
Dremel 是Google 的“交互式”數據分析系統���?�?梢越M建成規模上千的集群�,處理PB級別的數據��。由于Map Reduce的實時性缺陷����,Google開發了Dremel將處理時間縮短到秒級���,作為Map Reduce的有力補充�。Dremel作為Google BigQuery的Report引擎���,獲得了很大的成功�。
Dremel 支持上千臺機器的集群部署�,處理PB級別的數據���,可以對于網狀數據的只讀數據�,進行隨機查詢訪問����,幫助數據分析師提供Ad Hoc查詢功能�����,進行深度的數據探索(Exploration)����。Google開發了Dremel將處理時間縮短到秒級�,它也成為Map Reduce的一個有利補充����。Dremel也應用在Google Big Query的Report引擎�,也非常成功���。Dremel的應用如下��。
· 抓取的網頁文檔的分析�,主要是一些元數據+ 追蹤Android市場的所有安裝數據
· 谷歌產品的Crash報告
· 作弊(Spam)分析
· 谷歌分布式構建(Build)系統中的測試結果
· 上千萬的磁盤 I/O 分析
· 谷歌數據中心中任務的資源分析
· 谷歌代碼庫中的Symbols和依賴分析
· 其他
Google公開的論文《Dremel: Interactive Analysis of WebScaleDatasets》�,總體介紹了一下Dremel的設計原理����。論文寫于2006年�����,公開于2010年����,Dremel為了支持Nested Data����,做了很多設計的優化和權衡��。
Dremel系統有以下幾個主要技術特點:
· Dremel是一個大規模高并發系統����。舉例來說��,磁盤的順序讀速度在100MB/s上下��,那么在1s內處理1TB數據���,意味著至少需要有1萬個磁盤的并發讀��,在如此大量的讀寫�,需要復雜的容錯設計�����,少量節點的讀失?�。ɑ蚵僮鳎┎荒苡绊懻w操作����。
· Dremel支持嵌套的數據結構���。互聯網數據常常是非關系型的�����。Dremel還支持靈活的數據模型��,一種嵌套(Nested)的數據模型��,類似于Protocol Buffer定義的數據結構���。Dremel采用列式方法存儲這些數據�,由于嵌套數據結構��,Dremel引入了一種樹狀的列式存儲結構��,方便嵌套數據的查詢��。論文詳細解釋了嵌套數據類型的列存儲�����,這個特性是Druid缺少的��,實現也是非常復雜的���。
· Dremel采用層級的執行引擎��。Dremel在執行過程中��,SQL查詢輸入會轉化成執行計劃��,并發處理數據����。和MapReduce一樣���,Dremel也需要和數據運行在一起�,將計算移動到數據上面�。所以它需要GFS這樣的文件系統作為存儲層��。在設計之初���,Dremel并非是MapReduce的替代品��,它只是可以執行非?���?斓姆治?����,在使用的時候�,常常用它來處理MapReduce的結果集或者用來建立分析原型��。
在使用Dremel時���,工程師需要通過Map Reduce將數據導入到Dremel����,可以通過定期的MapReduce的定時任務完成導入���。在數據的實時性方面���,論文并沒有討論太多���。
6.Apache Drill
Apache Drill 通過開源方式實現了 Google’s Dremel��。Apache Drill的架構�,整個思想還是通過優化查詢引擎�����,進行快速全表掃描��,以快速返回結果�。
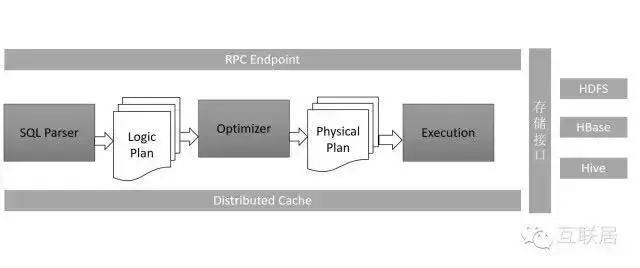 Apache Drill 在基于 SQL 的數據分析和商業智能(BI)上引入了 JSON 文件模型�����,這使得用戶能查詢固定架構���,支持各種格式和數據存儲中的模式無關(schema-free)數據�。該體系架構中關系查詢引擎和數據庫的構建是有先決條件的���,即假設所有數據都有一個簡單的靜態架構����。
Apache Drill 的架構是獨一無二的�����。它是唯一一個支持復雜和無模式數據的柱狀執行引擎(columnar execution engine)��,也是唯一一個能在查詢執行期間進行數據驅動查詢(和重新編譯��,也稱之為 schema discovery)的執行引擎(execution engine)���。這些獨一無二的性能使得 Apache Drill 在 JSON 文件模式下能實現記錄斷點性能(record-breaking performance)�����。該項目將會創建出開源版本的谷歌Dremel Hadoop工具(谷歌使用該工具來為Hadoop數據分析工具的互聯網應用提速)��。而“Drill”將有助于Hadoop用戶實現更快查詢海量數據集的目的���。
目前�,Drill已經完成的需求和架構設計����?��?偣卜譃橐韵滤膫€組件:
· Query language:類似Google BigQuery的查詢語言�����,支持嵌套模型���,名為DrQL���。
· Low-lantency distribute execution engine:執行引擎���,可以支持大規模擴展和容錯�����,并運行在上萬臺機器上計算數以PB的數據���。
· Nested data format:嵌套數據模型�����,和Dremel類似����。也支持CSV�,JSON��,YAML之類的模型���。這樣執行引擎就可以支持更多的數據類型�。
· Scalable data source: 支持多種數據源�����,現階段以Hadoop為數據源����。
7.ElasticSearch
Elasticsearch是Elastic公司推出的一個基于Lucene的分布式搜索服務系統���,它是一個高可靠����、可擴展���、分布式的全文搜索引擎����,下面簡稱ES��,提供了方便的RESTful web接口�。ES采用Java語言開發���,并作為Apache許可條款下的開放源碼發布��,它是流行的企業搜索引擎�。與之類似的軟件還有Solr�����,兩個軟件有一定的相似性���。
ES在前幾年的定位一直是文本的倒排索引引擎����,用于文本搜索的場景��。最近幾年����,Elastic公司將ES用于日志分析和數據的可視化�,慢慢轉成一個數據分析平臺�����。它能夠提供類似于OLAP的一些簡單的Count ���,Group by 功能�����。另外�,套件中內置的Kibana可視化工具提供了出色的交互界面�����,可以對接常用的儀表盤(Dashboard)功能���。因此�,在一些數據量不大�����,需要文本搜索的場景下���,直接使用Elaticsearch作為簡單的數據分析平臺也是快速的解決方案�����。
Elastic主推ELK產品����,它是一個提供數據分析功能的套裝����,包括LogStash:數據收集���、ES:數據索引和 Kibana:可視化表現����。
ES內部使用了Lucence的倒排索引���,每個Term后面都關聯了相關的文檔ID列表�����,這種結構比較適合基數較大的列����,比如人名����,單詞等����。Elasticsearch支持靈活的數據輸入�����,支持無固定格式(Schema Free)的數據輸入����,隨時增加索引����。
相比Druid���,Elaticsearch對于基數大的列能夠提供完美的索引方案�����,例如文本�。Elasticsearch也提供了實時的數據注入功能��,但是性能比Druid要慢很多�,應為它的索引過程更加復雜����。另外一個顯著不同���,ES是Schema Free的�����,也就是說無需定義Schema��,就可以直接插入Json數據��,進行索引�,而且數據結構也支持數組等靈活的數據類型�����。Druid需要定義清楚維度和指標列���。另外一個很大區別��,ES會保持元素的文檔數據�,而Druid在按照時間粒度數據聚合后�,原始數據將會丟棄�����,因此無法找回具體的某一數據行����。
最近幾年�����,ES一直在增加數據分析的能力��,包括各種聚合查詢等����,性能提升也很快�。如果數據規模不大的情況下�,ES也是非常不錯的選擇���。Druid更善于處理更大規模��,實時性更強的數據����。
八�����、SQL on Hadoop/Spark
Hadoop生態發展了多年���,越來越多的公司將重要的日志數據存入Hadoop的HDFS系統中����,數據的持久化和可靠性得到了保證��,但是如何快速挖掘出其中的價值確實很多公司的痛點�。常用的分析過程有以下幾種:
數據從HDFS導入到RDBMS/NoSQL+ 基于HDFS�,寫代碼通過Map Reduce進行數據分析+ 基于HDFS�,編寫SQL直接訪問+ SQL訪問內部轉為Map Reduce任務
訪問引擎直接訪問HDFS文件系統
接下來���,我們來看看簡單的SQL查詢是如何訪問HDFS的����。
1.Hive
Hive是基于Hadoop的一個數據倉庫工具�,可以將結構化的數據文件映射為一張數據庫表�����,并提供簡單的SQL查詢功能�����,可以將sql語句轉換為Map Reduce任務進行運行�����。 其優點是學習成本低��,可以通過類SQL語句快速實現簡單的Map Reduce統計��,不必開發專門的Map Reduce應用�����,十分適合數據倉庫的統計分析�����。 Hive 并不適合那些需要低延遲的應用��,例如����,聯機事務處理(OLTP)�����。Hive 查詢操作過程嚴格遵守Hadoop Map Reduce 的作業執行模型�,整個查詢過程也比較慢�,不適合實時的數據分析��。
幾乎所有的Hadoop環境都會配置Hive的應用�����,雖然Hive易用���,但內部的Map Reduce操作還是帶來非常慢的查詢體驗�。所有嘗試Hive的公司�����,機會都會轉型到Impala的應用�����。
2.Impala
Impala是Cloudera在受到Google的Dremel啟發下開發的實時交互SQL大數據查詢工具�,使用C++編寫�,通過使用與商用MPP類似的分布式查詢引擎(由Query Planner����、Query Coordinator和Query Exec Engine三部分組成)�����,可以直接從HDFS或HBase中用SELECT�����、JOIN和統計函數查詢數據���,從而大大降低了延遲���。 Impala使用的列存儲格式是Parquet����。Parquet實現了Dremel中的列存儲�,未來還將支持 Hive并添加字典編碼���、游程編碼等功能���。 在Cloudera的測試中�����,Impala的查詢效率比Hive有數量級的提升��,因為Impala省去了Map Reduce的過程��,減少了終結結果落盤的問題�。
Apache Drill 在基于 SQL 的數據分析和商業智能(BI)上引入了 JSON 文件模型�����,這使得用戶能查詢固定架構���,支持各種格式和數據存儲中的模式無關(schema-free)數據�。該體系架構中關系查詢引擎和數據庫的構建是有先決條件的���,即假設所有數據都有一個簡單的靜態架構����。
Apache Drill 的架構是獨一無二的�����。它是唯一一個支持復雜和無模式數據的柱狀執行引擎(columnar execution engine)��,也是唯一一個能在查詢執行期間進行數據驅動查詢(和重新編譯��,也稱之為 schema discovery)的執行引擎(execution engine)���。這些獨一無二的性能使得 Apache Drill 在 JSON 文件模式下能實現記錄斷點性能(record-breaking performance)�����。該項目將會創建出開源版本的谷歌Dremel Hadoop工具(谷歌使用該工具來為Hadoop數據分析工具的互聯網應用提速)��。而“Drill”將有助于Hadoop用戶實現更快查詢海量數據集的目的���。
目前�,Drill已經完成的需求和架構設計����?��?偣卜譃橐韵滤膫€組件:
· Query language:類似Google BigQuery的查詢語言�����,支持嵌套模型���,名為DrQL���。
· Low-lantency distribute execution engine:執行引擎���,可以支持大規模擴展和容錯�����,并運行在上萬臺機器上計算數以PB的數據���。
· Nested data format:嵌套數據模型�����,和Dremel類似����。也支持CSV�,JSON��,YAML之類的模型���。這樣執行引擎就可以支持更多的數據類型�。
· Scalable data source: 支持多種數據源�����,現階段以Hadoop為數據源����。
7.ElasticSearch
Elasticsearch是Elastic公司推出的一個基于Lucene的分布式搜索服務系統���,它是一個高可靠����、可擴展���、分布式的全文搜索引擎����,下面簡稱ES��,提供了方便的RESTful web接口�。ES采用Java語言開發���,并作為Apache許可條款下的開放源碼發布��,它是流行的企業搜索引擎�。與之類似的軟件還有Solr�����,兩個軟件有一定的相似性���。
ES在前幾年的定位一直是文本的倒排索引引擎����,用于文本搜索的場景��。最近幾年����,Elastic公司將ES用于日志分析和數據的可視化�,慢慢轉成一個數據分析平臺�����。它能夠提供類似于OLAP的一些簡單的Count ���,Group by 功能�����。另外�,套件中內置的Kibana可視化工具提供了出色的交互界面�����,可以對接常用的儀表盤(Dashboard)功能���。因此�,在一些數據量不大�����,需要文本搜索的場景下���,直接使用Elaticsearch作為簡單的數據分析平臺也是快速的解決方案�����。
Elastic主推ELK產品����,它是一個提供數據分析功能的套裝����,包括LogStash:數據收集���、ES:數據索引和 Kibana:可視化表現����。
ES內部使用了Lucence的倒排索引���,每個Term后面都關聯了相關的文檔ID列表�����,這種結構比較適合基數較大的列����,比如人名����,單詞等����。Elasticsearch支持靈活的數據輸入�����,支持無固定格式(Schema Free)的數據輸入����,隨時增加索引����。
相比Druid���,Elaticsearch對于基數大的列能夠提供完美的索引方案�����,例如文本�。Elasticsearch也提供了實時的數據注入功能��,但是性能比Druid要慢很多�,應為它的索引過程更加復雜����。另外一個顯著不同���,ES是Schema Free的�����,也就是說無需定義Schema��,就可以直接插入Json數據��,進行索引�,而且數據結構也支持數組等靈活的數據類型�����。Druid需要定義清楚維度和指標列���。另外一個很大區別��,ES會保持元素的文檔數據�,而Druid在按照時間粒度數據聚合后�,原始數據將會丟棄�����,因此無法找回具體的某一數據行����。
最近幾年�����,ES一直在增加數據分析的能力��,包括各種聚合查詢等����,性能提升也很快�。如果數據規模不大的情況下�,ES也是非常不錯的選擇���。Druid更善于處理更大規模��,實時性更強的數據����。
八�����、SQL on Hadoop/Spark
Hadoop生態發展了多年���,越來越多的公司將重要的日志數據存入Hadoop的HDFS系統中����,數據的持久化和可靠性得到了保證��,但是如何快速挖掘出其中的價值確實很多公司的痛點�。常用的分析過程有以下幾種:
數據從HDFS導入到RDBMS/NoSQL+ 基于HDFS�,寫代碼通過Map Reduce進行數據分析+ 基于HDFS�,編寫SQL直接訪問+ SQL訪問內部轉為Map Reduce任務
訪問引擎直接訪問HDFS文件系統
接下來���,我們來看看簡單的SQL查詢是如何訪問HDFS的����。
1.Hive
Hive是基于Hadoop的一個數據倉庫工具�,可以將結構化的數據文件映射為一張數據庫表�����,并提供簡單的SQL查詢功能�����,可以將sql語句轉換為Map Reduce任務進行運行�����。 其優點是學習成本低��,可以通過類SQL語句快速實現簡單的Map Reduce統計��,不必開發專門的Map Reduce應用�����,十分適合數據倉庫的統計分析�����。 Hive 并不適合那些需要低延遲的應用��,例如����,聯機事務處理(OLTP)�����。Hive 查詢操作過程嚴格遵守Hadoop Map Reduce 的作業執行模型�,整個查詢過程也比較慢�,不適合實時的數據分析��。
幾乎所有的Hadoop環境都會配置Hive的應用�����,雖然Hive易用���,但內部的Map Reduce操作還是帶來非常慢的查詢體驗�。所有嘗試Hive的公司�����,機會都會轉型到Impala的應用�����。
2.Impala
Impala是Cloudera在受到Google的Dremel啟發下開發的實時交互SQL大數據查詢工具�,使用C++編寫�,通過使用與商用MPP類似的分布式查詢引擎(由Query Planner����、Query Coordinator和Query Exec Engine三部分組成)�����,可以直接從HDFS或HBase中用SELECT�����、JOIN和統計函數查詢數據���,從而大大降低了延遲���。 Impala使用的列存儲格式是Parquet����。Parquet實現了Dremel中的列存儲�,未來還將支持 Hive并添加字典編碼���、游程編碼等功能���。 在Cloudera的測試中�����,Impala的查詢效率比Hive有數量級的提升��,因為Impala省去了Map Reduce的過程��,減少了終結結果落盤的問題�。
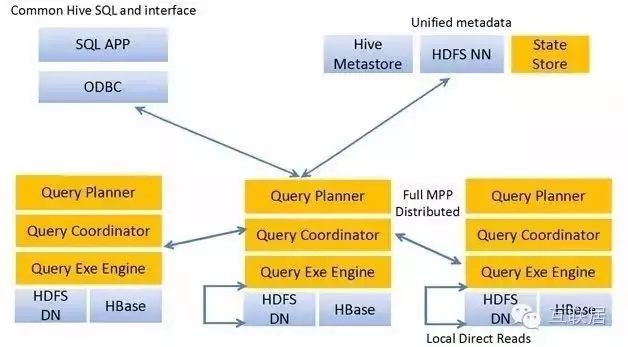 3.Facebook Presto
Presto出生名門���,來自于Facebook����,從出生起就收到關注���。它是用于大數據的一個分布式SQL查詢引擎����,系統主要是Java編寫�����。Presto是一個分布式SQL查詢引擎����,它被設計用于專門進行高速��、實時的數據分析����。它支持標準的ANSI SQL���,包括復雜查詢���、聚合(aggregation)����、連接(join)和窗口函數(window functions)���。下圖展現了簡化的Presto系統架構�。
3.Facebook Presto
Presto出生名門���,來自于Facebook����,從出生起就收到關注���。它是用于大數據的一個分布式SQL查詢引擎����,系統主要是Java編寫�����。Presto是一個分布式SQL查詢引擎����,它被設計用于專門進行高速��、實時的數據分析����。它支持標準的ANSI SQL���,包括復雜查詢���、聚合(aggregation)����、連接(join)和窗口函數(window functions)���。下圖展現了簡化的Presto系統架構�。
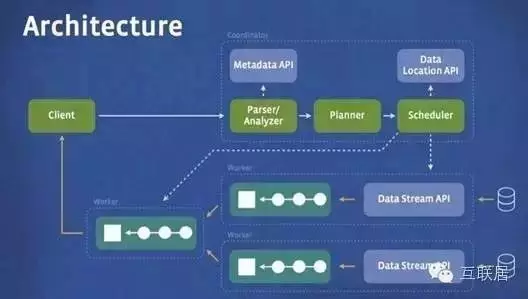
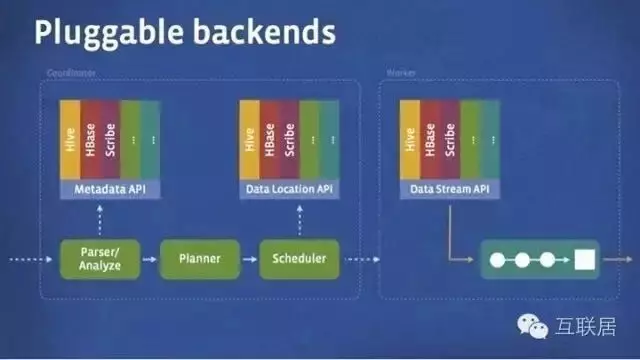
Presto的運行模型和Hive或MapReduce有著本質的區別��。Hive將查詢翻譯成多階段的MapReduce任務�, 一個接著一個地運行�。每一個任務從磁盤上讀取輸入數據并且將中間結果輸出到磁盤上�����。然而Presto引擎沒有使用Map Reduce�。它使用了一個定制的查詢和執行引擎和響應的操作符來支持SQL的語法���。除了改進的調度算法之外�����,所有的數據處理都是在內存中進行的����。通過軟件的優化����,形成處理的流水線���,以避免不必要的磁盤讀寫和額外的延遲�。這種流水線式的執行模型會在同一時間運行多個數據處理段��,一旦數據可用的時候就會將數據從一個處理段傳入到下一個處理段����。這樣的方式會大大的減少各種查詢的端到端響應時間��。
九�、數據分析云服務
1.Amazon RedShift
Amazon Redshift 是一種快速����、完全托管的 PB 級數據倉庫�����,可方便你使用現有的商業智能工具以一種經濟的方式輕松分析所有數據��。 Amazon Redshift 使用列存儲技術改善 I/O 效率并跨過多個節點平行放置查詢����,從而提供快速的查詢性能���。Amazon Redshift 提供了定制的 JDBC 和 ODBC 驅動程序�����,你可以從我們的控制臺的“連接客戶端”選項卡中進行下載��,以使用各種各種大量熟悉的 SQL 客戶端�。你也可以使用標準的 PostgreSQL JDBC 和 ODBC 驅動程序�����。數據加載速度與集群大小��、與 Amazon S3����、Amazon DynamoDB��、Amazon Elastic MapReduce����、Amazon Kinesis 或任何啟用 SSH 的主機的集成呈線性擴展關系���。
2.阿里云數據倉庫服務
分析型數據庫(Analytic DB)�����,是阿里巴巴自主研發的海量數據實時高并發在線分析(Realtime OLAP)云計算服務��,使得您可以在毫秒級針對千億級數據進行即時的多維分析透視和業務探索���。分析型數據庫對海量數據的自由計算和極速響應能力����,能讓用戶在瞬息之間進行靈活的數據探索���,快速發現數據價值�����,并可直接嵌入業務系統為終端客戶提供分析服務�����。
小結
數據分析的世界繁花似錦���,雖然我們可以通過開源/商業�,SaaS/私有部署等方式來分類����,但是每種數據分析軟件都有自己獨特的定位��。大部分組織�,在不同的階段會使用不同的軟件解決業務的問題��,但是業務對于數據分析的根本需求沒有變化:更多的數據�,更快的數據���,更多樣的數據源�����,更有價值的分析結果��,這也是大數據的4V本質�。

對CDA數據分析師系列課程感興趣的同學���,歡迎參加:
http://www.ruiqisteel.com/kecheng.html
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
