SPSS實例教程:二分類Logistic回歸
某呼吸內科醫生擬探討吸煙與肺癌發生之間的關系�,開展了一項成組設計的病例對照研究�。選擇該科室內肺癌患者為病例組�����,選擇醫院內其它科室的非肺癌患者為對照組�。通過查閱病歷���、問卷調查的方式收集了病例組和對照組的以下信息:性別�����、年齡��、BMI���、COPD病史和是否吸煙����。變量的賦值和部分原始數據見表1和表2��。該醫生應該如何分析�����?
表1. 肺癌危險因素分析研究的變量與賦值
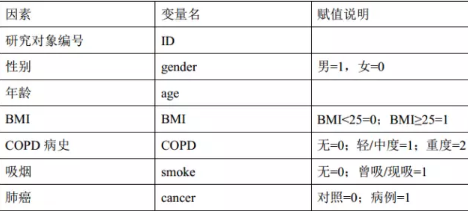
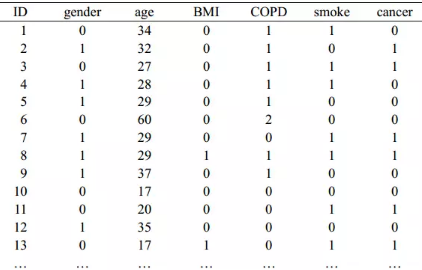
表2. 部分原始數據
2��、對數據結構的分析
該設計中�����,因變量為二分類���,自變量(病例對照研究中稱為暴露因素)有二分類變量(性別�、BMI和是否吸煙)�、連續變量(年齡)和有序多分類變量(COPD病史)���。要探討二分類因變量與自變量之間的關系����,應采用二分類Logistic回歸模型進行分析����。
在進行二分類Logistic回歸(包括其它Logistic回歸)分析前����,如果樣本不多而變量較多��,建議先通過單變量分析(t檢驗�����、卡方檢驗等)考察所有自變量與因變量之間的關系��,篩掉一些可能無意義的變量���,再進行多因素分析�����,這樣可以保證結果更加可靠���。即使樣本足夠大��,也不建議直接把所有的變量放入方程直接分析���,一定要先弄清楚各個變量之間的相互關系�����,確定自變量進入方程的形式��,這樣才能有效的進行分析����。
本例中單變量分析的結果見表3(常作為研究報告或論文中的表1)�����。
表3. 病例組和對照組暴露因素的單因素比較
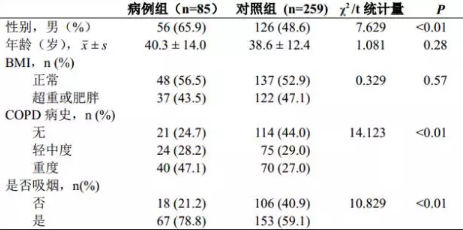
單因素分析中�,病例組和對照組之間的差異有統計學意義的自變量包括:性別�����、COPD病史和是否吸煙����。
此時����,應當考慮應該將哪些自變量納入Logistic回歸模型����。一般情況下���,建議納入的變量有:1)單因素分析差異有統計學意義的變量(此時�,最好將P值放寬一些�,比如0.1或0.15等����,避免漏掉一些重要因素)��;2)單因素分析時���,沒有發現差異有統計學意義����,但是臨床上認為與因變量關系密切的自變量�。
本研究中��,年齡和BMI與因變量沒有統計學關聯�。但是�,臨床認為年齡也是肺癌發生的可能危險因素���,因此Logistic回歸模型中����,納入以下自變量:性別���、年齡�、COPD病史和是否吸煙���。
此外�,對于連續變量���,如果僅僅是為了調整該變量帶來的混雜(不關心該變量的OR值)�����,則可以直接將改變量納入Logistic回歸模型��;如果關心該變量對因變量的影響程度(關心該變量的OR值)��,一般不直接將該連續變量納入模型�,而是將連續變量轉化為有序多分類變量后納入模型�����。 這是因為�,在Logistic回歸中直接納入連續變量�����,那么對于該變量的OR值的意義為:該變量每升高一個單位�����,發生結局事件的風險變化(比如年齡每增加1歲����,患肺癌的風險增加1.02倍)���。這種解釋在臨床上大多數是沒有意義的����。
3��、SPSS分析方法
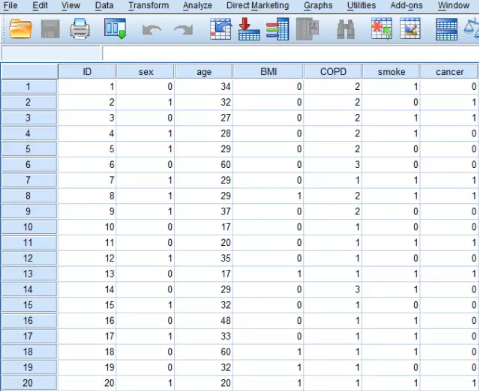
(1)數據錄入SPSS
(2)選擇Analyze→Regression→Binary Logistic

(3)選項設置
1)主對話框設置:將因變量cancer送入Dependent框中���,將納入模型的自變量sex, age, BMI和COPD變量Covariates中�����。本研究中�,納入age變量僅僅是為了調整該變量帶來的混雜(不關心該變量的OR值)�,因此將age直接將改變量納入Logistic回歸模型�。
對于自變量篩選的方法(Method對話框)����,SPSS提供了7種選擇����,使用各種方法的結果略有不同���,讀者可相互印證���。各種方法之間的差別在于變量篩選方法不同���,其中Forward: LR法(基于最大似然估計的向前逐步回歸法)的結果相對可靠�,但最終模型的選擇還需要獲得專業理論的支持�����。
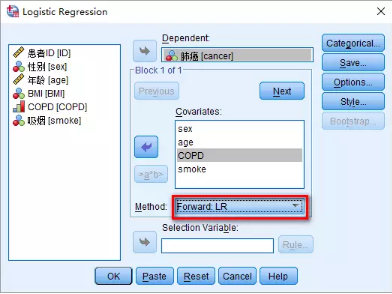
2)Categorical設置:該選項可將多分類變量(包括有序多分類和無序多分類)變換成啞變量��,指定某一分類為參照�。本研究中���,COPD是多分類變量��,我們指定“無COPD病史”的研究對象為參照組����,分別比較“輕/中度”和“重度”組相對于參照組患肺癌的風險變化��。
點擊Categorical→將左側Covariates中的COPD變量送入右側Categorical Covariates中����。點擊Contrast右側下拉菜單����,選擇Indicator(該下拉菜單內的選項是幾種與參照比較的方式�,Indicator方式最常用���,其比較方法為:第一類或最后一類為參照類�,每一類與參照類比較)����。
在Reference Category的右側選擇First(表示選擇變量COPD中�����,賦值最小的����,即“0”作為參照���。如果選擇Last則表示以賦值最大的作為參照)→點擊Change→點擊Continue�。
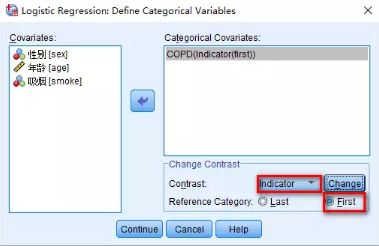
3)Options設置中���,勾選如下選項及其意義:
Hosmer-Lemeshow goodness-of-fit:檢驗模型的擬合優度����;
CI for exp(B):結果給出OR值的95%可信區間�����;
Display→At last step:僅展示變量篩選的最后一步結果�����。
→Continue→回到主界面→OK
4�����、結果解讀
Logistic回歸的結果給出了很多表格���,我們僅需要重點關注三個表格���。
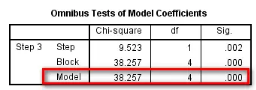
(1)Omnibus Tests of Model Coefficients:模型系數的綜合檢驗����。其中Model一行輸出了Logistic回歸模型中所有參數是否均為0的似然比檢驗結果��。P<0.05表示本次擬合的模型中���,納入的變量中�,至少有一個變量的OR值有統計學意義�,即模型總體有意義�。
(2)Hosmer and Lemeshow Test:是檢驗模型的擬合優度�。當P值不小于檢驗水準時(即P>0.05)����,認為當前數據中的信息已經被充分提取�����,模型擬合優度較高��。
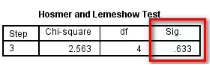
(3)Variables in the Equation:
1)本次統計過程中篩選變量的方式是Forward: LR法����,Variables in the Equation表格中列出了最終篩選進入模型的變量和其參數�����。其中Sig.一列表示相應變量在模型中的P值��,Exp (B)和95% CI for EXP (B)表示相應變量的OR值和其95%可信區間���。
對于sex, smoke這兩個二分類變量���,OR值的含義為:相對于賦值較低的研究對象(sex賦值為“0”的為女性���;smoke賦值為“0”的為不吸煙)��,賦值較高的研究對象(男性����、吸煙者)發生肺癌的風險為是多少(2.308倍�����、3.446倍)�����。
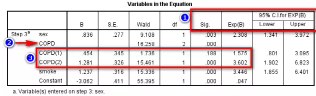
2)對于多分類變量COPD����,設置中以“0”組作為參照�,則得到的結果是“1”組����、“2”組分別對應于“0”組的OR值����。在Logistic回歸中��,設置過啞變量的多分類變量是同進同出的�����,即只要有一組相對于參照組的OR值有統計學意義��,則該變量的全部分組均納入模型����。COPD變量的第一行沒有OR值����,其P值代表該變量總體檢驗的差異有統計學意義(即至少有一組相對于參照組的OR值有統計學意義)���。
3)本研究中的COPD變量以“0”組作為參照�, 因此COPD (1)行的參數中給出了“1”相對于“0”組的OR值和P值�����,而在COPD (2)行的參數中給出了“2”組相對于“0”組的OR值和P值�����。數據分析培訓
4)Constant為回歸方程的截距��,在模型中一般沒有實際意義�,大家可不必關注�����。
5����、撰寫結論
本研究發現����,85例肺癌患者中����,吸煙者67例(78.8%)��;259例非肺癌患者中����,吸煙者153例(59.1%)�����,肺癌患者和非肺癌患者中的吸煙率的差異有統計學意義(χ2=10.829, P<0.01)�。Logistic回歸模型在調整了性別和COPD病史后��,吸煙者相對于不吸煙者��,發生肺癌的風險增加(OR=3.45, 95% CI: 1.86-6.40)�����。
多變量分析的結果見表4(常作為研究報告或論文中的表2)�����。
表4. 肺癌危險因素的Logistic回歸分析
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
