R語言不平衡數據分類指南
目前我們發展出了不少機器學習算法來對數據建模�,基于數據進行一些預測已經不再是難事����。不論我們建立的是回歸或是分類模型�,只要我們選擇了合適的算法����,總能得到比較精確的結果�。然而�����,世事并不總是一帆風順�����,某些分類問題可能比較棘手���。
在對不平衡的分類數據集進行建模時�,機器學習算法可能并不穩定�����,其預測結果甚至可能是有偏的��,而預測精度此時也變得帶有誤導性�。那么����,這種結果是為何發生的呢�����?到底是什么因素影響了這些算法的表現�?
答案非常簡單����,在不平衡的數據中�����,任一算法都沒法從樣本量少的類中獲取足夠的信息來進行精確預測�。因此��,機器學習算法常常被要求應用在平衡數據集上�。那我們該如何處理不平衡數據集�����?本文會介紹一些相關方法�,它們并不復雜只是技巧性比較強�����。
本文會介紹處理非平衡分類數據集的一些要點�����,并主要集中于非平衡二分類問題的處理�。一如既往����,我會盡量精簡地敘述�����,在文末我會演示如何用R中的ROSE包來解決實際問題����。
什么是不平衡分類
不平衡分類是一種有監督學習����,但它處理的對象中有一個類所占的比例遠遠大于其余類��。比起多分類����,這一問題在二分類中更為常見�����。(注:下文中占比較大的類稱為大類��,占比較小的類稱為小類)
不平衡一詞指代數據中響應變量(被解釋變量)的分布不均衡���,如果一個數據集的響應變量在不同類上的分布差別較大我們就認為它不平衡��。
舉個例子�����,假設我們有一個觀測數為100000的數據集��,它包含了哈佛大學申請人的信息����。眾所周知���,哈佛大學以極低的錄取比例而聞名�����,那么這個數據集的響應變量(即:該申請人是否被錄取����,是為1��,否為0)就很不平衡�,大致98%的觀測響應變量為0�����,只有2%的幸運兒被錄取��。
在現實生活中��,這類例子更是不勝枚舉���,我在下面列舉了一些實例�,請注意他們的不平衡度是不一樣的�。
1.一個自動產品質量檢測機每天會檢測工廠生產的產品��,你會發現次品率是遠遠低于合格率的��。
2.某地區進行了居民癌癥普查�,結果患有癌癥的居民人數也是遠遠少于健康人群�。
3.在信用卡欺詐數據中�����,違規交易數比合規交易少不少����。
4.一個遵循6\(\sigma\) 原則的生產車間每生產100萬個產品才會產出10個次品�����。
生活中的例子還有太多��,現在你可以發現獲取這些非平衡數據的可能性有多大����,所以掌握這些數據集的處理方法也是每個數據分析師的必修課�����。
為什么大部分機器學習算法在不平衡數據集上表現不佳�����?
我覺得這是一個很有意思的問題�,你不妨自己先動手試試����,然后你就會了解把不平衡數據再結構化的重要性�����,至于如何再結構化���,我會在操作部分中講解����。
下面是機器學習算法在不平衡數據上精度下降的原因:
響應變量的分布不均勻使得算法精度下降�,對于小類的預測精度會很低�。
算法本身是精度驅動的�,即該模型的目標是最小化總體誤差�����,而小類對于總體誤差的貢獻很低���。
算法本身假設數據集的類分布均衡��,同時它們也可能假定不同類別的誤差帶來相同的損失(下文會詳細敘述)��。
針對不平衡數據的處理方法
這類處理方法其實就是大名鼎鼎的“采樣法”����,總的說來����,應用這些方法都是為了把不平衡數據修正為平衡數據����。修正方法就是調整原始數據集的樣本量����,使得不同類的數據比例一致���。
而在諸多學者研究得出基于平衡數據的模型整體更優的結論后����,這一類方法越來越受到分析師們的青睞��。
下列是一些具體的處理方法名稱:
欠采樣法(Undersampling)
過采樣法(Oversampling)
人工數據合成法(Synthetic Data Generation)
代價敏感學習法(Cose Sensitive Learning)
讓我們逐一了解它們�。
1.欠采樣法
該方法主要是對大類進行處理�����。它會減少大類的觀測數來使得數據集平衡����。這一辦法在數據集整體很大時較為適宜�����,它還可以通過降低訓練樣本量來減少計算時間和存儲開銷����。
欠采樣法共有兩類:隨機(Random)的和有信息的(Informative)���。
隨機欠采樣法會隨機刪除大類的觀測直至數據集平衡�。有信息的欠采樣法則會依照一個事先制定的準則來刪去觀測����。
有信息的欠采樣中�����,利用簡易集成算法(EasyEnsemble)和平衡級聯算法(BalanceCascade)往往能得到比較好的結果�。這兩種算法也都很直白易懂����。
簡易集成法:首先�����,它將從大類中有放回地抽取一些獨立樣本生成多個子集�。然后��,將這些子集和小類的觀測合并����,再基于合并后的數據集訓練多個分類器���,以其中多數分類器的分類結果為預測結果�����。如你所見����,整個流程和無監督學習非常相似�����。(注:譯者認為更像基于Bagging的隨機森林)
平衡級聯法:它是一種有監督的學習法����,首先將生成多個分類器��,再基于一定規則系統地篩選哪些大類樣本應當被保留����。(譯者注:算法整體是一個迭代至收斂的過程)
但欠采樣法有一個顯而易見的缺陷����,由于要刪去不少觀測�����,使用該方法會使得大類損失不少重要信息�����。
2.過采樣法
這一方法針對小類進行處理����。它會以重復小類的觀測的方式來平衡數據�。該方法也被稱作升采樣(Upsampling)��。和欠采樣類似���,它也能分為隨機過采樣和有信息的過采樣兩類�。
隨機過采樣會將小類觀測隨機重復����。有信息過采樣也是遵循一定的準則來人工合成小類觀測�����。
使用該方法的一大優勢是沒有任何信息損失���。缺點則是由于增加了小類的重復樣本��,很有可能導致過擬合(譯者注:計算時間和存儲開銷也增大不少)�����。我們通過該方法可以在訓練集上得到非常高的擬合精度��,但在測試集上預測的表現則可能變得愈發糟糕���。
人工數據合成法
簡單說來�����,人工數據合成法是利用生成人工數據而不是重復原始觀測來解決不平衡性��。它也是一種過采樣技術����。
在這一領域�����,SMOTE法(Synthetic Minority Oversampling Technique)是有效而常用的方法�。該算法基于特征空間(而不是數據空間)生成與小類觀測相似的新數據(譯者注:總體是基于歐氏距離來度量相似性����,在特征空間生成一些人工樣本��,更通俗地說是在樣本點和它近鄰點的連線上隨機投點作為生成的人工樣本��,下文敘述了這一過程但有些晦澀)��。我們也可以說�����,它生成了小類觀測的隨機集合來降低分類器的誤差��。
為了生成人工數據����,我們需要利用自助法(Bootstrapping)和K近鄰法(K-neraest neighbors)����。詳細步驟如下:
計算樣本點間的距離并確定其近鄰����。
生成一個0到1上的均勻隨機數���,并將其乘以距離�����。
把第二步生成的值加到樣本點的特征向量上��。
這一過程等價于在在兩個樣本的連線上隨機選擇了一個點�。
R中有一個包專門用來實現SMOTE過程����,我們將在實踐部分做演示���。
4.代價敏感學習(CSL)
這是另一種常用且有意思的方法��。簡而言之����,該方法會衡量誤分類觀測的代價來解決不平衡問題�。
這方法不會生成平衡的數據集�,而是通過生成代價矩陣來解決不平衡問題���。代價矩陣是描述特定場景下誤分類觀測帶來的損失的工具���。近來已有研究表明��,代價敏感學習法很多時候比采樣法更優����,因此這種方法也值得一學���。
讓我們通過一個例子來了解該方法:給定一個有關行人的數據集��,我們想要了解行人是否會攜帶炸彈����。數據集包含了所有的必要信息�,且攜帶炸彈的人會被標記為正類�,不帶炸彈的就是負類?���,F在問題來了���,我們需要把行人都分好類����。讓我們先來設定下這一問題的代價矩陣�。
如果我們將行人正確分類了�����,我們不會蒙受任何損失�。但如果我們把一個恐怖分子歸為負類(False Negative)���,我們要付出的代價會比把和平分子歸為正類(False Positive)的代價大的多�。
代價矩陣和混淆矩陣類似��,如下所示�����,我們更關心的是偽正類(FP)和偽負類(FN)�����。只要觀測被正確分類�,我們不會有任何代價損失�����。
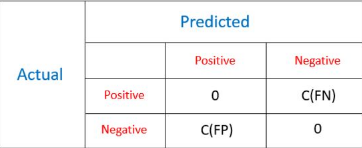
該方法的目標就是找到一個使得總代價最小的分類器
Total Cost = C(FN)xFN + C(FP)xFP
其中,
FN是被誤分類的正類樣本數
FP是被誤分類的負類樣本數
C(FN)和C(FP)分別代表FN和FP帶來的損失����。本例中C(FN) > C(FP)
除此之外�,我們還有其他的比較前沿的方法來處理不平衡樣本�����。比如基于聚類的采樣法(Cluster based sampling)���,自適應人工采樣法(adaptive synthetic sampling)���,邊界線SMOTE(border line SMOTE)���,SMOTEboost�,DataBoost-IM����,核方法等����。這些方法的基本思想和前文介紹的四類方法大同小異���。還有一些更直觀的方法可以幫助你提升預測效果:如利用聚類技術���,把大類分為K個次類����,每個此類的樣本不重疊����。再基于每個次類和小類的合并樣本來訓練分類器��。最后把各個分類結果平均作為預測值���。除此之外���,也可以聚焦于獲取更多數據來提高小類的占比����。
應當使用哪類評價測度來評判精度�����?
選擇合適的評價測度是不平衡數據分析的關鍵步驟�。大部分分類算法僅僅通過正確分類率來衡量精度�����。但在不平衡數據中�����,使用這種方法有很大的欺騙性�,因為小類對于整體精度的影響太小����。
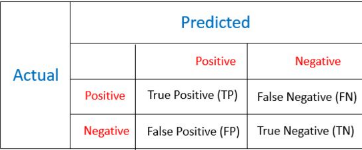
混淆矩陣
混淆矩陣和代價矩陣的差異就在于代價矩陣提供了跟多的誤分類損失信息�����,其對角元素皆為0���。而混淆舉證只提供了TP�����,TN�,FP��,FN四類樣本的比例��,它常用的統計量則為正確率和錯誤率:
Accuracy: (TP + TN)/(TP+TN+FP+FN)
Error Rate = 1 - Accuracy = (FP+FN)/(TP+TN+FP+FN)
如前文所提���,混淆矩陣可能會提供誤導性結果���,并且它對數據變動非常敏感����。更進一步�,我們可以從混淆矩陣衍生出很多統計量��,其中如下測度就提供了關于不平衡數據精度的更好度量:
準確率(Preciosion):正類樣本分類準確性的度量����,即被標記為正類的觀測中被正確分類的比例����。
Precision = TP / (TP + FP)
召回率(Recall):所有實際正類樣本被正確分類的比率����。也被稱作敏感度(Sensitivity)
Recall = TP / (TP + FN)
F測度(F measure):結合準確率和召回率作為分類有效性的測度���。具體公式如下(\(\beta\)常取1):
F measure = ((1 + β)2 × Recall × Precision) / ( β2 × Recall + Precision )
盡管這些測度比正確率和錯誤率更好��,但總的說來對于衡量分類器而言還不夠有效�����。比如���,準確率無法刻畫負類樣本的正確率���。召回率只針對實際正類樣本的分類結果�����。這也就是說��,我們需要尋找更好的測度來評價分類器�����。
謝天謝地����!我們可以通過ROC(Receiver Operationg Characterstics)曲線來衡量分類預測精度�����。這也是目前廣泛使用的評估方法��。ROC曲線是通過繪制TP率(Sensitivity)和FP率(Specificity)的關系得到的�。
Specificity = TN / (TN + FP)
ROC圖上的任意一點都代表了單個分類器在一個給定分布上的表現����。ROC曲線之所以有用是因為它提供了分類數據收益(TP)和損失(FP)的可視化信息�����。ROC曲線下方區域的面積(AUC)越大���,整體分類精度就越高����。
但有時ROC曲線也會失效�,它的不足包括:
對于偏態分布的數據�,可能會高估精度
沒有提供分類表現的置信區間
無法提供不同分類器表現差異的顯著性水平
作為一種替代方法�����,我們也可以選擇別的可視化方式比如PR曲線和代價曲線�。特別地����,代價曲線被認為有以圖形方式描述分類器誤分類代價的能力��。但在90%的場合中�����,ROC曲線已經足夠好�。
在R中進行不平衡數據分類
行文至此�����,我們已經學習了不平衡分類的一些重要理論技術�。是時候來應用它們了�����!在R中����,諸如ROSE包和EMwR包都可以幫助我們快速實現采樣過程�。我們將以一個二分類案例做演示���。
ROSE(Random Over Sampling Examples)包可以幫助我們基于采樣和平滑自助法(smoothed bootstrap)來生成人工樣本����。這個包也提供了一些定義良好的函數來快速完成分類任務�����。
讓我們開始吧
# 設定路徑
path <- "C:/Users/manish/desktop/Data/March 2016"
# 設定工作目錄
setwd(path)
# 安裝包
install.packages("ROSE")
library(ROSE)
ROSE包中內置了一個叫做hacide的不平衡數據集�,它包括hacide.train和hacide.test兩個部分��,讓我們把它讀入R環境:
data(hacide)
str(hacide.train)
'data.frame': 1000 obs. of 3 variables:
$ cls: Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
$ x1 : num 0.2008 0.0166 0.2287 0.1264 0.6008 ...
$ x2 : num 0.678 1.5766 -0.5595 -0.0938 -0.2984 ...
如你所見��,數據集有3個變量的1000個觀測��。cls是響應變量���,x1和x2是解釋變量�。讓我們檢查下cls的不平衡程度:
# 檢查cls的不平衡度
table(hacide.train$cls)
0 1
980 20
# 檢查cls的分布
prop.table(table(hacide.train$cls))
0 1
0.98 0.02
可以看到��,數據集中只有2%的正樣本����,其余98%都屬于負類��。數據的不平衡性極其嚴重���。那么����,這對我們的分類精度會帶來多大影響�����?我們先建立一個簡單的決策樹模型:
library(rpart)
treeimb <- rpart(cls ~ ., data = hacide.train)
pred.treeimb <- predict(treeimb, newdata = hacide.test)
然我們看看這個模型的預測精度��,ROSE包提供了名為accuracy.meas()的函數���,它能用來計算準確率����,召回率和F測度等統計量��。
accuracy.meas(hacide.test$cls, pred.treeimb[,2])
Call:
accuracy.meas(response = hacide.test$cls, predicted = pred.treeimb[, 2])
Examples are labelled as positive when predicted is greater than 0.5
precision: 1.000
recall: 0.200
F: 0.167
這些測度值看上去很有意思���。如果我們設定閾值為0.5�����,準確率等于1說明沒有被誤分為正類的樣本����。召回率等于0.2意味著有很多樣本被誤分為負類��。0.167的F值也說明模型整體精度很低�����。
我們再來看看模型的ROC曲線�����,它會給我們提供這個模型分類能力的直觀評價�����。使用roc.curve()函數可以繪制該曲線:
roc.curve(hacide.test$cls, pred.treeimb[,2], plotit = F)
Area under the curve (AUC): 0.600
AUC值等于0.06是個很槽糕的結果�。因此我們很有必要在建模前將數據集修正平衡��。在本案例中����,決策樹算法對于小類樣本無能為力�。
我們將使用采樣技術來提升預測精度���。這個包提供了ovun.sample()的函數來實現過采樣和欠采樣�。
我們先試試過采樣
# 過采樣
data_balanced_over <- ovun.sample(cls ~ ., data = hacide.train, method = "over",N = 1960)$data
table(data_balanced_over$cls)
0 1
980 980
上述代碼實現了過采樣方法���。N代表最終平衡數據集包含的樣本點�����,本例中我們有980個原始負類樣本��,所以我們要通過過采樣法把正類樣本也補充到980個����,數據集共有1960個觀測����。
與之類似�,我們也能用欠采樣方法��,請牢記欠采樣是無放回的�����。
data_balanced_under <- ovun.sample(cls ~ ., data = hacide.train, method = "under", N = 40, seed = 1)$data
table(data_balanced_under$cls)
0 1
20 20
欠采樣后數據是平衡了����,但由于只剩下了40個樣本����,我們損失了太多信息����。我們還可以同時采取這兩類方法���,只需要把參數改為method = "both"����。這時��,對小類樣本會進行有放回的過采樣而對大類樣本則進行無放回的欠采樣��。
data_balanced_both <- ovun.sample(cls ~ ., data = hacide.train, method = "both", p=0.5, N=1000, seed = 1)$data
table(data_balanced_both$cls)
0 1
520 480
函數的參數p代表新生成數據集中正類的比例����。
但前文已經提過兩類采樣法都有自身的缺陷�,欠采樣會損失信息����,過采樣容易導致過擬合�,因而ROSE包也提供了ROSE()函數來合成人工數據�����,它能提供關于原始數據的更好估計����。
data.rose <- ROSE(cls ~ ., data = hacide.train, seed = 1)$data
table(data.rose$cls)
0 1
520 480
這里生成的數據量和原始數據集相等(1000個觀測)?��,F在�����,我們已經用4種方法平衡了數據����,我們分別建模評評估精度�����。
# 訓練決策樹
tree.rose <- rpart(cls ~ ., data = data.rose)
tree.over <- rpart(cls ~ ., data = data_balanced_over)
tree.under <- rpart(cls ~ ., data = data_balanced_under)
tree.both <- rpart(cls ~ ., data = data_balanced_both)
# 在測試集上做預測
pred.tree.rose <- predict(tree.rose, newdata = hacide.test)
pred.tree.over <- predict(tree.over, newdata = hacide.test)
pred.tree.under <- predict(tree.under, newdata = hacide.test)
pred.tree.both <- predict(tree.both, newdata = hacide.test)
是時候用roc.curve()函數來評估精度了�!
# 人工數據合成AUC值
roc.curve(hacide.test$cls, pred.tree.rose[,2])
Area under the curve (AUC): 0.989
# 過采樣AUC值
roc.curve(hacide.test$cls, pred.tree.over[,2])
Area under the curve (AUC): 0.798
# 欠采樣AUC值
roc.curve(hacide.test$cls, pred.tree.under[,2])
Area under the curve (AUC): 0.867
# 雙采樣AUC值
roc.curve(hacide.test$cls, pred.tree.both[,2])
Area under the curve (AUC): 0.798
下方就是輸出的ROC曲線��,其中:
黑線代表人工數據合成
紅線代表過采樣
綠線代表欠采樣
藍線代表雙采樣
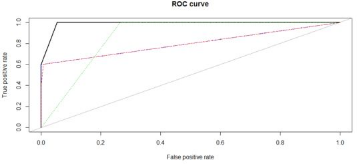
因此�����,我們發現利用人工數據合成法可以帶來最高的預測精度��,它的表現比采樣法要好��。這一技術和更穩健的模型結合(隨機森林���,提升法)可以得到更高的精度��。
這個包為我們提供了一些基于holdout和bagging的模型評估方法�����,這有助于我們判斷預測結果是否有太大的方差����。
ROSE.holdout <- ROSE.eval(cls ~ ., data = hacide.train, learner = rpart, method.assess = "holdout", extr.pred = function(obj)obj[,2], seed = 1)
ROSE.holdout
Call:
ROSE.eval(formula = cls ~ ., data = hacide.train, learner = rpart,
extr.pred = function(obj) obj[, 2], method.assess = "holdout",
seed = 1)
Holdout estimate of auc: 0.985
可以發現預測精度維持在0.98附近�����,這意味著預測結果波動不大����。類似的����,你可以用自助法來評估�,只要把method.asses改為"BOOT"�。extr.pred參數是一個輸出預測結果為正類的列的函數�。
結語
當我們面對不平衡數據集時���,我們常常發現利用采樣法修正的效果不錯���。但在本例中�,人工數據合成比傳統的采樣法更好���。為了得到更好的結果�,你可以使用一些更前沿的方法���,諸如基于boosting 的人工數據合成����。數據分析師培訓
在本文中����,我們討論了關于不平衡數據的一些要點�����。對于R的使用者來說���,由于有很多強大的包的支持����,處理這類問題并非難事���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
