機器學習經典算法詳解及Python實現
聚類是一種無監督的學習(無監督學習不依賴預先定義的類或帶類標記的訓練實例)��,它將相似的對象歸到同一個簇中���,它是觀察式學習��,而非示例式的學習���,有點像全自動分類�。
說白了��,聚類 (clustering)是完全可以按字面意思來理解的——將相同����、相似����、相近��、相關的對象實例聚成一類的過程�����。機器學習中常見的聚類算法包括 k-Means算法���、期望最大化算法(Expectation Maximization�����,EM��,參考“EM算法原理”)�����、譜聚類算法(參考機器學習算法復習-譜聚類)以及人工神經網絡算法�����,本文闡述的是K-均值聚類算法����,本文介紹K-均值(K-means)和二分K-均值聚類算法�����。
機器學習經典算法詳解及Python實現–K近鄰(KNN)算法
機器學習經典算法詳解及Python實現–線性回歸(Linear Regression)算法
機器學習經典算法詳解及Python實現–決策樹(Decision Tree)
機器學習經典算法詳解及Python實現–CART分類決策樹�����、回歸樹和模型樹
(一)何謂聚類
還是那句“物以類聚�����、人以群分”���,如果預先知道人群的標簽(如文藝��、普通���、2B)���,那么根據監督學習的分類算法可將一個人明確的劃分到某一類�;如果預先不知道人群的標簽��,那就只有根據人的特征(如愛好�、學歷���、職業等)劃堆了��,這就是聚類算法��。
聚類是一種無監督的學習(無監督學習不 依賴預先定義的類或帶類標記的訓練實例)�����,它將相似的對象歸到同一個簇中��,它是觀察式學習�,而非示例式的學習��,有點像全自動分類�。
所謂簇就是該集合中的對 象有很大的相似性����,而不同集合間的對象有很大的相異性�。簇識別(cluster identification)給出了聚類結果的含義�����,告訴我們這些簇到底都是些什么���。通常情況下��,簇質心可以代表整個簇的數據來做出決策����。聚類方法幾乎 可以應用于所有對象����,簇內的對象越相似��,聚類的效果越好�。
從機器學習的角度講��,簇相當于隱藏模式�����,聚類與分類的最大不同在于���,分類學習的實例或數據對象有類別標記���,而聚類則不一樣�,需要由聚類學習算法自動 確定標記�。因為其產生的結果與分類相同����,而只是類別沒有預先定義�,所以聚類也被稱為無監督分類(unsupervised classification )�。
聚類分析是一種探索性的分析�����,在分類的過程中�����,人們不必事先給出一個分類的標準����,聚類分析能夠從樣本數據出發�����,自動進行 分類��。聚類分析所使用方法的不同���,常常會得到不同的結論����。不同研究者對于同一組數據進行聚類分析���,所得到的聚類數未必一致����。
從實際應用的角度看�����,聚類分析 是數據挖掘的主要任務之一���。而且聚類能夠作為一個獨立的工具獲得數據的分布狀況�����,觀察每一簇數據的特征�,集中對特定的聚簇集合作進一步地分析����。聚類分析還 可以作為其他算法(如分類和定性歸納算法)的預處理步驟��。
聚類分析試圖將相似對象歸入同一簇�����,將不相似對象歸到不同簇����,那么是否“相似”就要有所選擇的相似度計算方法?���,F在�,存在多種不同的相似度計算方 法��,到底使用哪種相似度計算方法取決于具體應用�����,選擇合適的相似度計算方法才會提高聚類算法的性能����。機器學習中常用的相似性度量方法參考博文“機器學習中的相似性度量”�。
聚類算法通常按照中心點或者分層的方式對輸入數據進行歸并��,所以的聚類算法都試圖找到數據的內在結構���,以便按照最大的共同點將數據進行歸類���,其目標 是使同一類對象的相似度盡可能地大��;不同類對象之間的相似度盡可能地小��。
目前聚類的方法很多�����,根據基本思想的不同�,大致可以將聚類算法分為五大類:層次聚 類算法����、分割聚類算法�����、基于約束的聚類算法��、機器學習中的聚類算法和用于高維度的聚類算法��,參考“各種聚類算法的比較”�����。聚類算法的基本過程包含特征選擇�、相似性度量�����、聚類準則�����、聚類算法和結果驗證等���,具體參考“聚類算法學習筆記(一)——基礎”����。
說白了�,聚類(clustering)是完全可以按字面意思來理解的——將相同�����、相似����、相近���、相關的對象實例聚成一類的過程��。簡單理解�,如果一個數 據集合包含N個實例�����,根據某種準則可以將這N個實例劃分為m個類別��,每個類別中的實例都是相關的��,而不同類別之間是區別的也就是不相關的���,這就得到了一個 聚類模型了�。判別新樣本點的所屬類時����,就通過計算該點與這m個類別的相似度�,選擇最相似的那個類作為該點的歸類���。
既然聚類可以看做是一種無監督分類��,那么其應用場景就是廣泛的�����,包括用戶群劃分����、文本分類����、圖像識別等等��。當幾乎沒有有關數據的先驗信息(如統計模 型)可用�,而用戶又要求盡可能地對數據的可能性少進行假設等限制條件下���,聚類方法都適合用來查看數據點中的內在關系以對它們的結構進行評估�、決策����。
機器學習中常見的聚類算法包括 k-Means算法��、期望最大化算法(Expectation Maximization�����,EM���,參考“EM算法原理”)����、譜聚類算法(參考機器學習算法復習-譜聚類)以及人工神經網絡算法��,本文介紹K-均值(K-means)聚類算法����。
(二)K-均值(K-means)聚類算法
1. 認識K-均值聚類算法
K-均值算法是最簡單的一種聚類算法����,屬于分割式聚類算法��,目的是使各個簇(共k個)中的數據點與所在簇質心的誤差平方和SSE(Sum of Squared Error)達到最小����,這也是評價K-means算法最后聚類效果的評價標準�����。
k-means算法的基礎是最小誤差平方和準則���。其代價函數是:
![]()
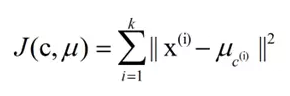
式中�����,μc(i)表示第i個簇的質心����,我們希望得到的聚類模型代價函數最小���,直觀的來說���,各簇內的樣本越相似�����,其與該簇質心 的誤差平方越小����。計算所有簇的誤差平方之和�,即可驗證分為k個簇時時的聚類是否是最優的����。SSE值越小表示數據點越接近于它們的質心���,聚類效果也越好��。因 為對誤差取了平方���,因此更加重視那些遠離中心的點��。
一種肯定可以降低SSE值的方法是增加簇的個數�,但這違背了聚類的目標���,聚類的目標是在保持族數目不變 的情況下提高簇的質量�����。
k-均值(k-means)聚類算法之所以稱之為k-均值是因為它可以發現k個不同的簇�����,且每個簇的中心采用簇中所含子數據集樣本特征的均值計算而 成���。k-均值是發現給定數據集的k個簇的算法����,簇個數k由用戶給定�,每一個簇通過其質心( centroid) — 即簇中所有點的中心來描述�����。K-均值聚類算法需要數值型數據來進行相似性度量�,也可以將標稱型數據映射為二值型數據再用于度量相似性��,其優點是容易實現���, 缺點是可能收斂到局部最小值����,在大規模數據集上收斂較慢����。
假設訓練樣本數據集X為(m, n)維矩陣��,m表示樣本數��、n表示每個樣本點的特征數��,那么k-均值聚類算法的結果就是得到一個kxn維矩陣�,k表示用戶指定的簇個數�����,每一行都是一個長 度為n的行向量–第i個元素就是該簇中所有樣本第j(j=0,1,…,n-1)個特征的均值�。下圖是K-均值聚類算法聚類的過程:
![]()
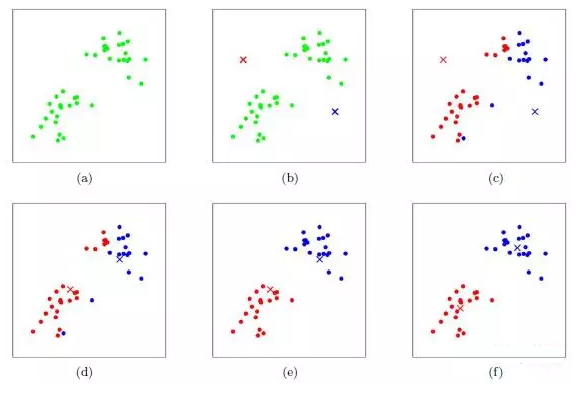
2. 算法過程
K-均值算法的工作流程是這樣的�����。首先��,隨機確定k個初始點作為質心�����;然后將數據集中的每個點分配到一個簇中–就是為每個點找距其最近的質心�����,并將 其分配給該質心所對應的簇����;該步完成之后更新每個簇的質心(該簇所有數據樣本特征的平均值)���;
上述過程迭代多次直至所有數據點的簇歸屬不再改變或者達到了 最大迭代次數Maxiteration��。k-均值算法的性能會受到所選相似性度量方法的影響�����,常用的相似性度量方法就是計算歐氏距離��。上述過程的偽代碼表 示如下:
***************************************************************
創建k個點作為起始質心
任意點的簇分配結果發生改變時(循環內設置�����、維護標志位changed���,也可同時設定最大迭代次數max)
對數據集中的每個數據點
對每個質心
計算質心與數據點之間的距離
將數據點分配到距其最近的簇(若有點的簇發生改變則置標志位為changed = True)
更新簇中心: 對每一個簇����,計算簇中所有點的均值并將均值作為質心
***************************************************************
上述循環的終止條件是每個點的簇分配結果沒有發生改變或者達到了最大循環次數�。
初始化時k個質心的選擇可以是隨機的�����,但為了提高性能常用的方式是
(1)盡量選擇距離比較遠的點(方法:依次計算出與已確定的點(第一個點可以隨機選擇)的距離����,并選擇距離最大的點)��。當k比較大時�����,這種方法計算量比較復雜��,適合二分K-均值聚類算法的k值初始化��。
(2)采取層次聚類的方式找出k個簇���。 TBD
3. 特征值處理
K-均值聚類算法需要數值型數據來進行相似性度量�����,也可以將標稱型數據映射為二值型數據再用于度量相似性��。
另外��,樣本會有多個特征����,每一個特征都有自己的定義域和取值范圍���,他們對distance計算的影響也就不一樣��,如取值較大的影響力會蓋過取值較小 的參數�����。為了公平����,樣本特征取值必須做一些scale處理��,最簡單的方式就是所有特征的數值都采取歸一化處置�,把每一維的數據都轉化到0,1區間內��,從而 減少迭代次數�,提高算法的收斂速度���。
4. k值的選取
前面提到�����,在k-均值聚類中簇的數目k是一個用戶預先定義的參數��,那么用戶如何才能知道k的選擇是否正確����?如何才能知道生成的簇比較好呢���?與K-近鄰分類算法的k值確定方法一樣,k-均值算法也可采用交叉驗證法確定誤差率最低的k值�,參考“機器學習經典算法詳解及Python實現–K近鄰(KNN)算法”的2.3節-k值的確定���。
當k的數目低于真實的簇的數目時�,SSE(或者平均直徑等其他分散度指標)會快速上升����。所以可以采用多次聚類��,然后比較的方式確定最佳k值�����。多次聚 類���,一般是采用 k=1, 2, 4, 8… 這種二分數列的方式���,通過交叉驗證找到一個k在 v/2, v 時獲取較好聚類效果的v值���,然后繼續使用二分法���,在 [v/2, v] 之間找到最佳的k值����。
5. K-均值算法的Python實現
下載地址:TBD
K-均值算法收斂但聚類效果較差的原因是�,K-均值算法收斂到了局部最小值����,而非全局最小值(局部最小值指結果還可以但并非最好結果�,全局最小值是 可能的最好結果)����。為克服k-均值算法收斂于局部最小值的問題���,有人提出了另一個稱為二分k- 均值(bisecting K-means)的算法�。
(三)二分K-均值(bisecting k-means)聚類算法
顧名思義�,二分K-均值聚類算法就是每次對數據集(子數據集)采取k=2的k-均值聚類劃分�����,子數據集的選取則有一定的準則��。二分K-均值聚類算法 首先將所有點作為一個簇�,第一步是然后將該簇一分為二����,之后的迭代是:在所有簇中根據SSE選擇一個簇繼續進行二分K-均值劃分��,直到得到用戶指定的簇數 目為止�����。根據SSE選取繼續劃分簇的準則有如下兩種:
(1)選擇哪一個簇進行劃分取決于對”其劃分是否可以最大程度降低SSE的值����。這需要將每個簇都進行二分劃分���,然后計算該簇二分后的簇SSE之和并計算其與二分前簇SSE之差(當然SSE必須下降)����,最后選取差值最大的那個簇進行二分�。
該方案下的二分k-均值算法的偽代碼形式如下:
***************************************************************
將所有數據點看成一個簇
當簇數目小于k時
對每一個簇
計算總誤差
在給定的簇上面進行k-均值聚類(k=2)
計算將該簇一分為二后的總誤差
選擇使得誤差最小的那個簇進行劃分操作
***************************************************************
(2)另一種做法是所有簇中選擇SSE最大的簇進行劃分���,直到簇數目達到用戶指定的數目為止�,算法過程與(1)相似�����,區別僅在于每次選取簇中SSE最大的簇�。
二分K-均值聚類算法的Python實現
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
