機器學習入門:K-近鄰算法
先來一個簡單的例子�����,我們如何來區分動作類電影與愛情類電影呢�����?動作片中存在很多的打斗鏡頭�,愛情片中可能更多的是親吻鏡頭���,所以我們姑且通過這兩種鏡頭的數量來預測這部電影的主題�����。簡單的說�����, k-近鄰算法 采用了測量不同特征值之間的距離方法進行分類����。
優點:精度高���、對異常值不敏感����、無數據輸入假定 缺點:計算復雜度高�����、控件復雜度高 適用數據范圍:數值型和標稱型
首先我們來理解它的工作原理:
存在一個樣本數據集(訓練集)�,并且我們知道每一數據與目標變量的對應關系����,輸入沒有標簽的新數據后����,將新數據的每個特征與樣本集中數據對應的特征進行比較��,然后算法提取樣本集中最相近的分類標簽����,一般來說�,我們只選擇樣本集中前k個最相似的數據��,通常k為不大于20的整數����,最后���,選擇k個最相似數據中出現次數最多的分類���,作為新數據的分類��。
現在我們回到文章開頭所提到的電影的例子���,根據下表如何確定未知的電影類型呢�����?
電影名稱 打斗鏡頭 接吻鏡頭 電影類型
電影1 3 104 愛情
電影2 2 100 愛情
電影3 1 81 愛情
電影4 101 10 動作
電影5 99 5 動作
電影6 98 2 動作
電影7 18 90 未知�?
該如何計算電影7的電影類型呢�?計算電影7與樣本集中其他電影的距離�����,然后我們假定k=3��,看一下最近的3部電影是什么類型即可預測出電影7的電影類型���。
流程介紹
收集數據
準備數據:距離計算所需要的值���,最好是結構化的數據格式
分析數據
測試算法:計算錯誤率
使用算法
開始工作
使用python導入數據
首先��,創建名為kNN.py的Python模塊�,在構造算法之前�,我們還需要編寫一些通用的函數等����,我們先寫入一些簡單的代碼:
from numpy import *
import operator
def createDataSet():
group = array([
[1.0, 1.1],
[1.0, 1.0],
[0, 0],
[0, 0.1]
])
labels = ["A", "A", "B", "B"]
return group, labels
然后將終端改變到代碼文件目錄����,輸入命令python進入到交互界面:
>>> import kNN
>>> group, labels = kNN.createDataSet()
>>> group
array([[ 1. , 1.1],
[ 1. , 1. ],
[ 0. , 0. ],
[ 0. , 0.1]])
>>> labels
['A', 'A', 'B', 'B']
這里有4組數據����,每組數據有2個我們已知的特征值��,上面的group矩陣每行為一條數據�����,對于每個數據點我們通常使用2個特征(所以特征的選擇很重要)�����,向量labels包含了每個數據點的標簽信息�����,labels的維度等于矩陣的行數�,這里我們將 [1, 1,1] 定為類A��, [0, 0.1] 定為類B�����,接下來我們進行算法的編寫:
計算已知數據集中點到當前點之間的距離
按照距離遞增次序排序
選取與當前點距離最小的k個點
確定前k個點所在類別的出現頻率
返回前k個點中頻次最高的類別作為預測類別
接著定義函數:
# inX: 用于分類的輸入向量
# dataSet:輸入的訓練集
# labels:標簽向量
# k:選擇近鄰項目的個數
def classify0(inX, dataSet, labels, k) :
dataSetSize = dataSet.shape[0]
# 距離計算
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2 # python中, **2 代表2平方����,**0.5代表開方
sqDistances = sqDiffMat.sum(axis=1) # 加入axis=1以后就是將一個矩陣的每一行向量相加
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
# 選擇距離最小的k個點
for i in range(k) :
voteILabel = labels[sortedDistIndicies[i]]
classCount[voteILabel] = classCount.get(voteILabel, 0) + 1
# 排序
sortedClassCount = sorted(classCount.iteritems(), key = operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
然后我們進行測試����,重新打開python編譯環境:
>>> import kNN
>>> group, labels = kNN.createDataSet()
>>> kNN.classify0([0, 0], group, labels, 3)
'B'
>>> kNN.classify0([0.3, 0], group, labels, 3)
'B'
>>> kNN.classify0([0.8, 0.9], group, labels, 3)
'A'
我們看到�,一個簡單的分類器就這樣搞定了����。這時�,我們來將電影數據進行樣本寫入:
def createDataSet():
group = array([
[3, 104],
[2, 100],
[1, 81],
[101, 10],
[99, 5],
[98, 2]
])
labels = ["love", "love", "love", "action", "action", "action"]
return group, labels
>>> import kNN
>>> group, labels = kNN.createDataSet()
>>> kNN.classify0([18, 90], group, labels, 3)
'love'
我們看到預測結果為愛情片��。這是一個簡單的分類器����,當然����,我們應該通過大量的測試��,看預測結果與預期結果是否相同��,進而得出錯誤率�����,完美的分類器錯誤率為0����,最差的錯誤率為1����,上邊電影分類的例子已經可以使用了��,但是貌似沒有太大的作用����,下邊我們來看一個生活中的實例�����,使用k-近鄰算法改進約會網站的效果�,然后使用k-近鄰算法改進手寫識別系統�。
改進約會網站的配對效果
有個姑娘��,一直在使用某交友網站�����,但是推薦來的人總是不盡人意���,她總結了一番��,曾交往過3中類型的人:
不喜歡的人
魅力一般的人
極具魅力的人
她覺得自己可以在周一~周五約會那些魅力一般的人�,周末與那些極具魅力的人約會��,因為她希望我們可以更好的幫助她將匹配的對象劃分到確切的分類中�����,她還收集了一些約會網站未曾記錄過的數據信息��,她認為這些數據信息會有幫助�。這些數據存放在代碼文件夾下 datingTestSet2.txt 中���,總共有1000行數據(妹的約了1000個人)���,主要包含以下特征:
每年獲得的飛行?�?屠锍虜?br />
玩視頻游戲所消耗的時間百分比
每周消費的冰激凌公升數
我們看到�,統計的東西都比較奇葩��,我們先從文件中把這些數值解析出來���,輸出訓練樣本矩陣和分類標簽向量����。在kNN.py中繼續書寫代碼:
從文本中讀入數據
def file2matrix(filename) :
fr = open(filename)
arrayOfLines = fr.readlines()
numberOfLines = len(arrayOfLines) # 得到文件行數
returnMat = zeros((numberOfLines, 3)) # 創建用0填充的矩陣����,這里為了簡化處理��,我們將矩陣的另一個緯度設置為3�,可以按照自己的需求增加數量�����。
classLabelVector = []
index = 0
# 解析文件
for line in arrayOfLines :
line = line.strip() # 截取掉所有的回車字符
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0: 3] # range
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector
>>> import kNN
>>> mat, vector = kNN.file2matrix('datingTestSet2.txt')
>>> mat, vector = kNN.file2matrix('datingTestSet2.txt')
>>> mat
array([[ 4.09200000e+04, 8.32697600e+00, 9.53952000e-01],
[ 1.44880000e+04, 7.15346900e+00, 1.67390400e+00],
[ 2.60520000e+04, 1.44187100e+00, 8.05124000e-01],
...,
[ 2.65750000e+04, 1.06501020e+01, 8.66627000e-01],
[ 4.81110000e+04, 9.13452800e+00, 7.28045000e-01],
[ 4.37570000e+04, 7.88260100e+00, 1.33244600e+00]])
>>> vec
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'vec' is not defined
>>> vector
[3 ... 2]
現在我們已經從文文件中導入了數據����,并將其格式化為想要的格式���,接著我們需要了解數據的真是含義����,我們可以直觀的瀏覽文本文件�����,但是這種方法非常不友好�,一般來說����,我們會采用圖形化的方式直觀的展示數據�。下面我們就用Python圖形化工具來圖形化展示數據內容�,以便辨識出一些數據模式����。
分析數據��,使用 Matplotlib 創建散點圖
pip install matplotlib
接下來打開python命令行�����,我們對剛才讀入的內容進行測試的展示
>>> from matplotlib import *
>>> import matplotlib.pyplot as plt
>>> import kNN
>>> import numpy as np
>>> mat, vec = kNN.file2matrix('datingTestSet2.txt')
>>> fig = plt.figure()
>>> ax = fig.add_subplot(111)
>>> ax.scatter(mat[:, 1], mat[:, 2], 15.0*np.array(vec), 15.0*np.array(vec))
<matplotlib.collections.PathCollection object at 0x1087cf0d0>
>>> plt.show()
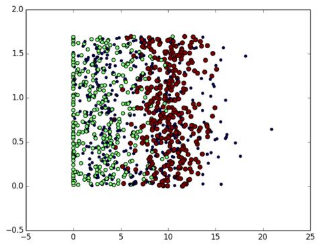
這個時候��,我們展示的是數據集的第一列與第二列所繪制的圖��,這里我們很難看出來什么端倪�����,所以我們嘗試使用第一列和第二列作為特征來繪圖�����,重新書寫上邊代碼:
ax.scatter(mat[:, 0], mat[:, 1], 15.0*np.array(vec), 15.0*np.array(vec))
然后我們得到了以下數據圖:
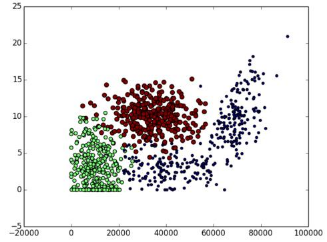
這次���,我們可以看到�,圖中清晰的標識了3個不同的樣本分類區域��。
準備數據���,歸一化數值
我們隨便的抽取了4組差異比較大的數據
玩游戲所消耗時間 里程數 冰激凌公升數 樣本分類
1 0.8 400 0.5 1
2 12 13400 0.9 3
3 0 20000 1.1 2
4 67 32000 0.1 2
我們很容易發現�,如果我們計算樣本3和樣本4之間的距離���,可以使用下邊的方法
$\sqrt{(0-67)^2 + (20000 + 32000)^2 + (1.1-0.1)^2}$
但是這些大的值堆結果的影響比較大��,因此��,作為比較重要的特征屬性����,不應該如此的影響計算結果���,所以在處理數據的時候����,我們對數據進行歸一化處理����,將取值的范圍處理到0 - 1或者-1 ~ -1之間��,下面的公事��,可以將任意范圍內的特征值轉換為0-1區間內的值:
$newValue = (oldValue - min)/(max - min)$
其中���,min和max分別為特征值中最大和最小值�����,雖然改變數值范圍增加了分類器的復雜度����,但是為了得到準確的結果�,必須這樣做����,所以我們在kNN.py中新增一個函數 autoNorm() �����,用來將數字特征值轉化為0-1的區間:
def autoNorm(dataSet) :
minvals = dataSet.min(0) # 存放每列的最小值
maxVals = dataSet.max(0) # 存放每列的最大值
ranges = maxVals - minvals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minvals, (m, 1))
# 特征值相除
normDataSet = normDataSet / tile(ranges, (m, 1))
return normDataSet, ranges, minvals
運行結果:
>>> import kNN
>>> mat, vec = kNN.file2matrix('datingTestSet2.txt')
>>> a, b, c = kNN.autoNorm(mat)
>>> a
array([[ 0.44832535, 0.39805139, 0.56233353],
[ 0.15873259, 0.34195467, 0.98724416],
[ 0.28542943, 0.06892523, 0.47449629],
...,
[ 0.29115949, 0.50910294, 0.51079493],
[ 0.52711097, 0.43665451, 0.4290048 ],
[ 0.47940793, 0.3768091 , 0.78571804]])
這樣一來��,我們把值處理成了我們預期的范偉內的值���。
測試算法
通常我們把數據集的90%的數據當做訓練集�����,余下的10%作為測試集����,著10%的數據是隨機選擇的�����。 下面�����,我們來書寫測試程序�,并通過 datingTestSet.txt 來測試程序:
def datingClassTest() :
hoRatio = 0.10 # 設置抽取多少數據進行測試集
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt') # 讀入數據集
normMat, ranges, minVals = autoNorm(datingDataMat) # 轉化特征值至 0 - 1 區間內
m = normMat.shape[0]
numTestVecs = int( m * hoRatio ) # 計算測試向量的數量
errorCount = 0.0
for i in range(numTestVecs) :
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs: m], 3) # 使用近鄰算法得出結果
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]) : errorCount += 1.0 # 錯誤記錄與處理等
print "the total error rate is: %f" % (errorCount / float(numTestVecs))
然后我們在python環境中通過
reload(kNN)
來重新加載kNN.py模塊����,然后調用
kNN.datingClassTest()
得到結果:
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 1, the real answer is: 1
...
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the classifier came back with: 3, the real answer is: 1
the total error rate is: 0.050000
所以我們看到�,數據集的錯誤率是5%��,這里會有一定的偏差����,因為我們隨機選取的數據可能會不同�。
使用算法
我們使用上面建立好的分類器構建一個可用的系統���,通過輸入這些特征值幫她預測喜歡程度�����。我們來編寫代碼:
def classifyPerson() :
resultList = ['not', 'small doses', 'large does']
percentTats = float(raw_input("percent of time spent on video games?"))
miles = float(raw_input("flier miles per year?"))
ice = float(raw_input("liters of ice-cream?"))
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([miles, percentTats, ice])
classifierResult = classify0((inArr - minVals) / ranges, normMat, datingLabels, 3)
print "you will like this person: ", resultList[classifierResult - 1]
這里的代碼大家比較熟悉了�����,就是加入了raw_input用于輸入�����,我們來看結果:
>>> reload(kNN)
<module 'kNN' from 'kNN.py'>
>>> kNN.classifyPerson()
percent of time spent on video games?10
flier miles per year?10000
liters of ice-cream?0.5
you will like this person: small doses
我們在做近鄰算法的時候也發現�,并沒有做 訓練算法 這一環節�����,因為我們不需要訓練���,直接計算就好了���。
同時我們也發現一個問題��,k-近鄰算法特別慢�,它需要對每一個向量進行距離的計算�,這該怎么優化呢�?
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
