SPSS—非線性回歸(模型表達式)案例解析
由簡單到復雜���,人生有下坡就必有上坡�����,有低潮就必有高潮的迭起��,隨著SPSS的深入學習�,已經逐漸開始走向復雜�����,今天跟大家交流一下��,SPSS非線性回歸�,希望大家能夠指點一二�����!
非線性回歸過程是用來建立因變量與一組自變量之間的非線性關系�,它不像線性模型那樣有眾多的假設條件�,可以在自變量和因變量之間建立任何形式的模型
非線性�,能夠通過變量轉換成為線性模型——稱之為本質線性模型���,轉換后的模型���,用線性回歸的方式處理轉換后的模型�����,有的非線性模型并不能夠通過變量轉換為線性模型�����,我們稱之為:本質非線性模型
還是以“銷售量”和“廣告費用”這個樣本為例����,進行研究���,前面已經研究得出:“二次曲線模型”比“線性模型”能夠更好的擬合“銷售量隨著廣告費用的增加而呈現的趨勢變化”�,那么“二次曲線”會不會是最佳模型呢�����?
答案是否定的�,因為“非線性模型”能夠更好的擬合“銷售量隨著廣告費用的增加而呈現的變化趨勢” 下面我們開始研究:
第一步:非線性模型那么多�����,我們應該選擇“哪一個模型呢�?”
1:繪制圖形�����,根據圖形的變化趨勢結合自己的經驗判斷�����,選擇合適的模型
點擊“圖形”—圖表構建程序—進入如下所示界面:
點擊確定按鈕��,得到如下結果:
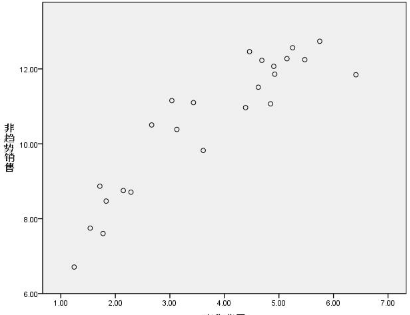
放眼望去, 圖形的變化趨勢�����,其實是一條曲線�,這條曲線更傾向于”S” 型曲線���,我們來驗證一下�,看“二次曲線”和“S曲線”相比����,兩者哪一個的擬合度更高�����!
點擊“分析—回歸—曲線估計——進入如下界面
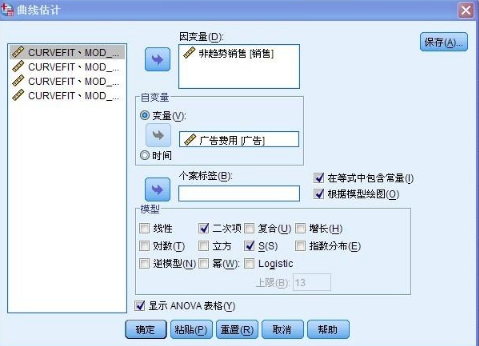
在“模型”選項中����,勾選”二次項“和”S” 兩個模型���,點擊確定��,得到如下結果:
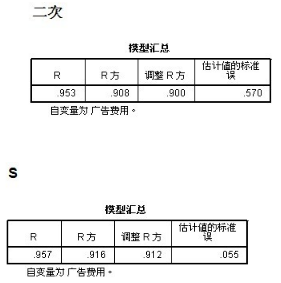
通過“二次”和“S “ 兩個模型的對比����,可以看出S 模型的擬合度 明顯高于“二次”模型的擬合度 (0.912 >0.900)不過�,幾乎接近
接著����,我們采用S 模型����,得到如下所示的結果:
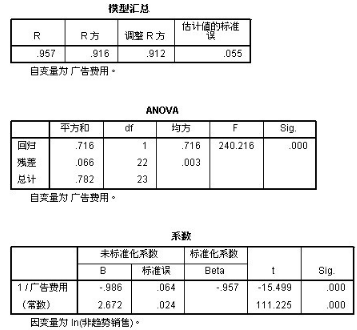
結果分析:
1:從ANOVA表中可以看出:總體誤差= 回歸平方和 + 殘差平方和 (共計:0.782) F統計量為(240.216)顯著性SIG為(0.000)由于0.000<0.01 (所以具備顯著性���,方差齊性相等)
2:從“系數”表中可以看出:在未標準化的情況下��,系數為(-0.986) 常數項為2.672
所以 S 型曲線的表達式為:Y(銷售量)=e^(b0+b1/t) = e^(2.672-0.986/廣告費用)
當數據通過標準化處理后���,常數項被剔除了�����,所以標準化的S型表達式為:Y(銷售量) = e^(-0.957/廣告費用)
下面�,我們直接采用“非線性”模型來進行操作
第一步:確定“非線性模型”
從繪圖中可以看出:廣告費用在1千萬——4千多萬的時候�����,銷售量增加的跨度較大���,當廣告費用超過“4千多萬”的時候���,增加幅度較小�,在達到6千多萬”達到頂峰����,之后呈現下降趨勢����。
從圖形可以看出:它符合The asymptotic regression model (漸近回歸模型)
表達式為:Y(銷售量)= b1 + b2*e∧b3*(廣告費用)
當b1>0, b2<0, and b3<0,時�����,它符合效益遞減規律�,我們稱之為:Mistcherlich’s model
第二步:確定各參數的初始值
1:b1參數值的確定�,從表達式可以看出:隨著”廣告費用“的增加�����,銷售量也會增加���,最后達到一個峰值�����,由于:b2<0, b3<0 ���,隨著廣告費用的增加:b2*e∧b3*(廣告費用)會逐漸趨向于“0” 而此時 Y(銷售量)將接近于 b1值�����,從上圖可以看出:Y(銷售量)的最大值為12點多�,接近13����,所以��,我們設定b1的初始值為13
2:b2參數值確定:當Y(銷售量)最小時���,此時應該廣告費用最小����,基本等于“0”���,可以得出:b1+b2= Y(銷售量)此時Y銷售量最小����,從圖中可以看出:第一個值為6.7左右��,接近7這個值���,所以:b2=7-13=-6
3: b3參數值確定:可以用圖中兩個分離點的斜率來確定b3的值�,例如?。▁1=2.29,y1=8.71) 和( x2=5.75, y2=12.74) 通過公式 y2-y1/x2-x1=1.16�����,(此處可以去整數估計值來算b3的值)
確定參數初始值和參數范圍的方法如下所示:
1:通過圖形確定參數的取值范圍���,然后在這個范圍里選擇初始值��。
2:根據非線性方程的數學特性進行某些變換后�,再通過圖形幫助判斷初始值的范圍����。
3:先使用固定的數代替某些參數�����,以此來確定其它參數的取值范圍�。
4:通過變量轉換��,使用線性回歸模型來估計參數的初始值
第三步:建立模型表達式和選擇損失函數
點擊“分析”—回歸——非線性���,進入如下所示界面:
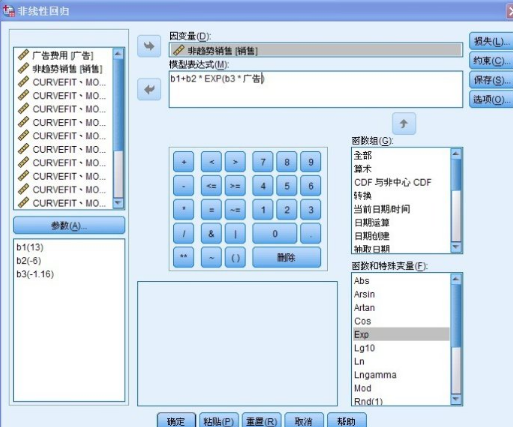
如上圖中��,點擊參數����,分別添加b1,b2,b3進入參數框內����,在模型表達式中輸入:b1 + b2*Exp(b3*廣告費用)(步驟為:選擇“函數組”—算術——Exp函數)���,將“銷售量”變量拖入“因變量”框內
“損失函數”默認選項為“殘差平方和” 如果有特需要求�����,可以自行定義
點擊“約束”進入如下所示的界面:
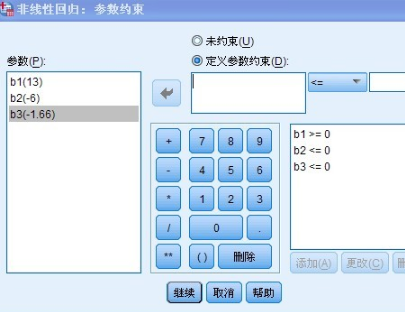
點擊“繼續”按鈕�����,此時會彈出警告信息��,提示用戶是否接受建議, 建議內容為:將采用序列二次編程進行參數估計��,點擊確定�����,接受建議即可
參數的取值范圍指在迭代過程中���,將參數限制在有意義的范圍區間內����,提供兩種對參數范圍約束的方法:
1:線性約束�����,在約束表達式里只有對參數的線性運算
2:非線性約束���,在約束表達式里�����,至少有一個參數與其它參數進行了乘��,除運算�,或者自身的冪運算
在“保存”選項中��,勾選“預測值”和“殘差”即可��,點擊繼續
點擊“選項”得到如下所示的界面:
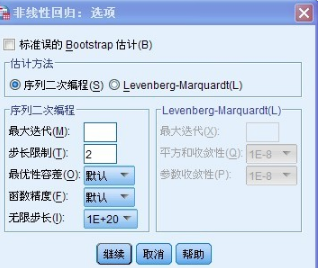
此處的“估計方法”選擇“序列二次編程”的方法�����,此方法主要利用的是雙重迭代法進行求解���,每一步迭代都建立一個二次規劃算法���,以此確定優化的方向�����,把估計參數不斷的帶入損失函數進行求值運算�����,直到滿足指定的收斂條件為止
點擊繼續���,再點擊“確定”得到如下所示的結果:
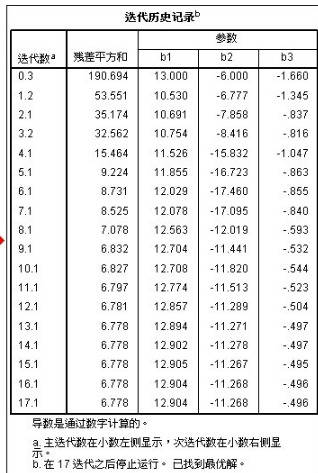

上圖結果分析:
1:從“迭代歷史記錄”表中可以看出:迭代了17次后���,迭代被終止���,已經找到最優解
此方法是不斷地將“參數估計值”代入”損失函數“求解���,而損失函數采用的是”殘差平方和“最小�,在迭代17次后��,殘差平方和達到最小值���,最小值為(6.778)此時找到最優解�,迭代終止
2:從參數估計值”表中可以看出:
b1= 12.904 (標準誤為0.610���,比較小�����,說明此估計值的置信度較高) b2=-11.268 (標準誤為:1.5881�,有點大���,說明此估計值的置信度不太高) b3=-0.496(標準誤為:0.138��,很小�����,說明此估計值的置信度很高)
非線性模型表達式為:Y(銷售量)= 12.904-11.268*e^(-0.496*廣告費用)
3:從“參數估計值的相關性”表中可以看出:b1 和 b3的相關性較強����,b2和b1或b3的相關性都相對弱一些�,其中b1和b2的相關性最弱
4:從anova表中可以看出:R方 = 1- (殘差平方和)/(已更正的平方和) = 0.909��,擬合度為0.909����,說明此模型能夠解釋90多的變異����,擬合度已經很高了
前面已經提到過�����,S行曲線的擬合度更高��,為(0.916)那到底哪個更合適呢�?如果您的數據樣本容量夠大�����,我想應該是“非線性模型”的擬合度會更高��!
其實想想���,我們是否可以將“非線性”轉換為“線性”后���,再利用線性模型進行分析了����?后期有時間的話�,將還是以本例為說明�,如何將“非線性”轉換為“線性”后進行分析??!
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
