說說什么是數據挖掘
數據挖掘就是指從數據中獲取知識���。
好吧�,這樣的定義方式比較抽象�,但這也是業界認可度最高的一種解釋了���。對于如何開發一個大數據環境下完整的數據挖掘項目�����,業界至今仍沒有統一的規范��。說白了�,大家都聽說過大數據���、數據挖掘等概念���,然而真正能做而且做好的公司并不是很多�����。
筆者本人曾任職于A公司云計算事業群的數據引擎團隊�����,有幸參與過幾個比較大型的數據挖掘項目��,因此對于如何實施大數據場景下的數據挖掘工程有一些小小的心得���。但由于本系列博文主要是結合傳統數據挖掘理論和筆者自身在A云的一些實踐經歷���,因此部分觀點會有較強主觀性���,也歡迎大家來跟我探討�����。
數據挖掘背后的哲學思想
在過去很多年�,首要原則模型(first-principle models)是科學工程領域最為經典的模型���。
比如你要想知道某輛車從啟動到速度穩定行駛的距離�����,那么你會先統計從啟動到穩定耗費的時間�����、穩定后的速度���、加速度等參數����;然后運用牛頓第二定律(或者其他物理學公式)建立模型�;最后根據該車多次實驗的結果列出方程組從而計算出模型的各個參數����。通過該過程����,你就相當于學習到了一個知識 --- 某輛車從啟動到速度穩定行駛的具體模型�。此后往該模型輸入車的啟動參數便可自動計算出該車達到穩定速度前行駛的距離�。
然而���,在數據挖掘的思想中��,知識的學習是不需要通過具體問題的專業知識建模�����。如果之前已經記錄下了100輛型號性能相似的車從啟動到速度穩定行駛的距離����,那么我就能夠對這100個數據求均值��,從而得到結果�。顯然��,這一過程是是直接面向數據的���,或者說我們是直接從數據開發模型的�����。
這其實是模擬了人的原始學習過程 --- 比如你要預測一個人跑100米要多久時間���,你肯定是根據之前了解的他(研究對象)這樣體型的人跑100米用的多少時間做一個估計����,而不會使用牛頓定律來算��。
數據挖掘的起源
由于數據挖掘理論涉及到的面很廣���,它實際上起源于多個學科��。如建模部分主要起源于統計學和機器學習�����。統計學方法以模型為驅動�,常常建立一個能夠產生數據的模型����;而機器學習則以算法為驅動���,讓計算機通過執行算法來發現知識�。仔細想想�,"學習"本身就有算法的意思在里面嘛����。
然而數據挖掘除了建模外����,還有不少其他要做的工作(本文后面會一一講到)�����,因此涉及到不少其他知識����,如下圖所示:
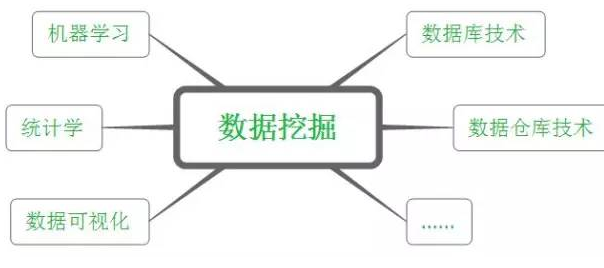
數據挖掘的基本任務
數據挖掘的兩大基本目標是預測和描述數據���。其中前者的計算機建模及實現過程通常被稱為監督學習(supervised learning)��,后者的則通常被稱為無監督學習(supervised learning)�。往更細分�����,數據挖掘的目標可以劃分為以下這些:
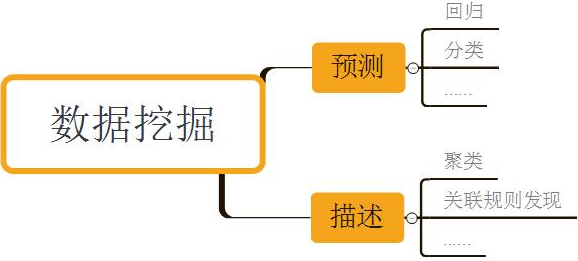
預測主要包括分類 - 將樣本劃分到幾個預定義類之一�,回歸 - 將樣本映射到一個真實值預測變量上�����;描述主要包括聚類 - 將樣本劃分為不同類(無預定義類)����,關聯規則發現 - 發現數據集中不同特征的相關性�����。本系列其他文章將會分別對這些工作深入進行講解�����,如果讀者是第一次接觸這些概念請不要糾結�。
數據挖掘的基本流程
從形式上來說�,數據挖掘的開發流程是迭代式的����。開發人員通過如下幾個階段對數據進行迭代式處理:
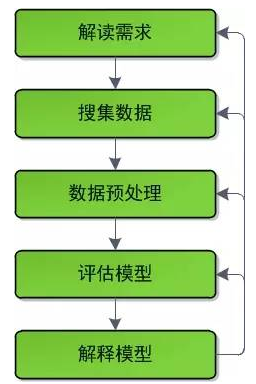
其中�����,
1. 解讀需求
絕大多數的數據挖掘工程都是針對具體領域的�����,因此數據挖掘工作人員不應該沉浸在自己的世界里YY算法模型�,而應該多和具體領域的專家交流合作以正確的解讀出項目需求����。這種合作應當貫穿整個項目生命周期���。
2. 搜集數據
在大型公司���,數據搜集大都是從其他業務系統數據庫提取��。很多時候我們是對數據進行抽樣����,在這種情況下必須理解數據的抽樣過程是如何影響取樣分布���,以確保評估模型環節中用于訓練(train)和檢驗(test)模型的數據來自同一個分布�。
3. 預處理數據
預處理數據可主要分為數據準備和數據歸約兩部分��。其中前者包含了缺失值處理�����、異常值處理��、歸一化����、平整化��、時間序列加權等���;而后者主要包含維度歸約�����、值歸約����、以及案例歸約��。后面兩篇博文將分別講解數據準備和數據歸約��。
4. 評估模型
確切來說�����,這一步就是在不同的模型之間做出選擇����,找到最優模型�����。很多人認為這一步是數據挖掘的全部�,但顯然這是以偏概全的�����,甚至絕大多數情況下這一步耗費的時間和精力在整個流程里是最少的��。
5. 解釋模型
數據挖掘模型在大多數情況下是用來輔助決策的�,人們顯然不會根據"黑箱模型"來制定決策�。如何針對具體環境對模型做出合理解釋也是一項非常重要的任務�。
數據挖掘的工程架構
回到本文開頭提到的那個問題�����,“如何開發一個大數據環境下完整的數據挖掘項目����?”�����。這個問題每個公司有自己的答案����,這里僅以A公司的情況進行介紹����。
在A公司的數據引擎團隊中�,主要人員分成A�、B����、C��、D四個大組���。這四個大組的分工非常明確���,如下圖所示:
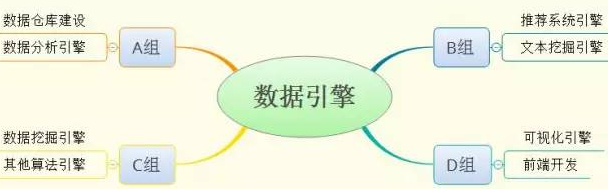
圖中的這些個數據引擎架構在一個基于維度建模的云數據倉庫之上��,并對上層應用提供算法支撐�����、推薦支撐�����、可視化支撐等等�。這里也能看出A公司的數據挖掘工程架構主要由三大塊組成:底層數據倉庫�����、中間數據引擎�����、高層可視化/前端輸出��。很多小伙伴問我����,你是一名數據挖掘工程師呀���,可為什么你前面的博文都是數據倉庫和數據可視化呢����?我想如果他們看到這里想必不會有此疑問了:)���。
至于這些引擎的具體作用�、開發方法����,體系結構等則由于涉及公司秘密不能深入細說��,請各位讀者見諒����。
小結
數據挖掘涵蓋的面非常大����,本文僅旨在讓讀者對數據挖掘有一個感性的認識��。關于什么是數據挖掘如果讀者還不清楚的話也不要糾結�,跟著本系列一起學習一定能有所收獲并會最終發現:數據挖掘是一門非常有趣的學問���,比單純的寫代碼要有意思多了�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
