數據挖掘十大算法之決策樹詳解(2)
ID3算法
ID3和C4.5都是由澳大利亞計算機科學家Ross Quinlan開發的決策樹構建算法���,其中C4.5是在ID3上發展而來的���。
ID3算法的核心是在決策樹各個結點上應用信息增益準則選擇特征�����,遞歸地構建決策樹���。具體方法是:從根結點(root node)開始�,對結點計算所有可能的特征的信息增益��,選擇信息增益最大的特征作為結點的特征��,由該特征的不同取值建立子結點�����;再對子結點遞歸地調用以上方法�,構建決策樹���;直到所有特征的信息增益均很小或沒有特征可以選擇為止�����。最后得到一棵決策樹�。ID3相當于用極大似然法進行概率模型的選擇���。 下面我們給出一個更加正式的ID3算法的描述:
輸入:訓練數據集D�,特征集A���,閾值?����;
輸出:決策樹T����。
若D中所有實例屬于同一類Ck����,則T為單結點樹�,并將類Ck作為該結點的類標記����,返回T����;
若A=?�����,則T為單結點樹���,并將D中實例數最大的類Ck作為該結點的類標記����,返回T;
否則���,計算A中各特征對D的信息增益�,選擇信息增益最大的特征Ag�;
(1) 如果Ag的信息增益小于閾值?���,則置T為單結點樹�����,并將D中實例數最大的類Ck作為該結點的類標記����,返回T����;
(2) 否則��,對Ag的每一可能值ai���,依Ag=ai將D分割為若干非空子集Di���,將Di中實例數最大的類作為標記���,構建子結點����,由結點及其子結點構成樹T�����,返回T�����;
對第i個子結點�,以Di為訓練集�����,以A?{Ag}為特征集����,遞歸地調用步驟(1)~(3)����,得到子樹Ti�����,返回Ti�。
下面我們來看一個具體的例子�����,我們的任務是根據天氣情況計劃是否要外出打球:
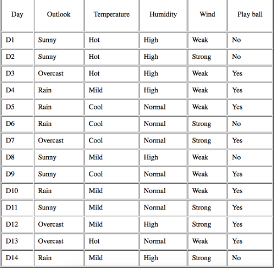
首先來算一下根節點的熵:
然后再分別計算每一種劃分的信息熵�,比方說我們選擇Outlook這個特征來做劃分�,那么得到的信息熵為
據此可計算采用Outlook這個特征來做劃分時的信息增益為
G(PlayBall,Outlook)=E(PlayBall)?E(PlayBall,Outlook)=0.94?0.693=0.247
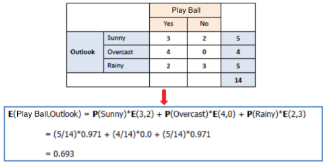
同理�,選用其他劃分時所得到之信息增益如下:
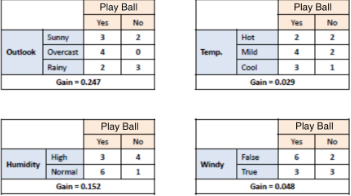
取其中具有最大信息增益的特征來作為劃分的標準�,然后你會發現其中一個分支的熵為零(時間中閾值可以設定來懲罰過擬合)��,所以把它變成葉子�,即得
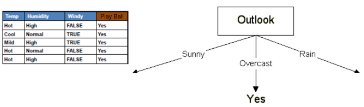
對于其他熵不為零(或者大于預先設定的閾值)的分支����,那么則需要做進一步的劃分
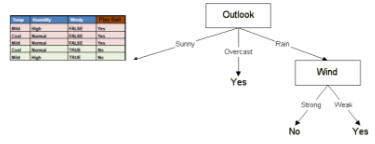
根據上述的規則繼續遞歸地執行下去���。最終�����,我們得到了如下一棵決策樹�。
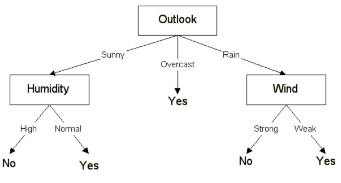
C4.5算法
C4.5是2006年國際數據挖掘大會票選出來的十大數據挖掘算法之首����,可見它應該是非常powerful的��!不僅如此�,事實上���,C4.5的執行也相當的straightforward����。
C4.5算法與ID3算法相似�,C4.5算法是由ID3算法演進而來的���。C4.5在生成的過程中���,用信息增益比來選擇特征�。下面我們給出一個更加正式的C4.5算法的描述:
輸入:訓練數據集D�����,特征集A���,閾值?�����;
輸出:決策樹T����。
如果D中所有實例屬于同一類Ck�����,則置T為單結點樹��,并將Ck作為該結點的類�,返回T��;
如果A=?�����,則置T為單結點樹�����,并將D中實例數最大的類Ck作為該結點的類���,返回T�;
否則���,計算A中各特征對D的信息增益比�����,選擇信息增益比最大的特征Ag��;
(1) 如果Ag的信息增益比小于閾值?���,則置T為單結點樹����,并將D中實例數最大的類Ck作為該結點的類�����,返回T����;
(2) 否則��,對Ag的每一可能值ai��,依Ag=ai將D分割為若干非空子集Di����,將Di中實例數最大的類作為標記���,構建子結點�����,由結點及其子結點構成樹T�,返回T�;
對結點i���,以Di為訓練集�,以A?{Ag}為特征集�,遞歸地調用步驟(1)~(3)�����,得到子樹Ti��,返回Ti����。
How to do it in practice?
易見����,C4.5跟ID3的執行步驟非常類似��,只是在劃分時所采用的準則不同��。我們這里不再贅述����。但是這里可以來看看在實際的數據分析中�,該如何操作�。我們所使用的數據是如下所示的一個csv文件��,文件內容同本文最初給出的Play Ball例子中的數據是完全一致的���。

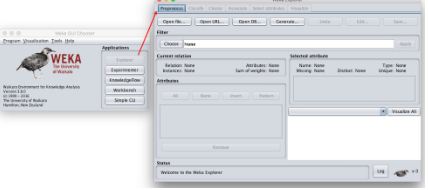
使用Weka進行數據挖掘是非常容易的��,你不再需要像R語言或者MATLAB那樣編寫代碼或者調用函數�����?����;贕UI界面�,在Weka中你只需要點點鼠標即可�!首先我們單擊“Explorer”按鈕來打開操作的主界面�,如下圖所示��。
然后我們單擊“Open File…”�,并從相應的目錄下選擇你要用來進行模型訓練的數據文件�����,如下圖所示����。
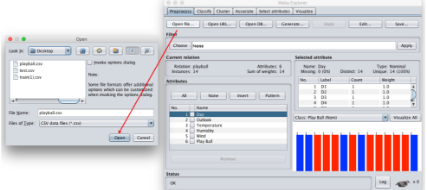
Weka提供了非常易于操作的各種數據預處理功能����,你可以自己嘗試探索一下����。注意到屬性Day其實在構建決策樹時是不需要的����,我選中該屬性���,并將其移除����,如下圖所示����。
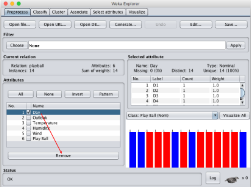
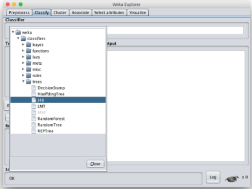
完成數據預處理后��,我們就可以開始進行模型訓練了�����。因為我們是要建立決策樹����,所以選擇“Classify”選項卡����,然后在“Classifier”中選擇J48�。你可以能會疑惑我們不是要使用C4.5算法建立決策樹嗎���?為什么要選擇J48呢�?其實J48是一個開源的C4.5的Java實現版本(J48 is an open source Java implementation of the C4.5 algorithm)���,所以J48就是C4.5��。 數據分析師培訓
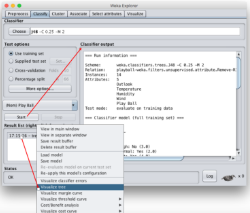
然后你可以自定義的選擇“Test options”中的一些測試選項�����,這里我們不做過多說明����。然后單擊“Start”按鈕��,Weka就為我們建立了一棵決策樹��,你可以從“Classifier output”欄目中看到模型訓練的一些結果����。但是對于決策樹而言����,你可以覺得文字看起來還不夠直觀����。不要緊���,Weka還為你提供了可視化的決策樹建模呈現����。為此���,你需要右鍵單擊剛剛訓練好的模型�����,然后從右鍵菜單中選擇“Visualize tree”�����,如下圖所示��。
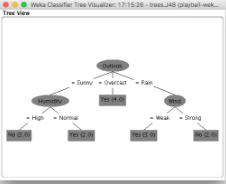
最后我們得到了一棵與前面例子中相一致的決策樹���,如下圖所示��。
在后續的決策樹系列文章中��,我們將繼續深入探討CART算法等相關話題����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;

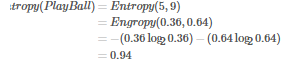










 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
