k均值聚類(K-means)_k means聚類算法
在前面的文章中��,介紹了三種常見的分類算法�����。分類作為一種監督學習方法���,要求必須事先明確知道各個類別的信息����,并且斷言所有待分類項都有一個類別與之對應�。但是很多時候上述條件得不到滿足����,尤其是在處理海量數據的時候�����,如果通過預處理使得數據滿足分類算法的要求����,則代價非常大���,這時候可以考慮使用聚類算法���。聚類屬于無監督學習�����,相比于分類�����,聚類不依賴預定義的類和類標號的訓練實例����。本文首先介紹聚類的基礎——距離與相異度�,然后介紹一種常見的聚類算法——k均值和k中心點聚類����,最后會舉一個實例:應用聚類方法試圖解決一個在體育界大家頗具爭議的問題——中國男足近幾年在亞洲到底處于幾流水平���。
相異度計算
在正式討論聚類前�����,我們要先弄清楚一個問題:如何定量計算兩個可比較元素間的相異度�����。用通俗的話說�����,相異度就是兩個東西差別有多大�����,例如人類與章魚的相異度明顯大于人類與黑猩猩的相異度��,這是能我們直觀感受到的�。但是�,計算機沒有這種直觀感受能力���,我們必須對相異度在數學上進行定量定義����。
設 �����,其中X��,Y是兩個元素項����,各自具有n個可度量特征屬性����,那么X和Y的相異度定義為:
�����,其中X��,Y是兩個元素項����,各自具有n個可度量特征屬性����,那么X和Y的相異度定義為:=f(X,Y)%20\to%20R "d(X,Y)=f(X,Y) \to R") ��,其中R為實數域����。也就是說相異度是兩個元素對實數域的一個映射����,所映射的實數定量表示兩個元素的相異度��。
��,其中R為實數域����。也就是說相異度是兩個元素對實數域的一個映射����,所映射的實數定量表示兩個元素的相異度��。
下面介紹不同類型變量相異度計算方法�����。
標量
標量也就是無方向意義的數字����,也叫標度變量?�,F在先考慮元素的所有特征屬性都是標量的情況��。例如�����,計算X={2,1,102}和Y={1,3,2}的相異度��。一種很自然的想法是用兩者的歐幾里得距離來作為相異度����,歐幾里得距離的定義如下:
=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+...+(x_n-y_n)^2} "d(X,Y)=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+...+(x_n-y_n)^2}")
其意義就是兩個元素在歐氏空間中的集合距離���,因為其直觀易懂且可解釋性強���,被廣泛用于標識兩個標量元素的相異度�。將上面兩個示例數據代入公式�����,可得兩者的歐氏距離為:
=\sqrt{(2-1)^2+(1-3)^2+(102-2)^2}=100.025 "d(X,Y)=\sqrt{(2-1)^2+(1-3)^2+(102-2)^2}=100.025")
除歐氏距離外�,常用作度量標量相異度的還有曼哈頓距離和閔可夫斯基距離��,兩者定義如下:
曼哈頓距離:=|x_1-y_1|+|x_2-y_2|+...+|x_n-y_n| "d(X,Y)=|x_1-y_1|+|x_2-y_2|+...+|x_n-y_n|")
閔可夫斯基距離:=\sqrt[p]{|x_1-y_1|^p+|x_2-y_2|^p+...+|x_n-y_n|^p} "d(X,Y)=\sqrt[p]{(x_1-y_1)^p+(x_2-y_2)^p+...+(x_n-y_n)^p}")
歐氏距離和曼哈頓距離可以看做是閔可夫斯基距離在p=2和p=1下的特例��。另外這三種距離都可以加權���,這個很容易理解����,不再贅述����。
下面要說一下標量的規格化問題���。上面這樣計算相異度的方式有一點問題��,就是取值范圍大的屬性對距離的影響高于取值范圍小的屬性���。例如上述例子中第三個屬性的取值跨度遠大于前兩個���,這樣不利于真實反映真實的相異度�,為了解決這個問題�,一般要對屬性值進行規格化�����。所謂規格化就是將各個屬性值按比例映射到相同的取值區間�����,這樣是為了平衡各個屬性對距離的影響����。通常將各個屬性均映射到[0,1]區間��,映射公式為:
}{max(a_i)-min(a_i)} "{a}'_i=\frac{a_i-min(a_i)}{max(a_i)-min(a_i)}")
其中max(ai)和min(ai)表示所有元素項中第i個屬性的最大值和最小值��。例如����,將示例中的元素規格化到[0,1]區間后���,就變成了X’={1,0,1}����,Y’={0,1,0}����,重新計算歐氏距離約為1.732���。
二元變量
所謂二元變量是只能取0和1兩種值變量��,有點類似布爾值�����,通常用來標識是或不是這種二值屬性�����。對于二元變量���,上一節提到的距離不能很好標識其相異度��,我們需要一種更適合的標識����。一種常用的方法是用元素相同序位同值屬性的比例來標識其相異度����。
設有X={1,0,0,0,1,0,1,1}����,Y={0,0,0,1,1,1,1,1}�,可以看到�,兩個元素第2�、3����、5��、7和8個屬性取值相同�����,而第1��、4和6個取值不同�����,那么相異度可以標識為3/8=0.375��。一般的����,對于二元變量�����,相異度可用“取值不同的同位屬性數/單個元素的屬性位數”標識�����。
上面所說的相異度應該叫做對稱二元相異度?����,F實中還有一種情況�,就是我們只關心兩者都取1的情況����,而認為兩者都取0的屬性并不意味著兩者更相似�。例如在根據病情對病人聚類時����,如果兩個人都患有肺癌����,我們認為兩個人增強了相似度�����,但如果兩個人都沒患肺癌���,并不覺得這加強了兩人的相似性�,在這種情況下����,改用“取值不同的同位屬性數/(單個元素的屬性位數-同取0的位數)”來標識相異度�����,這叫做非對稱二元相異度�。如果用1減去非對稱二元相異度���,則得到非對稱二元相似度���,也叫Jaccard系數�,是一個非常重要的概念���。
分類變量
分類變量是二元變量的推廣�,類似于程序中的枚舉變量�,但各個值沒有數字或序數意義��,如顏色���、民族等等�,對于分類變量�,用“取值不同的同位屬性數/單個元素的全部屬性數”來標識其相異度��。
序數變量
序數變量是具有序數意義的分類變量��,通?����?梢园凑找欢樞蛞饬x排列��,如冠軍����、亞軍和季軍��。對于序數變量���,一般為每個值分配一個數���,叫做這個值的秩����,然后以秩代替原值當做標量屬性計算相異度��。
向量
對于向量����,由于它不僅有大小而且有方向��,所以閔可夫斯基距離不是度量其相異度的好辦法���,一種流行的做法是用兩個向量的余弦度量�,其度量公式為:
=\frac{X^tY}{||X||||Y||} "s(X,Y)=\frac{X^tY}{||X||||Y||}")
其中||X||表示X的歐幾里得范數��。要注意��,余弦度量度量的不是兩者的相異度���,而是相似度���!
聚類問題
在討論完了相異度計算的問題��,就可以正式定義聚類問題了���。
所謂聚類問題��,就是給定一個元素集合D�,其中每個元素具有n個可觀察屬性����,使用某種算法將D劃分成k個子集��,要求每個子集內部的元素之間相異度盡可能低���,而不同子集的元素相異度盡可能高�。其中每個子集叫做一個簇����。
與分類不同���,分類是示例式學習�����,要求分類前明確各個類別��,并斷言每個元素映射到一個類別����,而聚類是觀察式學習�,在聚類前可以不知道類別甚至不給定類別數量�����,是無監督學習的一種�����。目前聚類廣泛應用于統計學��、生物學�、數據庫技術和市場營銷等領域�����,相應的算法也非常的多����。本文僅介紹一種最簡單的聚類算法——k均值(k-means)算法�。
K-means算法及其示例
k均值算法的計算過程非常直觀:
1���、從D中隨機取k個元素��,作為k個簇的各自的中心��。
2����、分別計算剩下的元素到k個簇中心的相異度���,將這些元素分別劃歸到相異度最低的簇��。
3��、根據聚類結果�����,重新計算k個簇各自的中心�,計算方法是取簇中所有元素各自維度的算術平均數�����。
4�、將D中全部元素按照新的中心重新聚類���。
5�、重復第4步�����,直到聚類結果不再變化��。
6�����、將結果輸出���。
由于算法比較直觀���,沒有什么可以過多講解的���。下面���,我們來看看k-means算法一個有趣的應用示例:中國男足近幾年到底在亞洲處于幾流水平�?
今年中國男足可算是杯具到家了����,幾乎到了過街老鼠人人喊打的地步���。對于目前中國男足在亞洲的地位����,各方也是各執一詞�����,有人說中國男足亞洲二流����,有人說三流���,還有人說根本不入流�����,更有人說其實不比日韓差多少����,是亞洲一流��。既然爭論不能解決問題��,我們就讓數據告訴我們結果吧���。
下圖是我采集的亞洲15只球隊在2005年-2010年間大型杯賽的戰績(由于澳大利亞是后來加入亞足聯的����,所以這里沒有收錄)��。
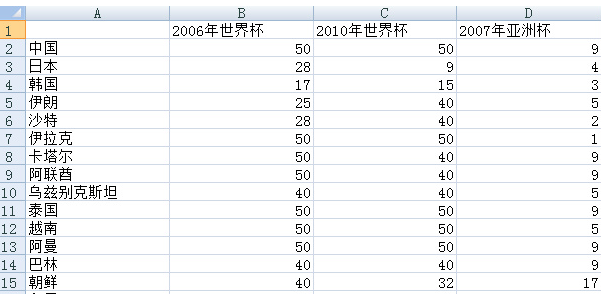
其中包括兩次世界杯和一次亞洲杯�。我提前對數據做了如下預處理:對于世界杯���,進入決賽圈則取其最終排名����,沒有進入決賽圈的����,打入預選賽十強賽賦予40�����,預選賽小組未出線的賦予50����。對于亞洲杯���,前四名取其排名����,八強賦予5�����,十六強賦予9����,預選賽沒出現的賦予17���。這樣做是為了使得所有數據變為標量��,便于后續聚類�。
下面先對數據進行[0,1]規格化����,下面是規格化后的數據:

接著用k-means算法進行聚類�。設k=3���,即將這15支球隊分成三個集團����。
現抽取日本����、巴林和泰國的值作為三個簇的種子����,即初始化三個簇的中心為A:{0.3, 0, 0.19}�����,B:{0.7, 0.76, 0.5}和C:{1, 1, 0.5}����。下面�����,計算所有球隊分別對三個中心點的相異度��,這里以歐氏距離度量��。下面是我用程序求取的結果:
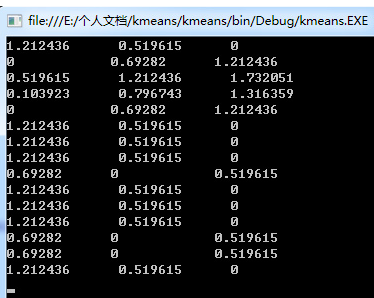
從做到右依次表示各支球隊到當前中心點的歐氏距離�,將每支球隊分到最近的簇����,可對各支球隊做如下聚類:
中國C����,日本A��,韓國A�����,伊朗A����,沙特A��,伊拉克C�,卡塔爾C�����,阿聯酋C���,烏茲別克斯坦B����,泰國C�,越南C��,阿曼C����,巴林B���,朝鮮B�,印尼C��。
第一次聚類結果:
A:日本���,韓國��,伊朗���,沙特����;
B:烏茲別克斯坦�����,巴林��,朝鮮�����;
C:中國����,伊拉克�,卡塔爾����,阿聯酋�,泰國����,越南�����,阿曼����,印尼����。
下面根據第一次聚類結果��,調整各個簇的中心點��。
A簇的新中心點為:{(0.3+0+0.24+0.3)/4=0.21, (0+0.15+0.76+0.76)/4=0.4175, (0.19+0.13+0.25+0.06)/4=0.1575} = {0.21, 0.4175, 0.1575}
用同樣的方法計算得到B和C簇的新中心點分別為{0.7, 0.7333, 0.4167}���,{1, 0.94, 0.40625}��。
用調整后的中心點再次進行聚類����,得到:
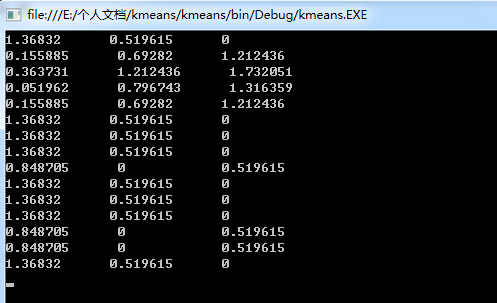
第二次迭代后的結果為:
中國C�,日本A�����,韓國A��,伊朗A��,沙特A��,伊拉克C���,卡塔爾C�����,阿聯酋C��,烏茲別克斯坦B���,泰國C�,越南C��,阿曼C���,巴林B���,朝鮮B�,印尼C��。
結果無變化��,說明結果已收斂���,于是給出最終聚類結果:
亞洲一流:日本�,韓國���,伊朗��,沙特
亞洲二流:烏茲別克斯坦����,巴林��,朝鮮
亞洲三流:中國���,伊拉克����,卡塔爾��,阿聯酋�����,泰國��,越南����,阿曼��,印尼
看來數據告訴我們��,說國足近幾年處在亞洲三流水平真的是沒有冤枉他們�����,至少從國際杯賽戰績是這樣的����。
其實上面的分析數據不僅告訴了我們聚類信息�����,還提供了一些其它有趣的信息��,例如從中可以定量分析出各個球隊之間的差距����,例如�,在亞洲一流隊伍中��,日本與沙特水平最接近�����,而伊朗則相距他們較遠����,這也和近幾年伊朗沒落的實際相符���。另外�,烏茲別克斯坦和巴林雖然沒有打進近兩屆世界杯�,不過憑借預算賽和亞洲杯上的出色表現占據B組一席之地���,而朝鮮由于打入了2010世界杯決賽圈而有幸進入B組�����,可是同樣奇跡般奪得2007年亞洲杯的伊拉克卻被分在三流�����,看來亞洲杯冠軍的分量還不如打進世界杯決賽圈重啊��。其它有趣的信息��,有興趣的朋友可以進一步挖掘����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
