機器學習中的隱馬爾科夫模型(HMM)詳解
在之前介紹貝葉斯網絡的博文中����,我們已經討論過概率圖模型(PGM)的概念了����。Russell等在文獻【1】中指出:“在統計學中����,圖模型這個術語指包含貝葉斯網絡在內的比較寬泛的一類數據結構���?���!?維基百科中更準確地給出了PGM的定義:“A graphical model or probabilistic graphical model is a probabilistic model for which a graph expresses the conditional dependence structure between random variables. ” 如果你已經掌握了貝葉斯網絡�����,那么你一定不會對PGM的概念感到陌生�����。本文將要向你介紹另外一種類型的PGM����,即隱馬爾可夫模型(HMM���,Hidden Markov Model)�����。更準確地說���,HMM是一種特殊的貝葉斯網絡�。
一些必備的數學知識
隨機過程(Stochastic Process)是一連串隨機事件動態關系的定量描述��。如果用更為嚴謹的數學語言來描述����,則有:設對每一個 t∈T��,X(t,w) 是一個隨機變量�����,稱隨機變量族 XT={X(t,w),t∈T} 為一隨機過程(或隨機函數)���,其中 T∈R 稱為指標集�,R 是實數集����。w∈Ω��,Ω為樣本空間�����。用映射來表示XT����,
X(t,w):T×Ω→R
即 X(?,?) 是定義在 T×Ω 上的二元單值函數�。其中 T×Ω 表示 T 和 Ω 的笛卡爾積�����。
參數 t∈T 一般表示時間�。當 T 取可列集時�,通常稱 XT 為隨機序列�����。XT (t∈T) 可能取值的全體集合稱為狀態空間�,狀態空間中的元素稱為狀態����。
馬爾科夫過程(Markov Process)是本文中我們所要關注的一種隨機過程�。粗略地說��,一個隨機過程�,若已知現在的 t狀態 Xt, 那么將來狀態 Xu (u>t) 取值(或取某些狀態)的概率與過去的狀態 Xs (s>t) 取值無關�;或者更簡單地說�����,已知現在�、將來與過去無關(條件獨立)���,則稱此過程為馬爾科夫過程����。
同樣����,我們給出一個精確的數學定義如下:若隨機過程{Xt,t∈T}對任意 t1<t2<…<tn<t��,xi�,1≤i≤n 及 A 是 R的子集�����,總有
則稱此過程為馬爾科夫過程���。稱P(s,x;t,A)=P{Xt∈A|Xs=x}�����,s>t, 為轉移概率函數��。Xt 的全體取值構成集合 S 就是狀態空間��。對于馬爾可夫過程 XT={Xt,t∈T}�,當S={1,2,3,?}為可列無限集或有限集時�����,通常稱為馬爾科夫鏈(Markov Chain)��。
從時間角度考慮不確定性
在前面給出的貝葉斯網絡例子中��,每一個隨機變量都有唯一的一個固定取值�。當我們觀察到一個結果或狀態時(例如Mary給你打電話)�,我們的任務是據此推斷此時發生地震的概率有多大����。而在此過程中�����,Mary是否給你打過電話這個狀態并不會改變���,而地震是否已經發生也不會改變����。這就說明��,我們其實是在一個靜態的世界中來進行推理的��。
但是我們現在要研究的HMM��,其本質則是基于一種動態的情況來進行推理���,或者說是根據歷史來進行推理�。假設要為一個高血壓病人提供治療方案���,醫生每天為他量一次血壓��,并根據這個血壓的測量值調配用藥的劑量�。顯然����,一個人當前的血壓情況是跟他過去一段時間里的身體情況�、治療方案���,飲食起居等多種因素息息相關的����,而當前的血壓測量值相等于是對他當時身體情況的一個“估計”���,而醫生當天開具的處方應該是基于當前血壓測量值及過往一段時間里病人的多種情況綜合考慮后的結果�����。為了根據歷史情況評價當前狀態�����,并且預測治療方案的結果�����,我們就必須對這些動態因素建立數學模型�。
而隱馬爾科夫模型就是解決這類問題時最常用的一種數學模型��,簡單來說����,HMM是用單一離散隨機變量描述過程狀態的時序概率模型�����。HMM的基本模型可用下圖來表示��,其中涂有陰影的圓圈 yt?2,yt?1,yt 相當于是觀測變量�����,空白圓圈 xt?2,xt?1,xt 相當于是隱變量����?����;氐絼倓偺峒暗母哐獕褐委煹睦?����,你所觀測到的狀態(例如血壓計的讀數)相當于是對其真實狀態(即病人的身體情況)的一種估計(因為觀測的過程中必然存在噪聲)����,用數學語言來表述就是P(yt|xt)��,這就是模型中的測量模型或測量概率(Measurement Probability)�。另外一方面�����,當前的(真實)狀態(即病人的實際身體狀況)應該與其上一個觀測狀態相關�,即存在這樣的一個分布P(xt|xt?1)�����,這就是模型中的轉移模型或轉移概率(Transition Probability)��。當然����,HMM中隱變量必須都是離散的��,觀測變量并無特殊要求����。
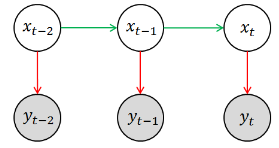
注意這里我們其實使用了馬爾科夫假設:即當前狀態只依賴于過去的有限的已出現的歷史����。我們前面所采用的描述是:“已知現在的 t 狀態 Xt, 那么將來狀態 Xu(u>t) 取值(或取某些狀態)的概率與過去的狀態 Xs(s>t) 取值無關”����。兩種表述略有差異���,但顯然本質上是一致的���。而且更準確的說���,在HMM中�����,我們認為當前狀態緊跟上一個時刻的狀態有關��,即前面所謂的“有限的已出現的歷史”就是指上一個狀態����。用數學語言來表述就是
如果讀者已經閱讀過本文最開始列出的兩篇文章���,那么你應該已經意識到���,這其實是PGM三種基本的結構單元中的最后一種情況��,即條件獨立型的結構單元���。
再結合HMM的基本圖模型(即上圖)��,我們就會得出HMM模型中的兩個重要概率的表達式:
離散的轉移概率(Transition Probability)“
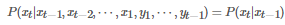
連續(或離散)的測量概率(Measurement Probability)
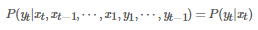
一個簡單的例子
現在我們已經了解了HMM的基本結構�����,接下來不妨通過一個實際的例子來考察一下��,HMM的轉移概率和測量概率到底是什么樣的���。下圖給出了一個用于表示股市動態的概率圖模型�,更具體的說這是一個馬爾科夫模型(Markov Model)��,因為該圖并未涉及隱狀態信息��。根據之前(以貝葉斯網絡為例的)PGM學習��,讀者應該可以看懂改圖所要展示的信息�。例如�,標記為 1 的圓圈表示的是當前股市正處于牛市���,由此出發引出一條指向自身�����,權值為0.6的箭頭�,這表示股市(下一時刻)繼續為牛市的概率為0.6���;由標記為 1 的圓圈引出的一條指向標記為 2 的圓圈的箭頭�,其權值為0.2�����,這表示股市(下一時刻)轉入熊市的概率是0.2����;最后����,由標記為 1 的圓圈引出的一條指向標記為 3 的圓圈的箭頭�����,其權值為0.2��,這表示股市(下一時刻)保持不變的概率是0.2�。顯然����,從同一狀態引出的所有概率之和必須等于1�。
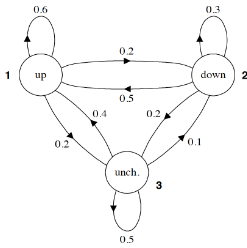
所以馬爾科夫模型中的各個箭頭代表的就是狀態之間相互轉化的概率��。而且�����,通常我們會把馬爾科夫模型中所有的轉移概率寫成一個矩陣的形式��,例如針對本題而已���,則有

如果馬爾科夫模型中有 k 個狀態�����,那么對應的狀態轉移矩陣的大小就是 k×k��。其中第 m 行��,第 n 列所給出的值就是 P(xt=n|xt?1=m)����。也就給定狀態 m 的情況下���,下一時刻轉換到狀態 n 的概率��。例如���,第2行����,第1列的值為 0.5�,它的意思就是如果當前狀態是標記為 2 的圓圈(熊市)�����,那么下一時刻轉向標記為 1 的圓圈(牛市)的概率是 0.5���。而且�����,矩陣中�����,每一行的所有值之和必須等于1���。
至此���,我們已經知道可以用一個矩陣 A 來代表 P(xt|xt?1)��,那又該如何表示 P(yt|xt) 呢�?當然��,由于P(yt|xt) 可能是連續的�,也可能是離散的�����,所以不能一言以蔽之��。為了簡化��,我們當前先僅考慮離散的情況����。當引入 P(yt|xt) 之后���,我們才真正得到了一個隱馬爾科夫模型�,上面我們所說的標記為1��、2 和 3 的(分別代表牛市����、熊市和平穩)三個狀態現在就變成了隱狀態����。當隱狀態給定后�,股市的表現可能有 l=3 種情況�,即當前股市只能處于“上漲”����,“下跌”�����,或者“不變”三種狀態之一����。完整的HMM如下圖所示�。
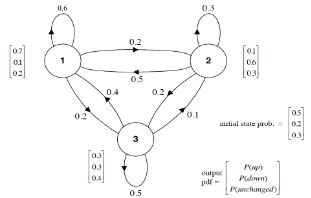
易知���,(當測量概率是離散的情況下)����,HMM中的P(yt|xt) 也可以用一個矩陣 B 來表示����。并且B 的大小是 k×l���。對于當前這個例子而言�,我們有

其中第 1 行��,第 1 列���,就表示 P(yt=1 | xt=1) ���,也就是我們已知當前正處于牛市��,股票上升的概率為0.7��; 同理��,第 1 行���,第 2 列�����,就表示 P(yt=2 | xt=1) �,也就是我們已知當前正處于牛市�����,股票下跌的概率為0.1����。
再次強調�����,只有當測量概率是離散的情況下�,我們才能用一個矩陣來表示P(yt|xt) �。對于連續的情況��,比如我們認為觀測變量的取值符合高斯分布���,也即是概率 P(yt|xt) 的分布符合高斯分布�����,那么應該有多少個高斯分布呢���?顯然有多少個隱狀態(例如 k 個)��,就應該有多少個高斯分布�。那么矩陣 B 就應該變成了由 k 個高斯分布的參數����,即 σ1,μ1,σ2,μ2,?,σk,μk��,組成的一個集合�。
之前的文章里我們談過�����,人類學習的任務是從資料中獲得知識���,而機器學習的任務是讓計算機從數據中獲得模型���。那模型又是什么呢�?回想一下機器學習中比較基礎的線性回歸模型 y=∑iwixi����,我們最終是希望計算機能夠從已有的數據中或者一組最合適的參數 wi����,因為一旦 wi 被確定����,那么線性回歸的模型也就確定了�����。同樣��,面對HMM�,我們最終的目的也是要獲得能夠用來確定(數學)模型的各個參數�。通過前面的討論�,我們也知道了定義一個HMM�����,應該包括矩陣 A和 矩陣 B (如果測量概率是離散情況的話)�,那只有這些參數能夠足以定義個HMM呢�����?
要回答這個問題��,我們不妨來思考一下這樣一個問題��。假如我們現在已經得到了 矩陣 A 和 矩陣 B ��,那么我們能否求出下面這個序列的概率 P(y1=上漲,y2=上漲,y3=下跌)�����。注意對于這樣一個序列�,我們并不知道隱狀態的情況��,所以采用貝葉斯網絡中曾經用過的方法�,設法把隱狀態加進去���,在通過積分的方法將未知的隱狀態積分積掉�����。于是有

這里就可以運用馬爾科夫假設進行簡化���,所以上式就變成了
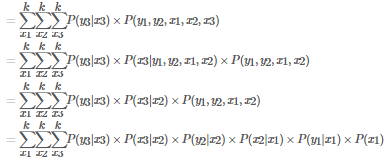
到這里�����,我們就很容易發現�����,上面這個式子中�����,還有一個未知量�����,那就是PGM的初始狀態����,我們將其記為 π �。
于是我們知道���,要確定一個HMM模型��,我們需要知道三個參數����,我們將其記作 λ(A, B, π)����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;

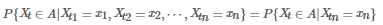
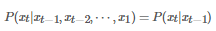










 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
