用spss將詞篇矩陣轉成相似矩陣_spss相關矩陣
下文是關于用spss將詞篇矩陣轉成相似矩陣相關內容�,希望對你有一定的幫助:
用spss將詞篇矩陣轉成相似矩陣(一)
spss實驗報告六
實驗報告六
實驗項目:因子分析和主成分分析
實驗的目的:
利用SPSS進行因子分析和主成分分析�����。
實驗內容:
1.因子分析
2.主成分分析
一�����、因子分析
1����、因子分析是指研究從變量群中提取共性因子的統計技術�。
2�、[數據集1] C:Documents and Settingsuser桌面案例數據資料因子分析(基本建設投資分析).sav 相關矩陣
國家預算
內資金
(1995國內貸利用外自籌資其他投
億元)
相關 國家預算內資金
(1995年����、億元)國內貸款
利用外資
自籌資金
其他投資 款 資 金 資 由上表可以看出�,變量其他投資和自籌資金相關性比較強����,其次變量自籌資金和利用外資也具有很強的相關性��。
KMO 和 Bartlett 的檢驗
取樣足夠度的
Kaiser-Meyer-Olkin 度量�。
Bartlett 的球近似卡方
形度檢驗
df
Sig.
通過KMD和 Bartlett 的檢驗�,顯著性檢驗值為0��,小于0.05����,因此拒絕原假設��,可以進行因子分析���。 119.61經濟與管理學院 國貿09(1)班 姓名:丁敏 學號:2009165074
公因子方差
初始 提取
國家預算內資金(1995年��、國內貸款 利用外資 自籌資金 其他投資 提取方法:主成份分析����。
從解釋的總方差的表格中可以看出��,成份1和成份2 的方差貢獻率的和為88.970%���,大于85%����,因此僅提取成份1 和成份2 就可以����。成份1和成份2的命名分別為經濟因素和文化技術因素�����。
成份矩陣a
成份
1 2
國家預算內資金(1995年����、億元)國內貸款 利用外資 自籌資金 其他投資 經濟與管理學院 國貿09(1)班 姓名:丁敏 學號:2009165074
提取方法 :主成份��。
a. 已提取了 2 個成份�����?�!居胹pss將詞篇矩陣轉成相似矩陣】
通過旋轉成份矩陣�,可以寫出成份1和成份2的方程����,用x1�、x2�、x3�����、x4���、x5�、x6分別代表上述六個變量: F1=0.443X1+0.877X2+0.906X3+0.959X4+0.906X5【用spss將詞篇矩陣轉成相似矩陣】
F2=0.882X1+0.160X2-0.199X3-0.132X4-0.247X5
因此����,F的方程為:
F=0.944F1+0.056F2 旋轉成份矩陣a
成份

1 2
國家預算內資金(1995年��、億元)國內貸款 利用外資 自籌資金 其他投資 提取方法 :主成份���。
旋轉法 :具有 Kaiser 標準化的正
交旋轉法��。
a. 旋轉在 3 次迭代后收斂���。
成份轉換矩陣
成份1 2
1 2 提取方法 :主成份�����。
旋轉法 :具有
Kaiser 標準化的正
交旋轉法�。
經濟與管理學院 國貿09(1)班 姓名:丁敏學號:2009165074
成份得分協方差矩陣
成份1 2
1 2 提取方法 :主成份����。
旋轉法 :具有
Kaiser 標準化的正
交旋轉法��。
經濟與管理學院 國貿09(1)班 姓名:丁敏學號:2009165074
根據變量F得到的基本建設投資綜合排名如下:
經濟與管理學院 國貿09(1)班 姓名:丁敏 學號:2009165074
用spss將詞篇矩陣轉成相似矩陣(二)
SPSS中詞語中英文對照
SPSS中詞語中英文對照
1. mean–平均數
2. std.deviation–標準差
3. dependent list–因變量
4. independent list–自變量
5. option–選擇
6. data editor–數據編輯窗口����,顯示并編輯數據
7. syntax editor–命令語句窗口��,用戶可以直接編寫spss程序語句����,然后運行��,所起的作用
與菜單操作是一樣的
8. spss viewer–結果輸出窗口���,統計結果�、操作錯誤提示及警告等信息都在這個窗口顯示
9. number of cases–樣本量
10. Spss菜單下方的快捷鍵按鈕分別表示open–打開已創建的文件 save–保存新建或已
創建的文件 print–打印文件 dialog recall–重新打開使用過的對話框 undo–撤銷上一步的數據或變量操作 redo–回復撤消操作 goto chart–定位圖表 goto case–定位觀測量 variables–顯示變量信息 find–查找變量值 insert cases–在數據中插入新的觀測量 insert variable–在數據中插入新的變量 split file–用指定變量分隔一個數據文件 weight cases–為觀測量分配權重 select cases–使用特定標準選擇觀測量集合 value labels–顯示或隱藏變量值標簽 use sets–創建變量集合
11. Spss窗口最下方的狀態欄在沒有運行命令時通常顯示為spss processor is ready�,表示可
以接受用戶的操作�。在運行命令時通常顯示為running……,后面顯示相應的統計命令關鍵字�����。如果spss不能正常使用�,則狀態欄會有相應的消息顯示��。
12. 把菜單操作過程轉化為程序語句:單機主菜單edit�����,在下拉菜單中選擇options�,進入主
對話框�����,在該對話框上部的一系列標簽中單擊viewer��,然后選中左下方的可選項“display commands in the output”�����。同時在上方的item 選項中的log下選中contents are shown?����,F在��,您的每一次操作都會在結果輸出窗口中顯示相應的程序語句����。
13. 在initial output state 中的item包含了多項控制spss基本輸出形式的選項����,當選中其中
一項時����,下面的contents are 都對應著兩個可選項:shown或hidden��,即表示在結果窗口中顯示或隱藏相應的內容�����。Item的各項內容如下:
Log運行記錄����,以語句形式記錄spss從啟動到關閉期間所有的用戶操作��。 Warning是否顯示所用程序語句中的錯誤警告信息����。
Notes是否顯示說明
Titles是否顯示統計過程的標題
Pivot tables是否顯示統計表格
Chart是否顯示統計圖
Text output 是否顯示文本形式的輸出結果�。Spss大多數統計結果以表格形式輸出��,但也有一些以文本形式輸出�。
用spss將詞篇矩陣轉成相似矩陣(三)
spss學習筆記
你的旋轉方法有問題����,一般是用方差最大化旋轉來分析的
說明你的數據不太好����,可以考慮斜交
用旋轉成份矩陣��,里面的數值最好保留0.45以上的��,叫因素負荷量����。這樣你各個維度有多少題就出來了�。
用直交旋轉的圖 直交旋轉后因素解釋更為顯著
在進行主成分分析時����,一般取初始因子載荷系數絕對值大于幾的變量�?(大于0.4)
你肯定是選擇了正交或斜交旋轉才會產生“旋轉成分矩陣”����,你可以用主成分分析法來做一下就會發現沒有“旋轉成分矩陣”了�����,所以兩者是沒有關系的����,因為“成分矩陣”是主成分分析法得到的����,“旋轉成分矩陣”是因子分析得到的�����,(主成分分析和因子分析的關系應該知道吧�,理解一下就ok了)�。
因子載荷的意思是左邊的和因子的相關系數���。因子載荷在“成分矩陣”里分別是0.778�����、0.453���、0.553��、0.785�,這是左邊的那些TB對上面的因子的載荷——因此可以說是因子1=0.778*TB3+0.453*TB4+0.553*TB1+0.785*TB2��,(我這么說我像你應該能理解因子2的公式了吧)�。 因子載荷在旋轉成分矩陣里也是一樣的這種縱向的公式�����。
不知道你的問題解決了么��,我回答你的三個問題���。
第一個:成分矩陣是各個原始變量的主成分表達式的系數�;旋轉成分矩陣是成分矩陣正交變換(還有其他方法)得到的���;成分得分矩陣表示各項指標變量與提取的公因子之間的關【用spss將詞篇矩陣轉成相似矩陣】
系��。簡單來說通過成分矩陣可以得到原始指標變量的線性組合�,如TB3=0.778*F1-0.414*F2,其中F1����、F2分別為提取的公因子��;通過成分得分矩陣可以得到公因子的線性組合���,如F1=0.56*TB30.97*TB4+0.02*TB1+0.57*TB2�。
第二個問題:因子載荷量也就是成分載荷量��,因子矩陣與成分矩陣可以理解為同一個意思��。所以因子載荷量就是成分矩陣中的數字�。
第三個問題:你這四個元素的因子載荷量就是成分矩陣中的數字��。
這些問題可以歸結到一起就是���,因子的載荷是什么�����?怎么看�����?其實因子載荷就是提取出的公因子的系數��。
額外給你說一下旋轉成分矩陣�����,這個一般是在分析每個公因子受什么影響時����,才會用到�。
因子旋轉
在對社會調查數據進行分析時����,除了把相關的問題綜合成因子并保留大的因子��,研究者往往還需要對因子與測度項之間的關系進行檢驗����,以確保每一個主要的因子(主成分)對應于一組意義相關的測度項�。為了更清楚的展現因子與測度項之間的關系����,研究者需要進行因子旋轉���。常見的旋轉方法是VARIMAX旋轉���。旋轉之后��,如果一個測度項與對應的因子的相關度很高(>0.5)就被認為是可以接受的��。如果一個測度項與一個不對應的因子的相關度過高(>0.4)���,則是不可接受的����,這樣的測度項可能需要修改或淘汰���。
用spss將詞篇矩陣轉成相似矩陣(四)
關鍵詞共詞分析法:高等教育研究的新方法
摘要:關鍵詞共詞分析法是一種較新的科學計量分析方法����,它主要通過對高頻關鍵詞對在同一篇文章中出現的頻次進行統計分析�����,生成共被引矩陣���。在此基礎上��,通過統計軟件����,進行聚類分析�、多維尺度分析�����、因子分析��、主成分分析�����、社會網絡分析等高級統計處理��,繪制出二維或者三維的可視化圖形����,客觀系統的展示出所關注資料的直觀量化信息�。在我國高等教育研究領域較少有學者對此方法進行論述�,為了幫助大家更好地了解和掌握此方法���,本文以2000-2012年《教育研究》文獻熱點知識圖譜作為實例�����,詳細展示了此方法的使用過程和注意事項�。
一��、引言
隨著研究成果的激增��,數字化期刊的盛行及互聯網使用的便捷化�,可以通過網上搜索引擎快捷的查詢并獲得這些成果�����。在應對海量數字信息的今天����,傳統文獻計量和綜述方式���,不僅耗費時間�、效率低下�����、查詢資料的時間跨度短���,而且難以全面搜集海量文獻信息�,造成文獻研究偏于定性歸納�����、過于主觀����。[1]激增的數據背后隱藏著許多重要的信息���,缺乏挖掘數據背后隱藏的知識的手段�,導致了“數據爆炸但知識貧乏”���。[2]如何在浩如煙海的數字文獻中�,將這些零散的信息全面�、快速綜合起來�,挖掘出有深度的信息為我所用��,已經成為眾多研究者關注的熱點��。隨著計算機技術的不斷提升�,以及數理統計方法的完善�����,研究者使用計算機進行數據挖掘(Data Mining�,DM)的能力得以大大提升����。在此背景下���,科學知識圖譜開始成為當前國際科學計量學領域熱門的方法之一�。它是通過將科學計量學的引文分析方法與可視化技術相結合達到對信息的有效組織和利用����,生成新的知識�。[3]該方法首先���,通過計算機和互聯網搜索引擎強大的自動查詢功能�,在極短的時間里面完成對海量信息的準確查詢��。其次����,通過計算機對已查詢到的海量分散信息進行文獻計量統計分析�,不僅可以通過量化模型將其以科學的��、可視化的形式直觀的呈現出來�,而且還可以發現它們之間的深層次關系和趨勢�,對將要進行的同領域的研究提供科學的指導�����。該方法被國內外的許多科學計量學研究者應用于學科前沿的研究�。但是���,國內教育研究方法方面還比較落后�。許多現代科學研究方法在教育科研中應用得很少�,現代數學遲遲未被引進到教育科學中來�。[4]對于科學計量方法在教育研究中應用的專題介紹性文獻并不多見����。我們在撰寫本文前����,使用關鍵詞共詞分析方法分別對國內特殊教育和自閉癥(孤獨癥)[5]相關研究成果進行了梳理和總結�����,積累了一定的經驗��,同時��,該方法對大量文獻綜合處理的高效性���、準確性�、客觀性和直觀性給我們留下了深刻的印象��。為了幫助國內的高等教育研究者能夠對這種方法有所了解�,并且能夠在今后的研究中更多的使用這種方法�����,提升自己教育科研的準確性和科學性�,下面����,我們以代表國內教育最高研究水準的教育類的核心期刊《教育研究》在2000-2012年發表的所有文獻作為研究資料�,向大家展示該方法的具體使用過程和注意事項����。
二�、關鍵詞共詞分析方法
(一)關鍵詞共詞分析方法簡介
共詞分析(Co-word Analysis)是一種較新的文獻計量學方法�,其屬于內容分析方法的一種����。其主要原理是對一組詞兩兩統計它們在同一篇文獻中出現的次數��,以此為基礎對這些詞進行聚類分析�����,從而反映出這些詞之間的親疏關系����,進而分析這些詞所代表的學科或主題的結構與變化���。[6]共詞分析法可分別以文獻的主題詞和關鍵詞進行共詞分析��,但我們傾向于主張采用關鍵詞進行共詞分析來得出結論�����,主要原因有:第一����,關鍵詞是論文中起關鍵作用的�、最能說明問題的�、代表論文內容特征的��、或最有意義的詞[7];第二�����,關鍵詞不僅準確地反映論文的主題����,而且其本身應具有獨立的檢索功能;第三�,由于一篇文獻的關鍵詞或主題詞是文章核心內容的濃縮和提煉��,因此����,如果某一關鍵詞或主題詞在其所在的領域的文獻中反復出現��,則可反映出該關鍵詞或主題詞所表征的研究主題是該領域的研究熱點[8];第四���,通過對高頻關鍵詞共現關系分析����,可以進一步明晰若干熱點研究領域����。[9]關鍵詞共詞分析主要是通過共詞分析軟件���,對符合條件的查詢到的海量信息的關鍵詞對在同一篇文章中出現的頻次進行統計分析(共詞分析)���,生成共被引矩陣���。在此基礎上���,利用統計軟件�,進行聚類分析���、多維尺度分析���、因子分析�、主成分分析����、社會網絡分析等高級統計處理����,繪制出二維或者三維的可視化圖形�����,客觀系統的展示出所關注資料的直觀量化信息���。
(二)關鍵詞共詞分析方法的具體操作過程
1.準備研究工具
下載并安裝Bicomb共詞分析軟件和SPSS20作為主要研究工具����。Bicomb共詞分析軟件由中國醫科大學醫學信息學系崔雷教授和沈陽市弘盛計算機技術有限公司開發���。下載獲取地址為崔雷教授科學網的博客網址:https://skydrive.live.com/����?cid=3adcb3b569c0a509&id=3ADCB3B569C0A509%211195�。
2.準備研究資料
首先�,進入網絡搜索引擎�����,根據自己研究目的限定文獻來源����,進行文獻檢索�����。根據自己研究需要和目的對文獻進行取舍和保留���。再次�,對選取的文獻按照統一格式進行保存�。第三����,對保存的文獻進行標準化���。最后�,將保留文獻的格式轉化為Bicomb共詞分析軟件能夠識別的ANSI編碼�,供后續量化統計分析使用����。這里值得注意的是�,如果不將文本格式編碼轉為ANSI編碼�,Bicomb共詞分析軟件將無法識別有效信息�����。
3.進行量化統計分析
首先��,使用Bicomb軟件進行關鍵詞統計并確定提取�����、導出高頻關鍵詞詞篇矩陣��。有關Bicomb軟件進行關鍵詞統計的詳細操作過程請閱讀相關操作手冊����。[10]其次�,采用SPSS20對高頻關鍵詞進行聚類分析并生成Ochiai系數相同矩陣�����。再次���,采用SPSS將高頻關鍵詞的相同矩陣轉化為相異矩陣并進行多維尺度分析�����。最后���,對上述量化結果進行定量和定性結合的分析�����,得出相應的結論和建議��。 概括而言����,關鍵詞共詞分析法的一般過程包括:明確研究的問題����、選定并標準化研究材料��、高頻關鍵詞的選定���、共現矩陣的提取���、進行高級統計處理(相同矩陣�、相異矩陣的轉化�����、聚類分析����、多維尺度分析)���。
三�����、關鍵詞共詞分析方法示例
為了更好的使大家掌握該方法�,下面��,我們以“2000-2012年《教育研究》文獻熱點知識圖譜”為例向大家進行詳細的示范說明���。
(一)查找準備文獻
首先����,進入中國學術文獻網絡出版總庫����,進入標準檢索對話框�����,將發表時間欄的具體日期定義為從“2000-01-01”到“2012-12-31”��,文獻出版來源限定為“《教育研究》”�����。根據限定好的條件進行文獻檢索�����,檢索到文獻2908條��。其次����,根據研究需要刪除研討會綜述���、課題介紹��、會議通知����、卷首語�����、會議記錄�����、課題通過鑒定��、讀后感�����、簡介���、研討會簡介�����、書評�����、成果鑒定會����、學院以及學校簡介信息��、人物專訪��、投稿須知��、會議紀要�����、出版信息���、目錄信息����、公告等�,得到有效論文2550篇����。再次��,對上述文獻統一按照題名��、作者��、關鍵詞����、單位�、摘要���、年�、期等信息以文本形式保存��。最后將保存的文本信息編碼格式統一改為ANSI編碼后保存�����。
(二)進行量化統計
1.進行關鍵詞詞頻統計分析并提取高頻關鍵詞頻次
一個學術研究領域較長時域內的大量學術研究成果的關鍵詞集合��,可以揭示研究成果的總體內容特征��、研究內容之間的內在聯系����、學術研究發展的脈絡與發展方向等�����。[11]如果在統計文獻時�,關鍵詞出現的頻次越高����,則表示與該關鍵詞有關的研究成果越多����,研究內容的集中性就越強���。一個研究領域的少量高頻次的關鍵詞���,擁有該學科明顯大的信息密度與知識密度��,成為信息與知識需求者檢索文獻的重點��,它們被稱為核心關鍵詞���。[12]詞頻分析法是利用能夠揭示或表達文獻核心內容的關鍵詞或主題詞在某一研究領域文獻中出現的頻次高低來確定該領域研究熱點和發展動向的文獻計量方法�。[13]
對2550篇文章中的15976個關鍵詞進行詞頻統計分析����,發現關鍵詞出現的頻次范圍是1-107����。為了減輕工作量����,對關鍵詞頻次大于20的高頻關鍵詞進行提取�����,結果見表1���。
從表1可以看出��,頻次大于等于20的有52個關鍵詞�,占關鍵詞總數的3.25%����,其出現的頻次合計為1839次����,詞均35.37次�����,占關鍵詞總頻次(15976)的11.51%��。這些高頻關鍵詞表述的研究內容�����,是2000-2012年《教育研究》發表文章的核心內容����。從高頻關鍵詞分布順序可看出�,《教育研究》涉及的前10個研究熱點依次為:高等教育(107)���、基礎教育(69)��、教育公平(63)�����、教育改革(59)���、教師(59)����、教育研究(54)�、課程改革(52)�、教師教育(52)�、教育發展(48)����、教育理論(44)�。這一統計結果����,與2000-2009年八種教育學期刊文獻前10位高頻關鍵詞(高等教育���、課程改革����、教育研究�����、教育改革����、素質教育����、教學改革�、基礎教育�����、課堂教學��、教師��、教育理論)對比���,有7個高頻關鍵詞完全重合��,排在第一位的高等教育和最后一位的教育理論在排序上完全吻合��,其它5個僅在排列順序上發生差異��。這一結果不僅驗證了本研究中統計方法的可信����,而且還進一步說明相對于其它教育研究刊物��,《教育研究》起著風向標的作用���。
為深入挖掘這52個高頻關鍵詞的詞頻之間的關系以及它們背后隱藏的有效信息����,還需要進一步采用關鍵詞共現技術來進行深入的計量學研究�����。
2.生成高頻關鍵詞的相同和相異矩陣
首先�����,生成高頻關鍵詞詞篇矩陣�。對各個高頻關鍵詞是否在其它論文中成對出現(出現為1��,否則為0)���,利用Bicomb軟件生成高頻關鍵詞詞篇矩陣����。詞篇矩陣考察各高頻關鍵詞間的親疏關系�����,詞篇矩陣表示的是兩目標之間的相似程度的矩陣�����,即兩者數字越大表明兩者關系越近�,越小表明兩者關系越遠��。[14]其次��,生成高頻關鍵詞相似系數矩陣��。以關鍵詞詞篇矩陣為基礎���,在SPSS20中進行相關分析����,數據類型選擇“binary”二元變量�����,相似系數選擇“Ochiai”系數�����,構造出高頻關鍵詞相似系數矩陣�。[15]相似矩陣中的數字表明數據間的相似性��,數字的大小表明了相應的兩個關鍵詞之間的距離遠近���,其數值越接近1��,表明關鍵詞之間的距離越近�、相似度越大;反之�����,數值越接近0���,則表明關鍵詞之間的距離越大�、相似度越小����。最后�,生成高頻關鍵詞相異系數矩陣��。為了消除由于關鍵詞共現次數差異所帶來的影響����,根據相似系數矩陣�,采用相異系數矩陣=1-相似系數矩陣��,產生相異系數矩陣����。相異系數矩陣中數字表明數據間的相異性��,其含義與相似系數矩陣意義相反��,數值越接近1���,表明關鍵詞之間的距離越大�����。相異系數矩陣結果見表2�。
從表2可以看出����,各關鍵詞分別與高等教育距離由遠及近的順序依次為:教師(1.000)�、教育研究(1.000)�����、課程改革(1.000)��、教師教育(1.000)�、基礎教育(0.988)���、教育改革(0.908)�����、教育公平(0.963)��。這個結果說明��,研究者在論及高等教育時�,會更多的將其與教師��、教育研究��、課程改革與教師教育結合在一起討論��,而較少和基礎教育�����、教育改革����、教育公平結合起來�。采用上述原理����,綜合表2中的關鍵詞相異系數矩陣數據�����,可以初步得出的結論為:2000-2012年在《教育研究》發表的成果中�����,涉及到基礎教育與課程改革的資料較少�,大量研究主要以高等教育為探討對象�,關注高等教育中涉及的教師�����、教育研究�、課程改革及教師教育等主要因素�����,對這些因素予以了更多的關注�。出現這一結果的原因�����,一方面是《教育研究》從2004年開始增大了對“教師”這一關鍵詞的關注�,開辟了專欄�。另一方面的原因是�����,2001年“教師教育”被國務院首次提出后���,引起了多方面尤其是教育界對此問題的高度重視���。
3.進行高頻關鍵詞聚類分析
聚類分析是選定一些分類標準���,將不同的觀察體加以分類�,同一類(集群)之內觀察體彼此的相似度愈高愈好�����,而不同一類之間觀察體彼此的相異度愈高愈好��。[16]高頻關鍵詞聚類分析是通過高級統計對已經發表文獻的高頻關鍵詞組的相似性與相異性分析���,來發現它們之間的遠近關系���,挖掘隱藏在它們背后的研究者關心的知識信息��。關鍵詞聚類分析時�,先以最有影響的關鍵詞(種子關鍵詞)生成聚類;再次�����,由聚類中的種子關鍵詞及相鄰的關鍵詞再組成一個新的聚類�����。關鍵詞越相似它們的距離越近�����,反之����,則越遠����。 將上述52個高頻關鍵詞構成的52×52的相似系數矩陣��,導入SPSS20進行聚類分析�����。結果見圖1�。
從圖1可以直觀的看出2000-2012年《教育研究》高頻關鍵詞被分為8個種類��,它們的具體分布結果見表3����。
從表3可以看出���,2000-2012年《教育研究》8類研究具體分布為:
種類1為教學過程中的活動和改革�,包括14個關鍵詞�����,其可以細分為6小類:小類1基礎教育教學活動及過程�����,包括3個關鍵詞(教學過程�、教學活動�����、基礎教育課程);小類2教學改革與教學論��,包括2個關鍵詞(教學改革�����、教學論);小類3教學模式與課堂教學���,包括2個關鍵詞(教學模式��、課堂教學);小類4學生����、教師及其發展�,包括3個關鍵詞(學生��、發展 �、教師);小類5師生關系��,包括1個關鍵詞(師生關系);小類6基礎教育及素質教育的課程改革�����,包括3個關鍵詞(基礎教育���、課程改革����、素質教育)�����。
種類2為道德教育與生活��,包括2個關鍵詞(道德教育���、生活世界)���。
種類3為教育與課程�����,包括2個關鍵詞(教育��、課程)���。
種類4為學校教育����、義務教育及教育政策��、觀念�����,包括16個關鍵詞����,其可以細分為7小類:小類1學校教育與職業教育���,包括2個關鍵詞(學校教育 �����、職業教育);小類2農村教育和農村義務教育���,包括2個關鍵詞(農村教育�、農村義務教育);小類3義務教育和均衡發展���,包括2個關鍵詞(義務教育���、均衡發展);小類4教育公平��、質量及政策�,包括3個關鍵詞(教育公平 ����、教育質量��、教育政策);小類5教育資源���,包括1個關鍵詞(教育資源);小類6教育發展與教育科研�,包括2個關鍵詞(教育發展��、教育科研);小類7教育理念及對學習者的關注��,包括4個關鍵詞(以人為本 ���、科學發展觀����、教育理念 ��、學習者)���。
種類5為大學及學科建設���,包括2個關鍵詞(大學 �����、學科建設)�。
種類6為教師教育�����、教育理論與教育思想�,包括10個關鍵詞��,其可以細分為3小類:小類1教師教育及其專業發展��,包括3個關鍵詞(教師教育 �����、教師專業發展����、中小學教師);小類2教學理論����、研究及實踐與改革���,包括6個關鍵詞(教育理論�、理論與實踐 �、教育研究 �、教育實踐 �����、教育學 �����、教育改革);小類3教育思想���,包括1個關鍵詞(教育思想)��。
種類7為高等職業教育和民辦教育���,包括2個關鍵詞(高等職業教育�����、民辦教育)�。
種類8為高等教育�、高等學校與價值取向����,包括4個關鍵詞��,可以細分為2小類:小類1高等教育與大學生價值取向�����,包括3個關鍵詞(高等教育 �����、大學生 �����、價值取向);小類2高等學校����,包括1個關鍵詞(高等學校)����。
4.進行高頻關鍵詞的多維尺度分析
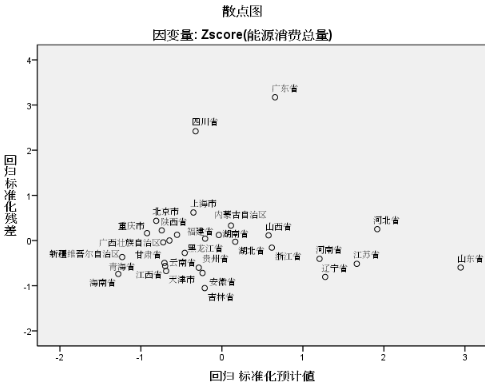
多維尺度分析(MDS)是一種可以幫助研究者找出隱藏在觀察資料內的深層結構的統計方法�,其目的是在發掘一組資料背后之隱藏結構�����,希望用主要元素所構成的構面圖來表達出資料所隱藏的內涵����,尤其是在觀察資料體很多時���,利用多維尺度法更能適切地找出資料的代表方式�����。[16]采用多維尺度分析時����,要匯報其 Stress和RSQ值���,它們分別為多維尺度分析中的信度和效度估計值��。其中�,壓力系數(Stress)是擬合度量值��,用于維度數的選擇����,Stress越小����,表明分析結果與觀察數據擬合越好���,其值越小���,說明模型的適合度越高���。Kruskal(1964)給出了一種根據經驗來評價Stress優劣的尺度:若Stress≥20%��,則近似程度為差(Bad);≤10%�����,為滿意(Fair);≤5%����,則為好(Good);≤2.5%����,為很好(Excellent);其理想的狀況為Stress=0��,稱為完全匹配(Prefect)����。[17] 模型距離解釋的百分比(RSQ)��,表示變異數能被其相對應的距離解釋的比例�����,也就是回歸分析中回歸分析變異量所占的比率�����,RSQ值越大����,即越接近1��,代表所得到的構形上各點之距離與實際輸入之距離越適合����。一般認為���,RSQ在0.60以上是可接受的�����。[18]
采用spss20對上述52個高頻關鍵詞構成的52×52的聚類分析產生的矩陣進行多維尺度分析�,標準化方法選擇Z分數�����。結果顯示��,Stress= 0.120����,RSQ= 0.823�,說明其擬合效果較好����,可以反映出《教育研究》高頻關鍵詞間的學術聯系狀況�。多維尺度分析結果見圖2�。
多維尺度繪制出的坐標稱為戰略坐標����,它以向心度和密度為參數繪制成二維坐標���,可以概括地表現一個領域或亞領域的結構���。[19]戰略坐標中��,各個小圓圈代表各個高頻關鍵詞所處的位置�����,圖中圓圈間距離越近���,表明它們之間的關系越緊密;反之�����,則關系越疏遠��。影響力最大的關鍵詞��,其所表示的圓圈距離戰略坐標的中心點越近����。坐標橫軸為向心度(Centrality)�����,表示領域間相互影響的強度;縱軸為密度(Density)���,表示某一領域內部聯系強度���。[20]在戰略坐標劃分的四個象限中��,一般而言����,第一象限的主題領域內部聯系緊密并處于研究網絡的中心地位�����。第二象限的主題領域結構比較松散��。這些領域的工作有進一步發展的空間����,在整個研究網絡中具有較大的潛在重要性����。第三象限的主題領域內部鏈接緊密����,題目明確�����,并且有研究機構在對其進行正規的研究�,但是在整個研究網絡中處于邊緣�。第四象限的主題領域在整體工作研究中處于邊緣地位�,重要性較小���。[21]
結合上述理論����,從圖2可以看出���,首先����,2000-2012年《教育研究》熱點知識圖譜分為8個區域�,雖然種類1���、4和6所占的區域較大�,種類2�、3�、5���、7����、8所占區域較小����,但從其分布位置可以看出�,這些小的區域處于戰略坐標的核心附近�,表明這些區域是其關注的重點�。種類7和種類8所處的領域距離戰略坐標軸心位置最近�,表明近幾年高等職業教育和民辦教育���、高等教育��、高等學校與價值取向成為了《教育研究》發文的熱點領域����。其次�����,從各個種類所處戰略坐標的象限分布特點來看����,種類4的大部分關鍵詞位于戰略坐標的第一象限����,說明其不僅是《教育研究》雜志組稿的核心領域�����,而且其文章數量相對于其它7個種類所占領域更為多�,也更成熟�����,該領域的研究是我國教育研究的中心領域���。種類1�、8主要位于第二象限��,說明其主題相對松散�����,對其關注度還有待于進一步加強���,其今后在《教育研究》文獻成果質量提升方面還具有較大的潛在價值����。種類2�����、3���、6主要位于第三象限����,說明這3個種類所占的領域內部鏈接緊密�,題目明確����,并且有研究機構正在對其展開正規的研究���,但在整個研究網絡中仍處于邊緣���。種類6大部分位于戰略坐標的第四象限��,說明它們所處的主題在整個研究中處于邊緣地位����,重要性較小�����。種類7不僅橫跨四個象限�����,而且緊緊圍繞在戰略坐標軸心�����,說明它所占的領域是《教育研究》發文的重點核心領域���,該領域的研究不僅與國家中長期教育改革和發展規劃綱要(2010-2012年)提出的大力發展職業教育和大力支持民辦教育的內容相一致�����,而且還與《教育研究》“2006中國教育研究前沿與熱點問題年度報告”中“創新高等教育發展思路”�、“拓展高等教育辦學多樣化”����、“職業教育的轉型與發展取向”[22]等內容相一致�。此研究結果也被潘黎���、王素的研究所驗證���。 四�����、總結和展望
通過上述實例���,大家可以更直觀的感受到關鍵詞共詞分析方法的使用效果�����,但是���,在使用的具體過程中��,還應該值得關注和思考下述問題����。
(一)進行關鍵詞共詞分析前要確保對其進行標準化
我們主要針對《教育研究》進行計量分析��,因為其風格基本一致���,所以在標準化處理關鍵詞方面比較容易處理��,但是�,如果涉及到多個雜志間的文獻關鍵詞處理����,就要特別注意對查詢到的文獻的關鍵詞進行規范和統一�。比如���,我們在進行自閉癥熱點研究時����,要將在不同刊物中表達同樣含義的關鍵詞“自閉癥”與“孤獨癥”統一為“自閉癥”��。遲景明和吳琳在研究中����,將“高職院?����!?�、“職業技術學院”和“職技高?����!睒藴驶癁椤案呗氃盒�����!?��,將“高等學?!?�、“高等院?����!?�、“高?����!?、“大學”等標準化為“高?�!?����。對關鍵詞的標準化處理���,能確保最后量化材料的準確��,進而保證最后科學計量的精確���、科學�。但很多進行科學計量的研究忽視了此問題��,導致了其研究結果的科學和準確性大打折扣�����。
(二)可以嘗試使用社會網絡分析法更清晰地展示關鍵詞間的強弱關系
本研究采用的多維尺度雖然可以較好的觀察到變量間的關系����,但是無法表現他們之間的強弱���。要更好的表達各個關鍵詞之間的強弱關系���,大家以后可以嘗試進行社會網絡分析��。社會網絡分析(Social Network Analysis)(簡稱SNA�,有的文獻稱為“社會網”或“網絡分析”)是包括測量與調查社會系統中各部分(“點”)的特征與相互之間的關系(“連接”)����,將其用網絡的形式表示出來���,然后分析其關系的模式與特征這一全過程的一套理論���、方法和技術�����。[23] 采用社會網絡分析得出的三位立體網絡圖���,更能直觀地反應各個體(節點)的位置及它們之間的相互關系(線段)���。在原始圖線條密集��,不易分析時��,還可進行凝聚子群分析��,使圖的直觀性增強���,更容易分析理解���。[
(三)關鍵詞共詞分析法和定性方法結合使用才能更好解讀研究結果
雖然熱點知識圖譜是采用科學計量法繪制出來的�,但是該方法的使用并非完全依賴定量技術�����,其還依賴于定性分析技術�。在進行了聚類分析和多維尺度分析之后�����,對于各個種類及其所在區域的劃分和命名均需要雄厚的專業功底����。它就像采用因子分析之后�����,對于各個因子的命名需要結合專業知識來命名一樣���。因此���,要進行科學知識圖譜的繪制���,需要將定量研究與定性分析結合起來���,具有一定的專業背景�,才能夠對計量結果進行準確����、客觀的解讀�。
(四)進行關鍵詞共詞分析方法時軟件的選取也至關重要
雖然現在國內很多研究者����,在社會學科�、管理學科�、醫學等研究領域對中文文獻的熱點知識圖譜的繪制采用了陳朝美博士研發的CiteSpace軟件��,但是該軟件的優勢在于處理外文��,尤其是英文文獻上���,對于中文文獻的處理還存在一定的不足�,而我們所介紹的Bicomb軟件在中文文獻的共詞分析方面較有優勢���,因此�����,我們建議大家對中文材料進行科學計量研究時更多的采用此軟件���。
通過本文的介紹����,我們衷心希望能夠幫助高等教育研究者對關鍵詞共詞分析法有所了解����,同時��,也真誠的希望越來越多的高等教育研究者投入到教育研究成果的科學計量研究中來����!
用spss將詞篇矩陣轉成相似矩陣(五)
基于關鍵詞共現的國內用戶研究主題探討
【摘要】以2002-2011年我國圖情領域關于用戶研究的文獻為對象���,從關鍵詞共現分析����、聚類分析�����、社會網絡分析等幾個方面對文獻中的高頻關鍵詞進行定量研究��,并將其歸類為六大主題���。
引言
隨著信息化和網絡化時代的來臨����,人們的信息交流日益頻繁���,信息用戶日漸龐大�。對用戶進行研究已成為我國圖情領域研究的前沿和熱點�,其研究成果可以為信息服務機構開展以用戶為中心的服務提供依據�。在這一趨勢的引領下�����,圖情界同仁迫切希望了解近10年來關于用戶研究的熱點領域和動態信息��,為未來完善用戶研究提供有用的借鑒���。因此����,筆者采用共詞分析法和社會網絡分析法對2002-2011年我國圖情領域關于用戶研究文獻中的高頻關鍵詞進行分析���,以揭示用戶研究的主題���,把握其發展趨勢����。
共詞分析法主要是利用文獻集中關鍵詞對共同出現的情況來確定該文獻集所代表學科中各主題之間的關系���。一般做法是統計一組文獻的關鍵詞兩兩之間在同一篇文獻中出現的頻率��,便可形成一個由這些詞對關聯所組成的共詞網絡��。利用聚類�����、因子分析等多元統計分析方法對共詞網絡進行分析����,進而展現該學科的研究結構[1]�����。
社會網絡分析法原本是社會學用于研究社會成員之間關系的一種定量方法���,后來被引入到了圖情領域的相關研究�。它在關鍵詞分析中應用的主要原理是將關鍵詞作為網絡的節點��,關鍵詞之間的共現關系則構成節點之間的連線��,構建社會網絡關系圖譜�����,然后應用中心度�����、小世界效應等方法進行分析����,進而發掘出關鍵詞之間的關系 [2]�。
2.1 數據來源
為了盡可能保證查全率�����,筆者以“用戶”�����、“信息用戶”為題名和關鍵詞��,對中國知網和維普網收錄的19種圖情領域核心期刊進行檢索����。共得到2002-2011年發表的論文2 632篇�����,剔除非學術論文�����、重復等無效部分后�,最終有效篇數為2 115篇���。
19種核心期刊分別是:《情報學報》�、《圖書情報工作》����、《國家圖書館學刊》��、《圖書與情報》�、《圖書館學研究》���、《圖書館工作與研究》��、《圖書館理論與實踐》�、《情報雜志》�����、《情報科學》�、《圖書館雜志》�、《圖書館建設》���、《圖書館論壇》�����、《圖書館》���、《圖書情報知識》���、《情報理論與實踐》���、《中國圖書館學報》�、《大學圖書館學報》����、《情報資料工作》��、《現代圖書情報技術》��。除了《情報學報》上發表的文獻來自于維普網外����,其他均來自于中國知網���。
2.2 數據預處理
由于關鍵詞是論文作者自行選擇的自然語言����,因此會存在一些不規范��、不統一的現象�����。為了讓研究結果更加準確�����,筆者采用歸并�����、吸收和丟棄三種方法對關鍵詞進行逐一的人工處理�����。
歸并法是指對同一內容用不同詞語來表達或者同一詞語用不同語種來表示的情況�,歸并為統一的詞語���。如用戶���、讀者和信息需求者等�,歸并為用戶��; Lib2.0��、Library2.0和圖書館2.0�,歸并為圖書館2.0�����。
吸收法是指針對同一研究內容�,但卻采用上下位關系來表示的關鍵詞�,如用戶��、圖書館用戶和信息用戶��,采用上位類代替下位類的方式進行吸收��,即采用用戶來表示����。有些詞需要采用下位類吸收上位類的方式�����,如模型和用戶模型�����,這需要結合文獻的具體內容而定�����。
丟棄法是指針對一些與用戶研究無關或者太寬泛的關鍵詞�,如學校機構的名稱(中央財經大學)�����、趨勢����、google工具欄�����、中國招生考試網絡關系圖譜���。該方法能夠直觀地揭示各個元素之間的緊密程度和所處地位���。通過構建高頻關鍵詞的圖譜����,可以分析出高頻關鍵詞在整個網絡中所處的地位 [6]�����。
3.1 總體趨勢
論文的數量能夠直接反映圖情領域對用戶研究的關注度�,2002-2011這10年間共有2 115篇相關論文�,年均211.5篇�?����?牧繌?002年的98篇增長到了2011年的309篇�,增長了近3.15倍�����,年均增長率達到12.2%�����。上述數據表明���,近10年來我國學者對于用戶的研究越來越關注和重視���。正如普賴斯文獻指數增長規律所反映的現象�����,圖情領域關于用戶的研究正處于發展階段�����,會引起許多不同學者進行思想交流����,不同學科內容的相互滲透��、交叉�����,推動了用戶研究的蓬勃發展�。 同時���,筆者對關鍵詞進行規范化處理之后���,共整理出頻次大于20的34個高頻關鍵詞�。其中信息服務����、用戶需求�、數字圖書館�����、高校圖書館�����、個性化服務這5個關鍵詞的頻次都大于100�����,說明在網絡越來越發達的今天�����,圖書館等信息服務機構更加關注用戶的個性化需求�,根據不同用戶的需求特征�,有針對性地提供信息服務�����。
為了更加清楚�����、形象地展現近10年我國圖情領域關于用戶研究的主題和核心領域�����,筆者對得到的高頻關鍵詞進行共詞和社會網絡分析�,并繪制相應的關系圖�。
3.2 主題歸類
3.2.1 主題類數的確定
利用SPSS17.0 進行因子分析����, 結果見表4����。按照提取因子的方差累積百分比要超過60 %的原則�����, 從關鍵詞矩陣中提取符合條件的因子個數為6�����。這6個因子的方差累積貢獻率達到63.503%���,即能夠解釋全部信息的63.503%�����。由此可以確定用戶研究的主題類數為6類�����。
3.2.2 歸類結果
根據因子分析的結果�,將關鍵詞采用系統聚類的方法聚為六大主題(見表5)�����,分別是新形勢下高校圖書館用戶教育研究���、網絡環境下圖書館用戶需求研究���、數字圖書館用戶個性化服務研究�、網絡模式下用戶服務滿意度研究�、網絡信息資源的用戶體驗研究����、信息組織中的用戶參與研究��。為了更加直觀形象地展示歸類主題結果���,筆者采用多維尺度分析法構建了主題圖譜(見圖1)����。
新形勢下高校圖書館用戶教育研究�。由于高校圖書館是高校的文獻信息中心�,是教師���、科研人員�、學生查找資料的主要場所�。因此�����,國內外對于高校圖書館的用戶教育研究歷來都很重視�,將之貫穿于圖書館各個工作環節中���。隨著Web 2.0和圖書館2.0的發展�,高校圖書館在文獻載體����、信息構建�、服務手段等諸多方面都發生了巨大的變化�����。如何將Web 2.0和圖書館2.0的一些元素應用于用戶教育����,提高用戶信息檢索能力以及有效利用信息的能力�,已成為高校圖書館一項十分緊迫而重要的任務[8]����。
網絡環境下圖書館用戶需求研究���。隨著網絡的不斷發展�����,用戶對信息的需求也處于不斷變化中�����。用戶不再滿足于簡單地獲取文獻信息���,而是希望利用快捷���、豐富的網絡資源全方位獲取各種相關的信息����。圖書館傳統的服務模式已經跟不上網絡環境下用戶的需求����,用戶流失現象日益嚴重����。在這種形勢下�,學者對網絡環境下用戶需求的特點進行了大量的研究��,以期圖書館等信息服務機構創建與之相適應的服務方式��,為用戶提供綜合化的信息服務[9]���。
數字圖書館用戶個性化服務研究��。數字圖書館是隨著網絡技術的成熟而蓬勃發展起來的���,用戶通過檢索就能夠獲取所需信息���。由于需要用戶的參與�����,因此這種信息獲取往往是被動的���,獲得的信息質量不盡如人意�。在這樣的情況下����,個性化服務應運而生��,并已經成為數字圖書館信息服務研究的主要問題���。圍繞這個問題����,學者對用戶信息行為�����、信息偏好�、用戶模型�����、用戶咨詢����、搜索引擎等方面進行了大量的研究���,以便系統�����、全面地獲取用戶興趣特點�����,主動推送其所關注的信息資源���。
網絡模式下用戶服務滿意度研究���。網絡環境下圖書館的用戶滿意度是從用戶角度出發�,即用戶在獲取網絡信息資源時是否達到或者超過預期滿足程度的一種心理狀態�。學者對用戶滿意度研究有利于優化網絡檢索系統����,提高查全率和查準率�����,提升信息的服務質量�����。
網絡信息資源的用戶體驗研究����。對圖書館等信息服務機構而言�����,用戶體驗是指用戶在使用信息產品過程中所獲得的心理感受��。根據用戶體驗結果可以有效地進行網絡信息資源整合�����、基本術語規范以及創新服務模式等���。用戶體驗對于圖書館等信息服務機構來說是一種全新的觀念�,近年來對其關注度不斷加大�����。但是相對其他主題來說�,用戶體驗研究的內容寬泛而且沒有一個相對統一的標準���,導致該領域的研究深度有限�。
信息組織中的用戶參與研究����。信息組織是信息資源開發利用的關鍵環節��,由于當前以博客�、微博�、社交網絡等為代表的微內容不斷興起��,用戶越來越多地參與到信息組織中來����。用戶參與圖書館信息組織一方面有益于改善圖書館信息資源組織與服務����,同時也給圖書館信息組織帶來了挑戰�。因此�,圖書館將來必須變革傳統的信息組織模式��,創新信息組織模式與方法[10]�。
3.3 核心主題
3.3.1 核心主題的確定
在確定了近10年來關于用戶研究的主題后����,接下來筆者將進一步分析這6類主題的聯系程度及所處地位�����。為此���,筆者借鑒社會網絡分析方法��,繪制主題的社會網絡關系圖譜(見圖2)��。圖譜中節點的大小代表在整個網絡中的地位��,節點越大越接近中心地位����,屬于核心主題�����。據此可以看出“數字圖書館用戶個性化服務研究”和“網絡環境下圖書館用戶需求研究”是整個主題網絡中的核心節點�����,其中前者與所有的主題都有聯系�,核心地位更突出��。這表明在互聯網的沖擊下��,傳統圖書館在向數字圖書館邁進的過程中��,更加注重以用戶需求為導向的個性化服務模式的運用����。
3.3.2 核心主題的分析
社會網絡關系圖譜中兩節點間的連線情況反映兩個節點的聯系強度����,如果存在連線����,代表兩個節點有聯系��;連線越粗�����,表示兩者關系越緊密�。根據這個原理����,筆者對核心主題――“數字圖書館用戶個性化服務研究”所囊括的高頻關鍵詞進行圖譜分析(見圖3)����。從圖中可以看出�,個性化服務與數字圖書館�、用戶模型�、搜索引擎以及知識服務聯系緊密���??梢娫跀底謭D書館背景下�����,用戶模型的建立����、搜索引擎的優化以及原始資料的知識抽取對個性化服務的開展至關重要����。同時�����,數字圖書館與用戶研究��、用戶服務聯系緊密�����,表明數字圖書館與傳統圖書館相比���,更加注重以用戶為中心的服務理念���。
結論
筆者利用共詞和社會網絡分析技術�����,對2002-2011年我國圖情領域以用戶研究為主題的論文進行了研究����。結果表明��,學者對用戶研究的主題主要集中在六個方面����。其中����,數字圖書館用戶個性化服務研究和網絡環境下圖書館用戶需求是目前關注的重點領域?���,F有的用戶研究主題都與互聯網技術密切相關��,這表明將網絡技術引入到對圖情領域用戶的信息服務已成為這一學科的未來發展趨勢����。
用spss將詞篇矩陣轉成相似矩陣(六)
北京體育大學體操方向碩士學位論文研究熱點分析
中圖分類號:G807 文獻標識:A 文章編號:1009-9328(2013)12-000-01
摘 要 對北京體育大學2003-2012年體操方向碩士學位論文的關鍵詞詞頻統計與分析����,研究高頻詞之間的結構關系�,探究北京體育大學體操方向碩士學位論文的選題方向���、研究內容及其不同的特點��,分析熱點的形成原因與未來發展趨勢��。
關鍵詞 北京體育大學 碩士學位論文 研究熱點
一�、研究方法與對象
研究方法主要采用詞頻統計法與共詞聚類分析法���。詞頻統計法能夠揭示或表達文獻核心內容的關鍵詞或主題詞在某一研究領域中出現的頻次高低來確定該領域研究熱點和發展動向的文獻計量法�。共詞聚類分析法是一種內容分析方法���,通過對一組詞兩兩統計它們在同一片文獻中出現的頻率�,以此為基礎對這些詞進行聚類分析�����,從而反映出詞與詞之間的親疏關系�,進而分析這些詞所代表的學科和主題的研究結構����。
二����、研究生學位論文的共詞聚類分析
(一)關鍵詞詞頻統計與分析
本文利用《CNKI中國優秀碩士學位論文全文數據庫》��,搜索出2003―2012年北京體育大學體操方向碩士學位論文共73篇�,以73篇學位論文中的關鍵詞為調研對象��,通過共詞分析法中的聚類分析探索各高頻關鍵詞之間的內在關系�����,歸納出北京體育大學體操碩士學位論文研究的熱點�,以及各個不同研究方向的親疏性�。本研究利用Excel對前期檢索出的學位論文進行關鍵詞統計�����,共得到碩士學位論文關鍵詞283個��,平均每篇碩士學位論文含關鍵詞3.9個���。然后對統計結果進行以下處理:去除對反應主題沒有積極意義的詞��,如“展望”�、“問題”等�,對表達同一個意思的關鍵詞進行標準化處理�,如“高職院?!?����、“職業技術院?��!?��、“職技高?�!钡葮藴驶癁椤案呗氃盒����!?����,“高等院?�!?�、“高等學?����!?���、“高?���!?����、“大學”等標準化為“高?�!?��。
經過多次比較���,最終選擇詞頻大于的關鍵詞作為高頻關鍵詞��,從而確定個體操方向碩士學位論文的高頻關鍵詞(表1)�����。這個關鍵詞總的出現頻次為65次���,占關鍵詞總頻次的36.3%���。從高頻關鍵詞分布可以看出��,北京體育大學體操方向碩士研究生重點關注的研究對象集中在“體育教育專業”����、“分析”�����、“普通高?!?�、“競技體操”���、“北京市”�����、“教學理念”����、“現狀”�����、“發展對策”等����。
表1 碩士學位論文高頻關鍵詞表
序號 關鍵詞 詞頻
1 體育教育專業 12
2 分析 10
3 普通高校 8
4 競技體操 8
5 北京市 7
6 教學理念 7
7 現狀 7
8 發展對策 6
(二)構造詞篇矩陣���、相似矩陣
對于高頻關鍵詞共現頻次的統計����,本研究利用SPSS17.0��,以每篇學位論文為一條記錄�����,記錄的內容為高頻關鍵詞是否在學位論文的關鍵詞出現(出現為1�,否則為0)�����,構造出詞篇矩陣�。以詞篇矩陣為基礎�����,在SPSS軟件中進行相關分析��,數據類型選擇“binary”二元變量����,相似系數選擇“Ochiai”系數�,構造出高頻關鍵詞的相似矩陣(見表2)����。相似矩陣中的數字為相似數據�,數字的大小則表明詞與詞之間的距離遠近�,數值越大則表明詞與詞之間的距離越近�����,相似度越好����;反之�,數值越小���,表明詞與詞之間的距離越遠���,相似度越差��。相似矩陣對角線的數據為1����,表明某高頻關鍵詞自身相關度���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
