R語言學習筆記與感悟一
學習內容:1.理解數據分析系統2.R與RStudio的關系��、RStudio的基本使用3.注意事項�����、幫助函數�、管理工作空間的函數��、文本與圖形的輸入與輸出4.數據結構�����、數據的輸入5.添加變量標簽和值標簽��、處理數據對象的函數
主要學習材料:1.《R語言實戰》Chapter 1&22.猴子知乎Live第二講:

數據結構入門
蓋房子 = 材料 + 整合材料程序 = 數據結構 + 算法
R與RStudio的區別:
R是運行環境����;RStudio是開發工具��,為了更方便地使用R語言�,用于代碼的編輯�、調試���、圖形顯示�。
在RStudio中導入數據后�����,工作空間中會顯示內存中保存的對象�。
R Studio中的注釋部分與代碼部分有顏色的區分���,內置函數與外來輸入的部分能通過顏色區分�。
RStudio的使用:
1. RStudio的組成:
控制臺Console:輸入命令及顯示輸出結果
代碼編輯器
工作空間
目錄�����,同時也是圖形輸出設備所在處
2. 創建項目和腳本
File -> New Project -> New Directory -> Empty Project
File -> New File -> R Script在腳本中寫入R的代碼�,腳本文件的后綴為.R
3. 運行代碼
Step1: 在腳本中選中要運行的代碼Step2: Code — Run Lines運行結果會顯示在控制臺中
4. 更改RStudio背景色
Tools -> Global Options -> Appearance然后在Editor Theme中選擇背景
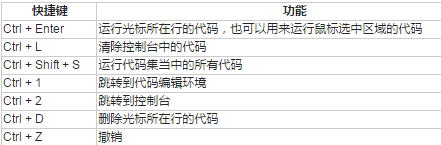
5. R Studio中的快捷鍵
第一章 R語言介紹
一��、注意事項:
區分大小寫 邏輯值TRUE和FALSE全部大寫
在命令提示符(>)后每次輸入并執行一條命令���,或者一次性執行寫在腳本文件中的一組命R使用<-�����,而不是傳統的 = 作為賦值符
注釋由符號 # 開頭���,在 # 之后出現的任何文本都會被R解釋器忽略
路徑中使用一個正斜杠/或兩個反斜杠\\,使用引號閉合目錄名和文件名
輸入字符串時要加引號���,單引號和雙引號皆可
二����、常用函數:
(截圖來自《R語言實戰》)
注意:
導入數據前���,必須先設置當前工作目錄要導入存在另一個工作目錄下的數據���,必須先改變工作目錄再讀入數據
函數setwd()不會自動創建一個不存在的目錄�?��?梢允褂煤瘮礵ir.create()來創建新目錄�,然后使用setwd()將工作目錄指向這個新目錄���。
啟動一個R會話時使用setwd()命令指定到某一個項目的路徑��,后接不加選項的load()命令���,這樣做可以從上一次會話結束的地方重新開始�。
實踐示例:setwd("C:/myprojects/project1") #當前工作目錄被設置為C:/myprojects/project1
options() #當前的選項設置情況將顯示出來
options(digits=3) #顯示為小數點后三位有效數字
x <- runif(20) #創建一個包含20個均勻分布隨機變量的向量
summary(x) #生成摘要統計量
hist(x) #生成直方圖
savehistory() #命令的歷史記錄保存到文件.Rhistory中
save.image() #工作空間(包含向量x)保存到文件.RData中
q() #會話結束
三��、輸入與輸出
輸入:
函數source("filename")可在當前會話中執行一個腳本���。如果文件名中不包含路徑�����,R將假設此腳本在當前工作目錄中�。
文本輸出:
函數sink("filename")將輸出重定向到文件filename中���。使用參數append=TRUE可以將文本追加到文件后��,而不是覆蓋它����。參數split=TRUE可將輸出同時發送到屏幕和輸出文件中�。不加參數調用命令sink()將僅向屏幕返回輸出結果�����。
圖形輸出:
要重定向圖形輸出�,使用表1-4中列出的函數即可����。最后使用dev.off()將輸出返回到終端��。

實踐示例1:
sink("myoutput", append=TRUE, split=TRUE)
pdf("mygraphs.pdf")
source("script2.R")
文件script2.R中的R代碼將執行�,結果也將顯示在屏幕上��。此外�,文本輸出將被追加到文件myoutput中���,圖形輸出將保存到文件mygraphs.pdf中�。
實踐示例2:
sink()
dev.off()
source("script3.R")
文件script3.R中的R代碼將執行�����,結果將顯示在屏幕上�����,沒有文本和圖形輸出保存到文件中���。
待解決疑問1:
在上述兩個示例中����,為什么不是先使用輸入函數source(),而是先使用輸出函數��?
四����、R包
install.packages("package_name")安裝包
library("package_name")載入包�����,包安裝后必須先載入才能使用
update.packages("package_name")更新已經安裝的包
search()可以告訴你哪些包已加載并可使用
installed.packages()查看已安裝的包的描述��,將列出安裝的包
library()顯示庫(存儲包的目錄)中有哪些包
.libPaths()顯示庫所在的位置
help(package="package_name")可以輸出某個包的簡短描述以及包中的函數名稱和數據集名稱的列表
實踐示例:
install.packages("vcd") #安裝vcd包
help(package="vcd") #列出此包中可用的函數和數據集
library(vcd) #載入這個包
help(Arthritis) #查看數據集Arthritis的描述
Arthritis #顯示數據集Arthritis的內容
example(Arthritis) #運行數據集Arthritis的自帶的示例
q() #退出
第二章 創建數據集(數據分析的第一步)
包括兩個步驟:1.選擇一種數據結構來存儲數據�;2.將數據輸入或導入到這個數據結構中��。
一���、數據結構
向量�、矩陣�、數組中的數據必須是同種類型�;數據框和列表中的數據可以是不同類型
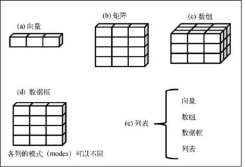
1. 向量
向量是用于存儲數值型��、字符型或邏輯型數據的一維數組��。用函數c()來創建向量��。
a <- c(1,2,5,3,6,-2,4)
b <- c("one", "two", "three")
c <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE)
使用:
單個向量中的數據必須擁有相同的數據類型(數值型�����、字符型或邏輯型)�����。
獲取向量的長度 length(vector_name)
要訪問向量中的某個元素��,在方括號中給定元素所處位置的數值��,例如:a[c(2, 4)]用于訪問向量a中的第二個和第四個元素��。
由于R中內置了同名函數c()���,最好不要在編碼時使用c作為對象名��。
R中沒有標量����。標量是只含一個元素的向量�,例如f <- 3��、g <- "US"和h <- TRUE ,它們用于保存常量��。
冒號用于生成一個數值序列��。例如���,a <- c(2:6)等價于a <- c(2,3, 4, 5, 6)�����。
2. 矩陣
矩陣是一個二維數組����,每個元素都擁有相同的類型(數值型���、字符型或邏輯型)�。
可通過函數matrix創建矩陣��。
mymatrix <- matrix(vector,
nrow=number_of_rows, ncol=number_of_columns,
byrow=logical_value,
dimnames=list(char_vector_rownames, char_vector_colnames))
vector包含了矩陣的元素�,是一個向量
nrow和ncol用以指定行和列的維數
byrow則表明矩陣應當按行填充(byrow=TRUE)還是按列填充(byrow=FALSE)�����,默認情況下按列填充
dimnames包含了可選的�����、以字符型向量表示的行名和列名實踐示例:cells <- c(1,26,24,68)
rnames <- c("R1", "R2")
cnames <- c("C1", "C2")
mymatrix <- matrix(cells, nrow=2, ncol=2, byrow=TRUE, dimnames=list(rnames, cnames)使用:
訪問矩陣中的行�、列或元素X[i,]指矩陣X中的第i 行�����,X[,j]指第j 列����,X[i, j]指第i 行第j 個元素���,如:x[2,] #選取矩陣x中第二行的元素x[,2] #選取矩陣x中第二列的元素x[1,4] #選取矩陣x中位于第一行第四列的元素選擇多行或多列時�,下標i 和j 可為數值型向量�����,如:x[1, c(4,5)] #選取矩陣x第一行中位于第四列和第五列的元素
矩陣的作用: 繪制圖形
3. 數組
數組(array)維度可以大于2�����,數據只能擁有一種類型�����。行表示觀測����,列表示變量�。
數組可通過array函數創建����。myarray <- array(vector, dimensions, dimnames)
vector包含了數組中的數據 ��,是一個向量
dimensions是數值型向量�����,給出了各個維度下標的最大值
dimnames是各維度名稱的列表實踐示例:data <- 1:24
dim1 <- c("A1", "A2")
dim2 <- c("B1", "B2", "B3")
dim3 <- c("C1", "C2", "C3", "C4")
z <- array(data, c(2, 3, 4), dimnames=list(dim1, dim2, dim3))
4.數據框
數據框是數據分析中最常用的數據結構不同的列可以包含不同類型(數值型��、字符型等)的數據��,但是每一列的數據類型必須唯一�。
數據框可通過函數data.frame()創建�。mydata <- data.frame(col1, col2, col3, ...)
使用:
選取數據框中元素1.使用下標記號patientdata[1:2] #選取名為patientdata數據框中的第一列至第二列元素2.直接指定列名patientdata[c("diabetes", "status")] #選取patientdata數據框中列名分別為diabetes和status所在列的元素3.用$和列名選取一個給定數據框中的某一列patientdata$age #選取patientdata數據框中列名為age所在列的元素
求數據框的行數例如:求患者總數patientNumber <- nrow(patientdata)
求滿足某一特征的數據個數例如:求患有“1型糖尿病”的患者人數Step1: 使用==找到符合條件的數據��,并賦值給新的數據框type1 <- patientdata[patientdata$diabetes == "1型糖尿病"]type1也是一個數據框���,僅包含符合糖尿病類型為“1型糖尿病”的患者Step2: 求type1數據框的行數type1.number <- nrow(type1)對象名稱中的句點(.)沒有特殊意義�����。
在數據框中按行添加新數據用rbind函數Step1:將要添加的數據放入新的數據框中
patientID <- c(5)
age <- c(30)
diabetes <- c("1型糖尿病")
status <- c("較差")
newPatient <- data.frame(patientID, age, diabetes, status, stringsAsFactors=FALSE)
Step2:將新數據框用rbind函數加入原數據框patientdata <- rbind(patientdata, newPatient)
在數據框中按列添加新數據用cbind函數Step1:由于列在數據框中相當于向量���,所以將新數據首先放入新的向量中inTime <- c("2015-3-1", "2014-12-31", "2015-10-1", "2015-5-1", "2016-12-31")Step2:將新定義的向量用cbind函數加入原數據框patientdata <- cbind(patientdata, inTime)
5.列表
列表允許將若干(可能無關的)對象整合到單個對象名下�。例如���,某個列表中可能是若干向量�、矩陣�����、數據框�����,甚至其他列表的組合��。
使用函數list()創建列表mylist <- list(object1, object2, ...)還可以為列表中的對象命名mylist <- list(name1=object1, name2=object2, ...)其中的對象可以是目前為止講到的任何結構���。
使用:
常用于存儲各種類型函數的返回結果
計算業務指標KPI例如:存儲業務指標一“患有‘1型糖尿病’的患者信息”和業務指標二“病人的數量”為KPI結果kpi <- list(diabetesType=type1, number=number) #列表中的業務指標一diabetesType是一個數據框�,業務指標二number是一個數值��,起名字是為了方便后期查找
訪問列表中的元素在雙重方括號中指明代表某個成分的數字或名稱例如:獲取列表中的業務指標二“病人數量”�����,并賦值給向量numbernumber <- kpi[["number"]]或number <- kpi[[2]] #獲取列表kpi中的第二個成分��,并賦值給numbe
6.因子
變量可歸結為名義型��、有序型或連續型變量�。
名義型變量是沒有順序之分的類別變量���。糖尿病類型Diabetes(Type1��、Type2)是名義型變量����,即使在數據中Type1編碼為1而Type2編碼為2�����,也不意味著二者是有序的��。
有序型變量表示一種順序關系�,而非數量關系�。病情Status(poor, improved, excellent)是順序型變量�,病情為poor(較差)病人的狀態不如improved(病情好轉)的病人�,但并不知道相差多少�����。
連續型變量可以呈現為某個范圍內的任意值����,并同時表示了順序和數量����。年齡Age就是一個連續型變量��,它能夠表示像14.5或22.8這樣的值以及其間的其他任意值�。15歲的人比14歲的人年長一歲
因子:類別(名義型)變量和有序類別(有序型)變量在R中稱為因子(factor)�。因子在R中非常重要����,因為它決定了數據的分析方式以及如何進行視覺呈現����。
函數factor()以一個整數向量的形式存儲類別值�,整數的取值范圍是[1... k ](其中k 是名義型變量中唯一值的個數)�����,同時一個由字符串(原始值)組成的內部向量將映射到這些整數上��。舉例來說��,假設有向量:diabetes <- c("Type1", "Type2", "Type1", "Type1")語句diabetes <- factor(diabetes)將此向量存儲為(1, 2, 1, 1)���,并在內部將其關聯為1=Type1和2=Type2(具體賦值根據字母順序而定)��。針對向量diabetes進行的任何分析都會將其作為名義型變量對待�����,并自動選擇適合這一測量尺度的統計方法��。(這里的測量尺度是指定類尺度��、定序尺度�����、定距尺度�、定比尺度中的定類尺度�����。)
要表示有序型變量��,需要為函數factor()指定參數ordered=TRUE給定向量:status <- c("Poor", "Improved", "Excellent", "Poor")語句status <- factor(status, ordered=TRUE)會將向量編碼為(3, 2, 1, 3)���,并在內部將這些值關聯為1=Excellent���、2=Improved以及3=Poor�。針對此向量進行的任何分析都會將其作為有序型變量對待��,并自動選擇合適的統計方法�。對于字符型向量��,因子的水平默認依字母順序創建�����?���?梢酝ㄟ^指定levels選項來覆蓋默認排序���。例如:
status <- factor(status, ordered=TRUE��,
levels=c("Poor", "Improved", "Excellent"))
各水平的賦值將為1=Poor�����、2=Improved���、3=Excellent�。
關于$使用的補充:當需要多次重復引用同一個數據框名稱時��,為了避免在每個變量名前都鍵入一次“數據框名稱+$”�����,可以通過以下替代方法:
使用attach()和detach()函數attach()可將數據框添加到R的搜索路徑中���。函數detach()將數據框從搜索路徑中移除�����。R在遇到一個變量名以后�����,將檢查搜索路徑中的數據框����,以定位到這個變量�。例如:從mtcars數據框中獲取每加侖行駛英里數(mpg)變量的描述性統計量�,并分別繪制此變量與發動機排量(disp)和車身重量(wt)的散點圖:
attach(mtcars)
summary(mpg)
plot(mpg, disp)
plot(mpg, wt)
detach(mtcars)
此方法主要適用于名稱相同的對象只有一個的情況��。若數據框被綁定之前已經用與數據框中某對象相同的名稱定義了新的對象�����,則該新對象取得優先權�,可能會由于兩個對象的元素個數不同而出錯���。

使用with()函數對于上例:
with(mtcars, {
summary(mpg, disp, wt)
plot(mpg, disp)
plot(mpg, wt)
})
大括號{}之間的語句都針對數據框mtcars執行����,這樣就無須擔心名稱沖突了���。如果僅有一條語句(例如summary(mpg))�����,那么大括號{}可以省略����。函數with()的局限性: 賦值僅在此函數的括號內生效���。要創建在with()結構以外存在的對象��,使用特殊賦值符<<-替代標準賦值符(<-)��。

實例標識符在R中�����,實例標識符(case identifier)可通過數據框操作函數中的rowname選項指定�����。例如����,在病例數據中�����,病人編號(patientID)用于區分數據集中不同的個體:
patientdata <- data.frame(patientID, age, diabetes, status,
row.names=patientID)
二��、數據的輸入(最常用的幾種)
1. 使用鍵盤輸入數據
對于小數據集很有效函數edit()會自動調用一個允許手動輸入數據的文本編輯器�����。
Step1: 創建一個空數據框(或矩陣)���,其中變量名和變量的模式需與理想中的最終數據集一致����;
Step2: 針對這個數據對象調用文本編輯器��,輸入數據�,并將結果保存回此數據對象中����。
例如:創建一個名為mydata的數據框��,含有三個變量:age(數值型)����、gender(字符型)和weight(數值型)���,然后調用文本編輯器���,鍵入數據��,最后保存結果�。
mydata <- data.frame(age=numeric(0), gender=character(0), weight=numeric(0))
mydata <- edit(mydata)
類似于age=numeric(0)的賦值語句將創建一個指定數據類型但不含實際數據的變量�����。
編輯的結果需要賦值回對象本身!!!!!!語句mydata <- edit(mydata)的一種簡捷的等價寫法是fix(mydata)����。
調用出文本編輯器后��,單擊列的標題����,可以用編輯器修改變量名和變量類型(數值型�、字符型)��。還可以通過單擊未使用列的標題來添加新的變量���。
2. 從帶分隔符的文本文件導入數據
使用read.table()函數�����,可讀入一個表格格式的文件并將其保存為一個數據框��。mydataframe <- read.table(file, header=logical_value, sep="delimiter", row.names="name"
file是一個帶分隔符的ASCII文本文件
header是一個表明首行是否包含了變量名的邏輯值(TRUE或FALSE)
sep用來指定分隔數據的分隔符
row.names是一個可選參數���,用以指定一個或多個表示行標識符的變量
例如:從當前工作目錄中讀入了一個名為studentgrades.csv的逗號分隔文件�,從文件的第一行取得了各變量名稱�����,將變量STUDENTID指定為行標識符����,最后將結果保存到了名為grades的數據框中����。grades <- read.table("studentgrades.csv", header=TRUE, sep=",", row.names="STUDENTID")
默認情況下�����,字符型變量將轉換為因子�����。禁止這種轉換的方法:
法一:設置stringsAsFactors=FALSE
法二:使用選項colClasses為每一列指定一個類��,例如logical(邏輯型)���、numeric(數值型)��、character(字符型)�����、factor(因子)��。
3. 導入Excel數據
讀取一個Excel文件的最好方式�����,就是在Excel中將其導出為一個逗號分隔文件(csv)�,并使用前文描述的方式將其導入R中���。
在Windows系統中����,也可以使用RODBC包來訪問Excel文件�����。

實踐示例:
install.packages("RODBC")
library(RODBC)
channel <- odbcConnectExcel("myfile.xls")
mydataframe <- sqlFetch(channel, "mysheet")
odbcClose(channel)
myfile.xls是一個Excel文件mysheet是要從這個工作簿中讀取工作表的名稱channel是一個由odbcConnectExcel()返回的RODBC連接對象mydataframe是返回的數據框
XLSX格式的電子表格��,可以用xlsx包來讀取�。xlsx包不僅僅可以導入數據表���,它還能夠創建和操作XLSX文件�����。包中的函數read.xlsx()可將XLSX文件中的工作表導入為一個數據框���。其最簡單的調用格式是read.xlsx(file, n)��,其中file是Excel工作簿的所在路徑���,n則為要導入的工作表序號����。
library(xlsx)
workbook <- "C:/myworkbook.xlsx"
mydataframe <- read.xlsx(workbook,1)
從位于C盤根目錄的工作簿myworkbook.xlsx中導入了第一個工作表����,并將其保存為一個數據框mydataframe����。
4.從網頁抓取數據
使用函數readLines()下載網頁����,然后使用如grep()和gsub()一類的函數處理它����。對于結構復雜的網頁�����,可以使用RCurl包和XML包來提取其中想要的信息�����。
其他還包括導入XML數據��、導入SPSS數據�����、導入SAS數據����、導入Stata數據�、導入netCDF數據�、導入HDF5 數據��、訪問數據庫管理系統��、通過Stat/Transfer導入數據�,等用到時再詳細補充��,現在理解起來有些抽象�。
三��、數據集的標注
1. 變量標簽
為變量名添加描述性的標簽方法:將變量標簽作為變量名�����,然后通過位置下標來訪問這個變量��。
例如����,對于數據框patientdata中的第二列包含著個體首次入院時年齡的變量age���,附加一個描述更詳細的標簽“Age at hospitalization (in years)”(入院年齡)names(patientdata)[2] <- "Age at hospitalization(in years)"將age重命名為"Age at hospitalization (in years)"��。新的變量名太長��,不適合重復輸入����,作為替代��,可以使用patientdata[2]來引用這個變量�����,而在本應輸出age的地方輸出字符串"Age at hospitalization (in years)"����。
待解決疑問2:為變量名添加描述性標簽是否等同于更改變量名���?
2. 值標簽
函數factor()為類別型變量中的編碼添加值標簽
例如��,假設有一個名為gender的變量�����,其中1表示男性����,2表示女性�,將其關聯到標簽“male”和“female”上
patientdata$gender <- factor(patientdata$gender,
levels=c(1,2),
labels=c("male", "female"))
注意:這里levels標簽中的數字代表實際值而不是順序�����!
四���、處理數據對象的實用函數

學習感悟:
正在努力培養自己將知識形成體系的能力��,剛剛選定OneNote作為主要工具����,各種功能還在進一步的探索當中���。R語言的這部分內容在第一遍學習時�,就邊學邊進行了整理���,算是把書讀薄的過程�,這次是第二遍�,在腦中形成了知識架構�����,同時把零散的知識點插入到架構中合適的位置�。知識結構清晰后����,很多原有的疑惑會迎刃而解�����,同時也會發現新的問題��,接下來還會不斷在實踐中鞏固容易遺忘的知識點并解決老問題�����。
最近一直在摸索適合自己的學習方式����。我在吸收新知識方面比較慢�����,所以第一遍都會踏踏實實地學習���,標記出不明白的地方���,但是不會硬磕����,過一段時間再看看可能就自然而然地想通了���,很多時候后續知識的學習會促進前期知識的理解���。因為記憶力一般��,所以學習新知識時更適合拿出整塊的時間來學習同一科目���,這樣可以有效降低每次學習前都要先回顧之前的知識點而花費的時間�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;












 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
