使用R進行傾向得分匹配(PSM)
根據維基百科�,傾向得分匹配(PSM)是一種用來評估處置效應的統計方法����。廣義說來���,它將樣本根據其特性分類��,而不同類樣本間的差異就可以看作處置效應的無偏估計��。因此�,PSM不僅僅是隨機試驗的一種替代方法���,它也是流行病研究中進行樣本比較的重要方法之一����。讓我們舉個栗子:
與健康相關的生活質量(HRQOL)被認為是癌癥治療的重要結果之一�。對癌癥患者而言�,最常用的HRQOL測度是通過歐洲癌癥研究與治療中心的調查問卷計算得出的���。EORTC QLD-C30是一個由30個項目組成���,包括5個功能量表�,9個癥狀量表和一個全球生活質量量表的的問卷��。所有量表都會給出一個0-100之間的得分�。癥狀量表得分越高代表被調查人生活壓力越大�,其余兩個量表得分越高代表生活質量越高��。
然而��,如果沒有任何參照��,直接對數據進行解釋是很困難的�����。幸運的是�����,EORTC QLQ-C30問卷也在一些一般人群調查中使用��,我們可以對比患者的得分和一般人群的得分差異�����,從而判斷患者的負擔癥狀和一些功能障礙是否能歸因于癌癥治療�����。PSM在這里可以以年齡和性別等特征�,將相似的患者和一般人群進行匹配���。
生成兩個隨機數據框
由于我不希望在本文使用真實數據���,我需要生成一些仿真數據���。使用Wakefield包可以很容易地實現這個功能����。
第一步���,我們創建一個名為df.patients的數據框�,我希望它包含250個病人的年齡和性別數據�,所有病人的年齡都要在30-78歲之間�����,并且70%的病人被設定為男性��。
set.seed(1234)
df.patients <- r_data_frame(n = 250,
age(x = 30:78,
name = 'Age'),
sex(x = c("Male", "Female"),
prob = c(0.70, 0.30),
name = "Sex"))
df.patients$Sample <- as.factor('Patients')
summary函數會返回創建的數據框的基本信息�����,如你所見��,患者平均年齡為53.7歲���,并且大約70%為男性�。
summary(df.patients)
## Age Sex Sample
## Min. :30.00 Male :173 Patients:250
## 1st Qu.:42.00 Female: 77
## Median :54.00
## Mean :53.71
## 3rd Qu.:66.00
## Max. :78.00
第二步�,我們需要創建另一個名為df.population的數據框�����。我希望這個數據集的數據和患者的有些不同��,因此正常人群的年齡區間被設定為18-80歲���,并且男女各占一半����。
set.seed(1234)
df.population <- r_data_frame(n = 1000,
age(x = 18:80,
name = 'Age'),
sex(x = c("Male", "Female"),
prob = c(0.50, 0.50),
name = "Sex"))
df.population$Sample <- as.factor('Population')
下方表格顯示樣本平均年齡為49.5歲��,男女比例也大致相等��。
summary(df.population)
## Age Sex Sample
## Min. :18.00 Male :485 Population:1000
## 1st Qu.:34.00 Female:515
## Median :50.00
## Mean :49.46
## 3rd Qu.:65.00
## Max. :80.00
合并數據框
在匹配樣本之前�,我們需要把兩個數據框合并��。先生成一個新變量Group來代表觀測來自哪個全體(邏輯型變量)����,再添加另一個變量Distress來反應個體的痛苦程度��。Distress變量是利用Wakefield包中的age函數創建的�,可以發現���,女性承受的痛苦級別更高�。
mydata <- rbind(df.patients, df.population)
mydata$Group <- as.logical(mydata$Sample == 'Patients')
mydata$Distress <- ifelsmydata <- rbind(df.patients, df.population)
mydata$Group <- as.logical(mydata$Sample == 'Patients')
mydata$Distress <- ifelse(mydata$Sex == 'Male', age(nrow(mydata), x = 0:42, name = 'Distress'),
age(nrow(mydata), x = 15:42, name = 'Distress'))
當我們比較兩類樣本的年齡和性別分布時�����,我們可以發現明顯的區別:
pacman::p_load(tableone)
table1 <- CreateTableOne(vars = c('Age', 'Sex', 'Distress'),
data = mydata,
factorVars = 'Sex',
strata = 'Sample')
table1 <- print(table1,
printToggle = FALSE,
noSpaces = TRUE)
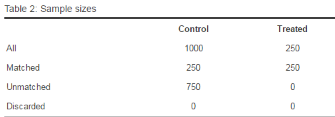
kable(table1[,1:3],
align = 'c',
caption = 'Table 1: Comparison of unmatched samples')
更進一步����,我們還發現一般人群的痛苦程度顯著較高�����。
樣本匹配
現在����,我們已經完成了全部的準備工作�����,可以開始使用MatchIT包中的matchit函數來匹配兩類樣本了����。函數中method=‘nearest’的設定指明了使用近鄰法進行匹配���。其他方法包括�,次分類��,優化匹配等��。ratio=1意味著這是一一配對��。同時也請注意Group變量需要是邏輯型變量�����。
set.seed(1234)
match.it <- matchit(Group ~ Age + Sex, data = mydata, method="nearest", ratio=1)
a <- summary(match.it)
為了后續工作的便利�����,我們將summary函數的輸出賦值給名為a的變量����。
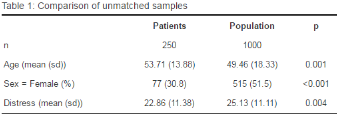
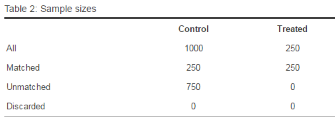
在匹配萬樣本后���,一般人群樣本量所見到了和患者樣本一致(250個觀測)�����。
kable(a$nn, digits = 2, align = 'c',
caption = 'Table 2: Sample sizes')
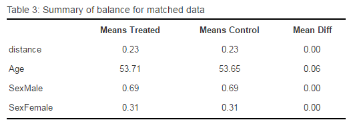
根據輸出結果����,匹配后的年齡和性別分布基本一致了���。
kable(a$sum.matched[c(1,2,4)], digits = 2, align = 'c',
caption = 'Table 3: Summary of balance for matched data')
傾向得分的分布可以使用MatchIt包中的plot函數進行繪制����。
plot(match.it, type = 'jitter', interactive = FALSE)
輸出如下:
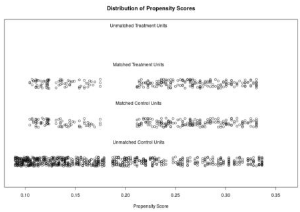
保存匹配樣本
最后��,讓我們把匹配好的樣本保存在df.match數據框里���。
df.match <- match.data(match.it)[1:ncol(mydata)]
rm(df.patients, df.population)
現在pacman::p_load(tableone)
table4 <- CreateTableOne(vars = c('Age', 'Sex', 'Distress'),
data = df.match,
factorVars = 'Sex',
strata = 'Sample')
table4 <- print(table4,
printToggle = FALSE,
noSpaces = TRUE)
kable(table4[,1:3],
align = 'c',
caption = 'Table 4: Comparison of matched samples')���,我們可以對比兩類人群間痛苦程度的差異是否依舊顯著���。
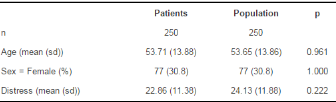
由于p值為0.222����,學生t檢驗的結果不再顯著��。因此��,PSM幫助我們避免犯下第一類錯誤����。
P.S.1:本文只用的所有包可通過如下代碼加載:數據分析師培訓
pacman::p_load(knitr, wakefield, MatchIt, tableone, captioner)
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
