數據分析中常見的七種回歸分析以及R語言實現(一)--簡單線性模型
剛剛學習數據分析的人應該知道回歸分析是作為預測用的一種模型�,它主要是通過函數來表達因變量(連續值)和自變量變量的關系�����,通俗的來說就是Y和X的關系通過公式表達出來�;這樣能夠表明因變量和自變量之間的顯著關系并且是函數關系�����,還可以表明多個自變量對一個因變量的影響強度����,回歸分析主要運用在預測分析上���,雖然說是預測����,但是有時候我們的回歸模型只是被用來解釋現場�����,并不需要去預測���,例如���,科學家猜想人的體重和某種特定的食物消耗有關�����;
1��、線性回歸
在古典的線性回歸模型中是要滿足幾個假定:
A假設自變量和因變量存在線性關系���,具體的說就是假設因變量Y����,是一些自變量X1��,X2�,..,XN的一個線性函數它的表達式
B零均值假定���,就是假定回歸線通過X與Y的條件均值組成的點��;
C同方差假定��,就是各個隨機誤差項的離散程度是相同的��,也就是說對于每個X�,隨機項相對均值的分散程度是相同
D無自相關����,就是隨機擾動項之間是互不相關的����,互補影響����,也就是說隨機擾動項是完全隨機分布的
E因變量和擾動項是完全不相關的假定�����;
F擾動項正態性假定��,就是假定擾動項服從均值為零��,方差為司格馬的正太分布
其中回歸模型的表達式寫法如下
其中e是隨機擾動項�����,也有寫法是這樣����,Y=a+bX+e���,其中a是截距項���,b是斜率����,e是隨機擾動項�����;
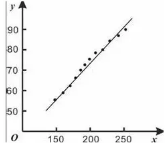
參數最優---最小二乘法
竟然存在參數���,那么如何獲取到最佳的參數呢����,簡單線性模型使用的普通最小二乘法�,這里就不寫明寫詳細步驟了�,這個可以利用搜索引擎查的得到���,我就說說它的主要思想就好�,因為我們在擬合過程的時候我們要使回歸線盡量靠近所有的樣本點�����,這時候我們就要使它們殘差盡量小���,因為殘差是有負有正�����,所以我們就采用平方去處理����,采用平方和最小原則���,通過求導����,使其導數為零���,求解得到最優的參數���,這樣就能夠使回歸模型應該使所有觀察值的殘差平方和最??�;大致就是這樣��,文字描述有些吃力�����,有什么問題可以評論一起交流
R語言實踐
這里我使用的我最近讀和做筆記的R語言核心技術手冊的包nutshell中的team.batting.00to08數據���,這個數據是2000年到2008年棒球隊的數據����,我們想要看看棒球隊的得分和每個變量的關系�����;
載入數據
library(nutshell)
data("team.batting.00to08")
查看數據的前六行
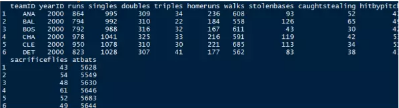
這就說明了數據已經被我們完全的載入進來了���,也知道有多少個變量以及變量的名字���,這時候我們要大體的知道一下大體的概括����,這時候使用的summary()函數
summary(team.batting.00to08)
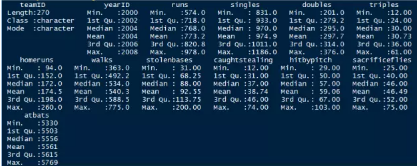
在棒球中RUNS就是球隊的得分�,時間是從2000年到2008年等
這時候想看看各個變量之間相關性如何
�,粗劣的使用cor函數得到它們之間的相關系數矩陣�,因為數據框存在字符�,所以我們要提出第一第二列
cor(team.batting.00to08[,3:10])
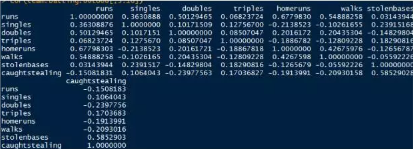
大致可以判斷的出來得分和跑動距離和全壘打(homerus)相關系數較大�����;
這里我們經常使用R語言里面的Lm函數去擬合以上變量�����,然后得到模型�����,然后使用summary()函數打印更多關于模型的信息
runs.lm <- lm(runs~singles+doubles+triples+homeruns+walks+hitbypitch+sacrificeflies+stolenbases+caughtstealing,data=team.batting.00to08)
summary(runs.lm)
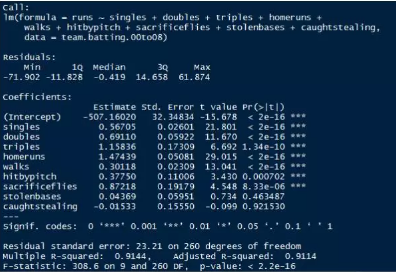
從上圖結果可以知道�,R的可決系數是0.9114�����,模型F值較大�����,通過顯著性檢驗��,其中變量caughtstealing和stolenbases和runs不顯著的關系����,這個需要剔除��;
我們可以手動剔除也可以使用step函數自動剔除
runs.lm_a <- lm(runs~singles+doubles+triples+homeruns+walks+hitbypitch+sacrificeflies,data=team.batting.00to08)
runs.lm_b<-step(runs.lm)
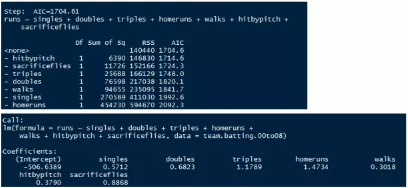
這個就講到這里���,這個下面幾篇文章會講到用什么方法得到這樣的結果
參考文獻代碼
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
