數據分析技術:數據的歸納分析
在數據分析中��,除了差異性檢驗����、關聯性研究之外����,基于原始數據開展的研究也是非常重要的����,對原始數據的處理研究被稱為數據歸納分析�。
歸納分析
所謂歸納就是從個別性知識推出一般性結論的推理��。其主要方法是根據一類事物的部分對象具有某種性質����,推出這類事物的所有對象都具有這種性質的推理����。
數據的歸納分析可以從兩個維度進行��。例如����,SPSS的數據視圖��,是一個二維數據表����,數據表的每一行是一個個案����,每一列是一個變量�,數據的歸納分析就是對行和列的抽象與歸納�。對個案的歸納處理是聚類�����,也叫分類�,它以行作為操作單元��,其目標是根據個案的特點把個案劃分為若干類別����。對變量的歸納處理則稱為降維��,它以列作為操作單元�,其目標是根據變量的取值特點把描述變量的眾多屬性壓縮為具有某些特點的幾個屬性����,從而能夠更加清晰的突出個案集的本質特點��。對個案和變量的歸納處理過程就是常說的聚類分析和降維分析�����。
聚類分析
在學習�、工作和科研活動中����,常常需要將數以萬計的個案分成若干類�,以便于操作��。例如�����,可以把人群分為男和女����,還可以把社會人群分為高收入�、中等收入和低收入人群����。依據某些因素�,對個案分類的過程就是分類分析����,也叫聚類分析����,實現分類分析的主要技術:
個案分層聚類
自動分層聚類是分類分析中常見的技術��。在這種聚類分析中�����,首先掃描個案集��,把兩個距離最近的個案歸結為一類��,形成新的個案集���;然后基于新個案集�,重復這個過程����,直到所有個案都被歸結為一個大類為止�����。分層聚類的最終結果是獲得一個只有唯一大類的個案集�?�?梢园逊謱泳垲惪醋饕豢么髽?���,最初的未聚類個案就像散亂的樹葉��。當聚類完成后�,所有的樹葉就被大樹有機地組織起來����,處于不同層次上的樹葉體現了樹葉之間的距離關系���。面向個案的分層聚類�����,被稱為Q聚類�����,是分類分析中非常重要的操作�。
K-Mean聚類分析
K-Mean聚類基于用戶指定的聚類類別數��、類別中心點��,開始聚類過程����。當然�����,如果用戶預先不能提供類別中心點�����,也可由系統自動迭代生產�����。
判別分析
判別分析的過程是基于已有數據集制作分類規則的過程��?�;舅悸肥?�,用戶已有若干已經完成分類且類別號清晰的個案��,由系統借助一些因素變量和已有分類號創建判別規則��,構造判別函數����。然后����,系統就能基于判別函數對未來的個案實現自動分類�����。判別分析過程實際上是系統主動探索與學習的過程����,然后依據已經習得的規則��,對其它個案進行判定其歸屬類別�。在判別分析中�����,創建判別函數并分析判別函數的質量��,是判別分析的重要任務��。
降維分析
降維分析是面向變量的歸納����,其目的是把數據表中的若干相關變量集合在一起��,形成歸一化的結論��,從而減少數據表中列的數量�����,這樣就能從變量集中抽象出公共的因素���,以便獲得比較有價值的研究結論�。對變量的降維有兩種不同技術:其一是對變量的歸類���,借助變量分類的技術實現降維�����;其二是抽取公共因子��,通過抽取公共因子的方式實現同質變量的降維��。降維分析的常見手段:
主成分分析
主成分分析是因子分析中的一種�����。其基本思路是假設在若干變量內部隱藏著能夠表達這些變量語義的若干個公共因子�,主成分分析的目標就是找到這些公共因子����,然后利用遠比變量個數少的公共因子來表達原來變量所描述的語義�。主成分分析的目標是找到影響全體變量項的一個或多個主成分�。
面向變量的聚類分析
針對具有眾多變量的調研數據��,可以借助自動分類聚類的技術��,對變量進行聚類���,把眾多變量劃分為若干小組��,形成幾個聚結的變量集���,然后分析每個變量集的語義���,形成聚結的維度����。面向變量的分層聚類分析���,也叫R聚類����,也能解決研究問題的降維問題����。
對應分析
對于調研數據來講�,綜合性的結論通常與全體變量的取值有關系���。但是�,某些情況下�,某一特定變量的取值在一定程度上直接影響著最終結果���。對應分析就是找出相關的兩個變量之間取值的對應關系����,以便能夠借助一個比較簡單的因素變量��,能夠對最終結果快速做出判定�。
聚類分析距離的判定
由于聚類分析(包括Q聚類和R聚類)是以元素(個案或變量)之間的距離作為是否聚合的判定依據的�����,所以在聚類分析中�����,對元素間距離的判定就顯得非常重要����。對于元素間距離的判定�����,主要包括兩個方面的內容:
個案(變量)之間距離的測定��;
個案團(變量團)之間距離的測定�;
個案(變量)之間距離的測定
由于聚類分析中的每個個案(或變量)都是包含著多個屬性取值的多維結構體�����,可以看做是多維空間中的一個結點����。對于已經明確了多維坐標值的兩個結點�,如何來衡量它們之間的距離呢��?
定距變量之間距離的度量
1����、歐式距離
歐式距離(Euclidean distance)以坐標點之間的直線距離作為其結果�,在三維坐標系下�����,其計算公式為:

2����、平方歐式距離
平方歐式距離���,即歐式距離的平方��,其公式為:
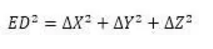
3�����、余弦距離
余弦距離是兩個結點夾角的余弦值���,代表結點之間的距離���。其計算公式為:
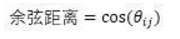
4����、皮爾遜相關系數
5��、切比雪夫距離
切比雪夫(Chebyhev)距離是用結點中的最大差值的絕對值作為兩個元祖之間的距離���。
6����、塊距離
塊距離以兩個結點中所有對應數據的差值的絕對值之和來表示兩個結點之間的距離�。
7�����、明可夫斯基距離
明可夫斯基距離是對歐式距離的改進�����,其公式是
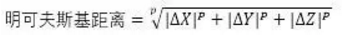
當P=1時��,此公式退化為塊距離公式�����,當P=2時�����,此公式退化為歐式距離公式�。
8����、自定義“設定距離”公式
自定義“設定距離”公式是對明可夫斯基距離的復雜化���。
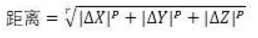
當r=p時�����,此公式退化為明可夫斯基距離公式���,當r=p=2時����,此公式就是歐式距離公式�����。
對定序變量之間距離的度量
1���、卡方距離
用卡方測量兩個個案或變量在總頻數分布期望值方面的獨立性���,它以卡方值的平方根充當距離值��,是一種基于頻數的距離計算方法�����。
2�����、Φ方測量
測量兩個個案或變量在總聘書分布期望值方面的獨立性�,它以Φ統計量的平方根充當元素間的距離�����,其實質是以卡方值的平方根除以合并頻率的平方根�����,是對卡方距離的改進�����。
3�����、對二分變量之間距離的度量
對于只有兩個取值的二分元素�����,如果要計算它們之間的距離����,常常選用歐式距離或平方歐式距離�。
對個案團或變量團之間距離的測定
在分層聚類過程中��,隨著聚類進程的進展�����,很多元素都包含了多個個案(變量)���,變成了個案團或變量團�,那么應該如何確定它們之間的距離呢����?
1��、組間聯結
計算兩個團內所有個案或變量之間的距離�����,以所有距離的均值作為元素之間的距離����。在聚類過程中��,從所有尚待聚類的元素中�,取元素間距離最小的兩個元素進行合并���。
2�����、組內聯結
先假設待合并的兩個團已經合并起來���,然后計算新元素內每對個案或變量之間的距離���,以所有個案對或變量對的距離的平均值作為這兩個元素之間的距離����。
3��、最近鄰元素
以兩個團內部距離最近的個案或變量之間的處理作為兩元素之間的距離����。
4�、最遠鄰距離
5���、質心聚類法
質心聚類法是先確定每個元素的重心位置��,以重心位置之間的距離作為兩元素之間的距離��。
6�、中位數聚類法
先確定每個元素的中位數���,以中位數之間的距離作為兩元素之間的距離���。
7����、Wald方法
離差平方和法�����,若某兩個元素合并后其內部各個個案或變量距離的離差平方和最小�����,則這兩個元素可以合并�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
