機器學習實戰之PCA
1. 向量及其基變換
1.1 向量內積
(1)兩個維數相同的向量的內積定義如下: 內積運算將兩個向量映射為一個實數.

(2) 內積的幾何意義
假設A\B是兩個n維向量, n維向量可以等價表示為n維空間中的一條從原點發射的有向線段, 為方便理解, 在這里假設A和B都是二維向量.A=(x1,y1) , B=(x2,y2),在二維平面上A/B可以用兩條發自原點的有向線段表示,如下圖:
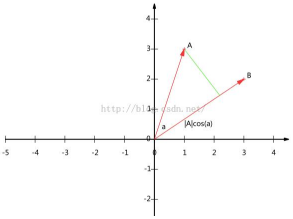
在上圖中,從A點向B所在的直線引一條垂線.垂線與B的交點叫A在B上的投影.A與B的夾角是a,則投影的矢量長度為
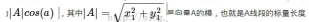
* 矢量長度可能為負,其絕對值是線段長度. 符號取決于其方向與標準方向相同或相反. 標量長度總是大于等于0,值就是線段的長度.
內積另外一種表示形式:
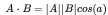
A和B的內積等于A到B的投影長度乘以B的模.設向量B的模為1的話,則A和B的內積值等于A向B所在直線投影的矢量長度.
1.2 基
(1) 一個二維向量對應二維直角坐標系中從原點出發的一個有向線段, 代數方面, 常使用線段終點的點坐標表示向量, 例如(3,2), 但是一個(3,2)并不能精確的表示一個向量,. 分析可得: "3"實際表示的是向量在x軸上的投影值是3,在y軸的投影值是2, 也就是隱式的引入了一個定義: 以x軸和y軸正方向長度為1的向量為標準. 更具體地,向量(x,y)實際可以表示線性組合: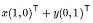 . 此處(1,0)/(0,1)為二維空間中的一組基.
. 此處(1,0)/(0,1)為二維空間中的一組基.
結論: 為了準確描述向量,首先確定一組基,然后給出在基所在的各個直線上的投影值即可.
(2) 任何兩個線性無關的二維向量都可以成為一組基.一般假設基的模為1, 例如一組基為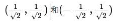 ,則點(3,2)在新基上的坐標為
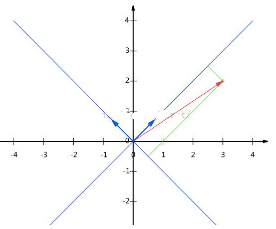
,則點(3,2)在新基上的坐標為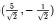 ,形象的從下圖中可以觀察:
,形象的從下圖中可以觀察:
(3) 基變換的矩陣表示
第二節中的例子轉為矩陣表示為:
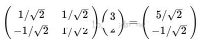
矩陣的兩行分別為兩個基.乘以原向量恰好是新坐標; 若是有多個二維向量要轉換到新基下的坐標,即將這些二維向量按列排成一個矩陣,例如點(1,1)/(2,2)/(3,3)

*結論: 如果有m個n維向量,想將其變換為r個n維空間表示的新空間中,首先將r個基按行組成矩陣A,然后將向量按列組成矩陣B, 那么兩矩陣的乘積AB就是變換結果,其中AB的第m列為B中第m列的變換結果. r決定了變換后數據的維數.即可以將一n維數據變換到更低維的空間中去,變換后的維數取決于基的數量.
兩個矩陣相乘的意義就是將右邊矩陣中的每一列列向量轉換到左邊每一行行向量為基表示的空間中去.
2. 協方差矩陣
2.1 基礎準備
前面討論了不同的基可以對同一組數據給出不同的表示,如果基的數量少于向量自身的維數, 則可以達到降維的目標. 如何選擇k個n維向量(k個基)使得最大程度上保留原有的信息?
下面舉例說明:
數據的5條記錄組成, 將它們表示成矩陣形式:

其中每一列為一條數據記錄,一行對應一個字段,為了處理方便,首先將每個字段內所有值減去字段均值,其結果就是將每個字段的均值都變為0,上述矩陣變換后的結果為:
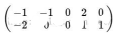
其在坐標系中對應的位置為:
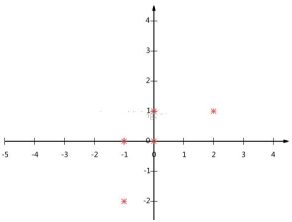
問題: 現在要用一維來表示這些數據,又希望盡可能的保留原始的信息,該怎么選擇基?
答案: 希望投影后的投影值盡可能分散.
上述圖所將數據點向第一象限和第三象限的斜線投影,則上述5個點在投影后還是可以區分的.
2.2. 方差
希望投影后得到的數據值盡可能分散, 分散程度可以用數學上的方差來表述.
一個字段的方差可以看作是每個元素與字段均值差的平方和的均值,即
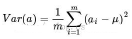
由于上面已將數據的每個字段平均化了,因此方差可以直接用每個元素的平方和除以元素個數,即

于是上述問題被形式化表示為:尋找一個基,使得所有數據變換為這個基上的坐標后,方差最大.
2.3 協方差
對于將二維變為一維的問題,找到使得方差最大的方向即可; 但是對于更高維,需要考慮更多,例如三維降到二維, 與之前相同,首先希望找到一個方向使得投影后方差最大,這樣就完成了地一個方向的選擇,繼續我們還需要選擇第二個投影方向.
若繼續選擇方差最大的方向,則這個方向和第一個方向應該是幾乎重合的, 顯然這樣是不行的,. 從直觀上看,為了讓這兩個字段盡可能的表示更多的原始信息,希望它們之間是線性不相關的,因為相關性意味這兩個字段不是完全獨立,存在重復表示的信息.
數學上用兩個字段的協方差來表示其相關性,由于已經讓每個字段的均值為0,則其協方差計算公式如下:
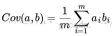
由式子可以得出, 在字段均值為0的情況下, 兩個字段的協方差簡潔的表示為其內積除以元素數.
當協方差為0時, 表示兩個字段完全獨立. 為了讓協方差為0, 選擇第二個基只能在與第一個基正交的方向上選擇.因此最終選擇的兩個方向一定是正交的.
***降維的優化目標: 將一組n維向量降為k維,其目標是選擇k個單位(模為1)正交基,使得原始數據變換到這組基上后, 個字段兩兩間協方差為0,且字段的方差盡可能大(在正交的約束下,取最大的k個方差)
2.4 協方差矩陣
最終目的與字段內方差和字段間的協方差密切相關,現在想做的就是使得兩者統一.
假設我們有a和b兩個字段,m個向量,將其按行組成矩陣X:
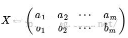
然后用X乘以X的轉置,并除以向量個數:
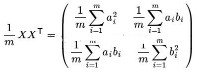
可以發現,這個矩陣對角線上的兩個元素分別是來那個個字段的方差,而其它元素是a和b的協方差.即方差和協方差被統一到了一個矩陣中.
***推廣得到一般結論: 若有m個n維數據,將其按列拍成n*m的矩陣X, ,則C是一個對稱矩陣,其對角線分別是各個字段對應的方差,第i行j列與第j行i列的元素一樣,表示i和j兩個字段的協方差.
,則C是一個對稱矩陣,其對角線分別是各個字段對應的方差,第i行j列與第j行i列的元素一樣,表示i和j兩個字段的協方差.
2.5 協方差矩陣對角化
為了達到使得字段內方差盡可能大,字段間的協方差為0的目標, 等于將協方差矩陣對角化:即除對角線外的其它元素均為0,并且對角線上的元素按從大到小的順序排列,這樣就達到了優化目的.
令原始數據矩陣X對應的協方差矩陣為C,P是一組基按行組成的矩陣,Y=PX,則Y為X對P做基變換后的數據.設Y的協方差矩陣為D,推導D與C的關系:

顯然, 變換后的矩陣Y的協方差矩陣D應該除對角線外的元素為0.我們尋找的P是能讓原始協方差矩陣對角化的P.
即優化目標變為:尋找一個矩陣P, 滿足 是一個對角矩陣,且對角元素按從大到小依次排列,那么P的前k行就是尋找的基,用P的前k行組成的矩陣乘以C就使得X從n維降到了k維并滿足上述優化條件.
是一個對角矩陣,且對角元素按從大到小依次排列,那么P的前k行就是尋找的基,用P的前k行組成的矩陣乘以C就使得X從n維降到了k維并滿足上述優化條件.
2.6 協方差對角化
協方差矩陣C是一個對稱矩陣,實對稱矩陣有很好的性質:

3. 降維方法
3.1 降維目的:
使得數據集更易使用
降低很多算法的計算開銷
去除噪聲
使得結果易懂
3.2 三種降維方法
(1) 主成分分析法 (principal component analysis, PCA)
在PCA中,數據從原來的坐標系轉換到了新的坐標系,新坐標系的選擇由數據本身決定. 第一個新坐標軸選擇的是原始數據中方差最大的方向,第二個新坐標軸的選擇是和第一個新坐標軸正交且具有最大方差的方向.過程一直重復,重復次數為原始數據中特征的數目.
(2) 因子分析(factor analysis)
在因子分析中,假設在觀察數據的生成中有一些觀察不到的隱變量.假設觀察數據是這些隱變量和某些噪聲的線性組合.
(3) 獨立成分分析(independent component analysis,ICA)
在ICA中, 假設數據是從N個數據源生成的.即數據為多個數據源的混合觀察結果,這些數據源之間在統計上是相互獨立的,在PCA中只假設數據是不相關的.同因子分析一樣,若數據源的數目小于觀察數據的數目,就可以實現降維.
4. PCA(principal component analysis,主成分分析)
4.1 性能評價
優點: 降低數據的復雜性,識別到最重要的幾個特征
缺點:不一定需要,且可能損失有用信息
4.2 PCA實現
將數據轉換成前N個主成分的偽代碼如下:
去除平均值(將數據的每一維特征減去其平均值)
計算由數據構成矩陣的協方差矩陣
計算協方差矩陣的特征值和特征向量
將特征值從大到小排序
保留最上面的N個特征向量
將數據轉換到上述N個特征向量構建的新空間中
其實現代碼如下:
<span style="font-size:18px;"><span style="font-size:18px;">def pca(dataMat,topNfeat = 999999):
#每一行對應一個數據點,求每一列的平均值(即每個特征的均值)
meanVal = mean(dataMat,axis = 0)
#數據均值化
meanData = dataMat - meanVal
#求數據的協方差矩陣
covMat = cov(meanData,rowvar = 0)
#協方差矩陣的特征向量和特征值
eigVal,eigVec = linalg.eig(mat(covMat))
eigValIndex = argsort(eigVal)
eigValIndex = eigValIndex[:-(topNfeat+1):-1]
redEigVec = eigVec[:,eigValIndex]
#得到降維后的數據
lowDataMat = meanData * redEigVec
#原始數據被重構后返回用于調試
reconMat = (lowDataMat * redEigVec.T) + meanVal
return lowDataMat,reconMat</span></span>
4.3 重構
還原原始數據的過程就是獲得樣本點映射以后在原空間中的估計位置的過程.
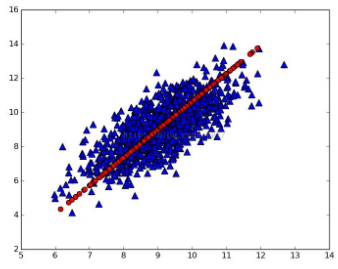
檢驗:在命令行輸入以下代碼:將降維后的數據和原始數據一起畫出來.得到圖片如下:
<span style="font-size:18px;">>>> lowdata,recon = pca.pca(datas,1)
[[ 1.]]
>>> import matplotlib.pyplot as plt
>>> fig = plt.figure()
>>> ax = fig.add_subplot(111)
>>> ax.scatter(datas[:,0].flatten().A[0],datas[:,1].flatten().A[0],marker='^',s=90)
<matplotlib.collections.PathCollection object at 0x7f8b84d70590>
>>> ax.scatter(recon[:,0].flatten().A[0],recon[:,1].flatten().A[0],marker='o',s=50,c='red')
<matplotlib.collections.PathCollection object at 0x7f8b84d40290>
>>> plt.show()
</span>
 c
c
即紅色的線表示原始數據沿著這條線投影.即第一新坐標軸.
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
