簡單的認識R語言和邏輯斯蒂回歸
在生活中并不是所有的問題都要預測一個連續型的數值�����,比如藥劑量���,某人薪水���,或者客戶價值���;邏輯斯蒂回歸回歸它主要用于只有兩個結果的分類問題�,它定義結果的變量只有兩類的值�����,然后根據線性模型來預測歸屬類的概率��;本文可能寫的淺顯��,如果有錯還望能指出來�����,因為只是寫了普及問而已�����; logistic回歸
假設有一個變量它一共只有兩類值���,現在我們需要估計出A屬于這兩個類別的概率�,假設他的線性模型是這樣的一個形式����;
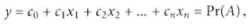
然而在上面的式子中Y值的分布不是固定的��,因為我們都知道概率只能是0-1之間��,所以我們必須要變換一下式子����,讓Y的值和概率一樣必須是0~1的數值�,一個有效的辦法就是用一個連接函數也有人稱之為聯系函數�,它大概的作用就是就是將Y變換后成為服從正態分布的變量��;這樣就可以對A進行估計了����,這就是logtistic思想�;
在logistic回歸中����,預測變量和概率之間的關系可以通過Logistic函數表示
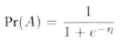
然后通過一系列的logit變換后就成為下面的式子���,感興趣的可以查閱一下資料���,這里就不寫詳細的步驟:
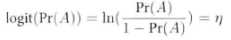
這里我們用R語言核心技術手冊里面的一系列代碼和數據來說明邏輯斯蒂回歸����;
首先是我們先載入相應的包和數據��,這個數據是關于足球射門命中的數據��,對于球員來說每次射門都是由一定的概率進球��,這個概率與距離有關�����,離球門越近越可能進球���;
library(nutshell)
data("field.goals")
這時候我們先用summary()這個函數觀察一下數據的分布
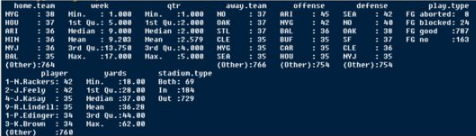
粗劣解讀一下數據�����,進球的距離最近是18碼�,最遠是62碼��;
我們下列函數是創建進球與否的份二分類變量
field.goals.forlr <- transform(field.goals,good=as.factor(ifelse(play.type=="FG good","good","bad")))
這時候我們在用summary()這個函數觀察一下射門數據的分布

大部分都是進球的��,那么我們繼續進行數據探究���,讓我們看看根據距離計算一下進球比例
field.goals.table <- table(field.goals.forlr$good,field.goals.forlr$yards)
field.goals.table
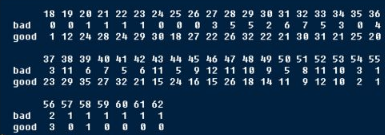
得到的結果如下
當然我們也可以畫圖出來看
plot(colnames(field.goals.table),field.goals.table["good",]/(field.goals.table["bad",]+field.goals.table["good",]))
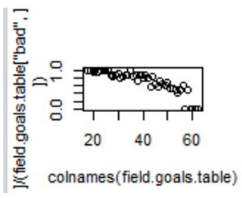
請各位自動忽略我的沒給XY命名���,人比較懶
從上圖的結果上看進球的百分比在隨著距離發生變化
這時候我們使用glm函數建模對數據進行建模�����,因為在測試數據中是每一次的射門都是獨立的��,因此我們可以認為是貝努力實驗���,因此我們在GLM函數中使用family='binomial',因此我們需要執行R代碼如下
并打印結果�����;
field.goals.mdl <- glm(good~yards,data=field.goals.forlr,family = "binomial")
summary(field.goals.mdl)
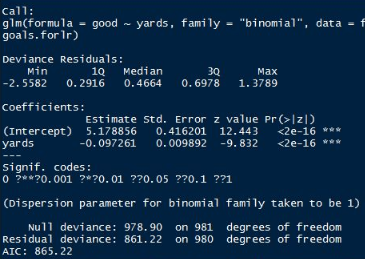
下面是一些結果的解讀
NULL deviance 是指僅包括截距項��、不包括解釋變量的模型和飽和模型比較得到的偏差統計量的值
residual deviance 是指既包括截距項����,又包括解釋變量的模型和飽和模型比較得到的偏差統計量的值
如變量的值不止兩類的情況�,可以使用其他的函數multinom函數預測概率�����;今天我們就講到這里���;有興趣的可以和我一起交流
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
