從樸素貝葉斯分類器到貝葉斯網絡(下)
三����、貝葉斯網絡
貝葉斯網絡(Bayesian Network)是一種用于表示變量間依賴關系的數據結構��,有時它又被稱為信念網絡(Belief Network)或概率網絡(Probability Network)����。在統計學習領域��,概率圖模型(PGM����,Probabilistic Graphical Models)常用來指代包括貝葉斯網絡在內的更加寬泛的一類機器學習模型�,例如隱馬爾可夫模型(HMM���,Hidden Markov Model)也是一種PGM��。
具體而言��,貝葉斯網絡是一個有向無環圖(Directed Acyclic Graph)�,其中每個節點都標注了定量的概率信息�,并具有如下結構特點:
(1)一個隨機變量集構成了圖結構中的節點集合�����。變量可以是離散的���,也可以是連續的��。
(2)一個連接節點對的有向邊集合反映了變量間的依賴關系���。如果存在從節點X指向節點Y的有向邊�����,則稱X是Y的一個父節點���。
(3)每個節點Xi都有一個(在給定父節點情況下的)條件概率分布����,這個分布量化了父節點對其之影響��。
在一個正確構造的網絡中�����,箭頭顯式地表示了X對Y的直接影響��。而這種影響關系往往來自于現實世界的經驗分析�����。一旦設計好貝葉斯網絡的拓撲結構����,只要再為每個節點指定當給定具體父節點時的條件概率���,那么一個基本的概率圖模型就建立完成了�����。盡管現實中貝葉斯網絡的結構可能非常復雜���,但無論多么復雜的拓撲本質上都是由一些基本的結構單元經過一定之組合演繹出來的����。而且最終的拓撲和對應的條件概率完全可以給出所有變量的聯合分布����,這種表現方式遠比列出所有的聯合概率分布要精簡得多�。圖1給出了三種基本的結構單元���,下面我們將分別對它們進行介紹����。
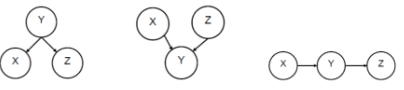
圖1 三種基本的結構單元
首先�,如果幾個隨機變量之間是完全獨立的�����,那么它們之間將沒有任何的邊進行連接����。而對于樸素貝葉斯中的假設��,即變量之間是條件獨立(Conditionally Independent)的����,那么可以畫出此種結構如圖1中的左圖所示����。這表明在給定Y的情況下����,X和Z是條件獨立的�。
其次��,另外一種與之相反的情況如圖1中的中圖所示��。此時X和Z是完全獨立的��。我們通常把左圖的情況稱為“Common Cause”�,而把中圖的情況稱為“Common Effect”����。
最后�,對于圖1中右圖所示的鏈式結構�����,X和Z不再是相互獨立的�。但在給定Y時����,X和Z就是獨立的�。因為P(Z|X,Y)=P(Z|Y)�����。
文獻[1]中給出了一個簡單的貝葉斯網絡示例���,如圖2所示�。假設你在家里安裝了一個防盜報警器�。這個報警器對于探測盜賊的闖入非?�?煽?����,但是偶爾也會對輕微的地震有所反應��。你還有兩個鄰居John和Mary�����,他們保證在你工作時如果聽到警報聲就給你打電話����。John聽到警報聲時總是會給你打電話���,但是他們有時候會把電話鈴聲當成警報聲�,然后也會打電話給你���。另一方面�����,Mary特別喜歡大聲聽音樂�����,因此有時候根本聽不見警報聲���。給定了他們是否給你打電話的證據�,我們希望估計如果有人入室行竊的概率�����。
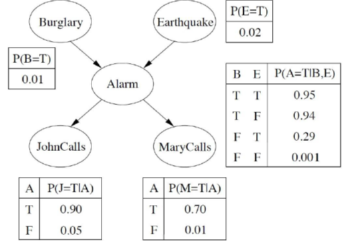
圖2 貝葉斯網絡示例
現在暫時忽略圖中的條件概率分布��,而是將注意力集中于網絡的拓撲結構上��。在這個防盜網絡的案例中����,拓撲結構表明盜賊和地震直接影響到警報的概率(這相當于一個Common Effect的結構)��,但是John或者Mary是否打電話僅僅取決于警報聲(這相當于一個Common Cause的結構)�。因此網絡表示出了我們的一些假設:“John和Mary不直接感知盜賊�����,也不會注意到輕微的地震”(這表明當給定隨機變量Alarm時���,“盜賊或地震”都獨立于“打電話”)��,并且他們不會在打電話之前交換意見(所以在給定隨機變量Alarm時��,John打電話和Mary打電話就是條件獨立的)��。
注意網絡中沒有對應于Mary當前正在大聲聽音樂或者電話鈴聲響起來使得John誤以為是警報的節點�����。這些因素實際上已經被概括在與從Alarm到JohnCalls或者到MaryCalls這兩條邊相關聯的不確定性中了�����。這同時體現了操作中的惰性與無知:要搞清楚為什么那些因素會以或多或少的可能性出現在任何特殊情況下�����,需要大量的工作���,而且無論如何我們都沒有合理的途徑來獲取相關信息����。上面的概率實際上概括了各種情況的潛在無限集合�����,其中包括報警器可能會失效的情況(諸如環境濕度過高��、電力故障�、電線被切斷����、警鈴里卡了一只死老鼠等等)或者John和Mary沒有打電話報告的情況(諸如出去吃午飯了��、外出度假��、暫時性失聰����、直升機剛巧飛過而噪聲隆隆等)�。如此一來�,一個小小的智能體可以處理非常龐大的世界����,至少是近似地處理���。如果我們能夠引入附加的相關信息��,近似的程度還可以進一步地提高�。
現在回到圖中的條件概率分布上�����。每一個分布都被顯示為一個條件概率表(CPT, Conditional Probability Table)���。這種形式的表格適用于離散型隨機變量�。本文也僅討論這種類型的表示方法���。CPT中的每一行包含了每個節點值在給定條件下的條件概率����。這個所謂的“給定條件”就是所有父節點取值的某個可能組合����。每一行概率加起來和必需是1��,因為行中條目表示了該對應變量的一個無遺漏的情況集合��。對于布爾變量��,一旦知道它為真的概率是p�,那么它為假的概率就應該是1-p���。所以可以省略第二個數值���。通常���,一個具有k個布爾父節點的布爾變量的CPT中有2^k個獨立的可指定概率����。而對于沒有父節點的節點而言���,它的CPT只有一行��,表示了該變量可能取值的先驗概率(例如圖中的Burglary和Earthquake對應的CPT)��。
四����、模型推理
當我們已經確定了一個貝葉斯網絡的結構時��,如何利用它進行推理將成為焦點��。例如現在我們想知道當John和Mary都打電話時發生地震的概率����。即 P(E = T | J = T, M = T) = ?
總的來說���,通?���?刹捎玫姆椒ㄓ腥N:1)首先是利用與樸素貝葉斯類似方法來進行推理(其中同樣用到貝葉斯公式)�,我們稱其為枚舉法��;2)其次是一種更為常用的算法�����,我們稱之為消去法�����;3)最后還有一種基于蒙特卡洛法的近似推理方法�����,本文將僅討論前兩種算法���。
4.1 枚舉法
為了詳細地說明原委��,我們還是從一個簡單的概率論知識點開始��。眾所周知����,由n個隨機變量X1, X2, ..., Xn構成的向量
X = (X1, X2, ..., Xn) 稱為n維隨機向量(或稱n維隨機變量)���。首先我們以二維隨機向量(X,Y)為例來說明邊緣分布的概念����。隨機向量(X,Y)的分布函數F(x,y)完全決定了其分量的概率特征�����。所以由F(x,y)便能得出分量X的分布函數FX(x)����,以及分量Y的分布函數FY(y)����。而相對于聯合分布F(x,y)����,分量的分布FX(x)和FY(y)稱為邊緣分布���。由
FX(x) = P{X ≤ x} = P{X ≤ x, Y ≤ +∞} = F(x, +∞)
FY(y) = P{Y ≤ y} = P{X ≤ +∞,Y ≤ y} = F(+∞, y)
可得
FX(x) = F(x, +∞)��, FY(y) = F(+∞, y)
若(X,Y)為二維離散隨機變量���,則
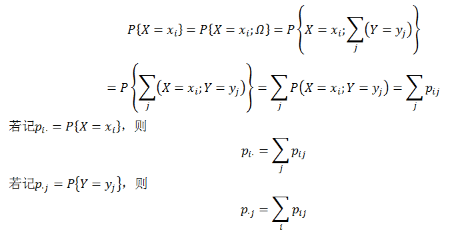
若(X,Y)為二維連續隨機變量����,設密度函數為p(x,y)�,則
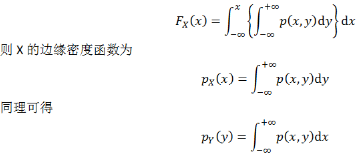
回想在樸素貝葉斯中所使用的策略��。我們根據已經觀察到的證據計算查詢命題的后驗概率�����。并將使用全聯合概率分布作為“知識庫”��,從中可以得到所有問題的答案���。這其中貝葉斯公式發揮了重要作用���,而下面的示例同樣演示了邊緣分布的作用���。從一個非常簡單的例子開始:一個由3個布爾變量Toothache�����、Cavity以及Catch (由于牙醫的鋼探針不潔而導致的牙齦感染)組成的定義域���。其全聯合分布是一個2 × 2 × 2 的表格��,如下表所示�。
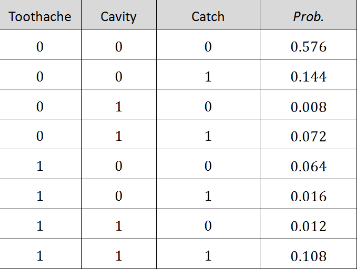
根據概率公理的要求�,聯合分布中的所有概率之和為1 �。無論是簡單命題還是復合命題��,我們只需要確定在其中命題為真的那些原子事件���,然后把它們的概率加起來就可獲得任何命題的概率�。例如�����,命題Cavity ∨ Toothache在 6 個原子事件中成立���,所以可得
P(Cavity ∨ Toothache) = 0.108 + 0.012 + 0.072 + 0.008 + 0.165 + 0.064 = 0.28
一個特別常見的任務是將隨機變量的某個子集或者某單個變量的分布抽取出來����,也就是我們前面提到的邊緣分布�。例如�,將所有Cavity取值為真的條目抽取出來在求和就得到了Cavity的無條件概率(也就是邊緣概率)
P(Cavity) = 0.108 + 0.012 + 0.072 + 0.008 = 0.2
該過程稱為邊緣化(Marginalisation)�,或者稱為“和出”(Summing Out)——因為除了Cavity以外的變量都被求和過程排除在外了�����。對于任何兩個變量集合Y和Z�����,可以寫出如下的通用邊緣化規則(這其實就是前面給出的公式��,我們只是做了簡單的變量替換)
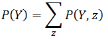
也就是說���,Y的分布可以通過根據任何包含Y的聯合概率分布對所有其它變量進行求和消元得到�����。根據乘法規則���,這條規則的一個變形涉及條件概率而不是聯合概率:
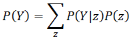
這條規則稱為條件化�。以后會發現�����,對于涉及概率表達式的所有種類的推導過程���,邊緣 化和條件化具有非常強大的威力���。
在大部分情況下�,在給定關于某些其它變量的條件下��,我們會對計算某些變量的條件概率產生感興趣�����。條件概率可以如此找到:首先根據條件概率的定義式得到一個無條件概率的表達式��,然后再根據全聯合分布對表達式求值�。例如�����,在給定牙疼的條件下��,可以計算蛀牙的概率為
P(Cavity | Toothache) = P(Cavity ∧ Toothache) / P(Toothache)
=( 0.108 +0.012) / (0.108 + 0.012 + 0.016 + 0.064) = 0.6
為了驗算�����,還可以計算已知牙疼的條件下�,沒有蛀牙的概率為
P(┐Cavity | Toothache) = P(┐Cavity ∧ Toothache) / P(Toothache)
=( 0.016 +0.064) / (0.108 + 0.012 + 0.016 + 0.064) = 0.4
注意這兩次計算中的項 1/P(Toothache) 是保持不變的���,與我們計算的Cavity的值無關�����。事實上�,可以把它看成是P(Cavity I Toothache) 的一個歸一化常數����,保證其所包含的概率相加等于1���,也就是忽略P(Toothache) 的值�����,這一點我們在樸素貝葉斯部分已經講過�����。
此外�����,我們將用α來表示這樣的常數����。用這個符號我們可以把前面的兩個公式合并寫成一個:
P(Cavity | Toothache) =α P(Cavity, Toothache)
=α [P(Cavity, Toothache, Catch) + P(Cavity, Toothache, ┐Catch)]
=α [〈0.108, 0.016〉+〈0.012, 0.064〉] = α〈0.12, 0.08〉=〈0.6, 0.4〉
在很多概率的計算中���,歸一化都是一個非常有用的捷徑���。
從這個例于里可以抽取出一個通用推理過程����。我們將只考慮查詢僅涉及一個變量的情況�����。我們將需要使用一些符號表示:令X 為查詢變量(前面例子中的Cavity)��;令E 為證據變量集合(也就是給定的條件���,即前面例子中的Toothache )�����, e 表示其觀察值�����;并令 Y 為其余的未觀測變量(就是前面例于中的Catch) ����。查詢為P(X I e)����,可以對它求值:
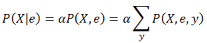
其中的求和針對所有可能的y (也就是對未觀測變量Y的值的所有可能組合)�����。注意變量 X, E 以及Y一起構成了域中所有布變量的完整集合��,所以P(X, e, y)只不過是來自全聯合分布概率的一個子集�。算法對所有X和Y的值進行循環以枚舉當 e 固定時所有的原子事件���,然后根據全聯合分布的概率表將它們的概率加起來�����,最后對結果進行歸一化����。
下面我們就用枚舉法來解決本節開始時拋出的問題: P(E = T | J = T, M = T) = ?
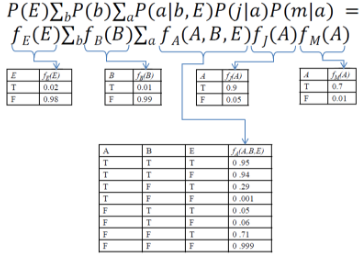
P(E|j,m) = α P(E, j, m)
其中����,我們用小寫字母 j 和 m 來表示 J = T����,以及M = T(也就是給定J和M)����。但表達式的形式是P(E|j,m)而非P(e|j,m)�,這是因為我們要將E = T 和 E = F這兩個公式合并起來寫成一個����。同樣����,α 是標準化常數�����。然后就要針對其他未觀測變量(也就是本題中的Burglary和Alarm)的值的所有可能組合進行求和����,則有
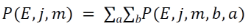
根據圖2中所示之貝葉斯網絡����,應該很容易可以寫出下列關系式��。
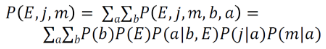
如果你無法輕易地看出這種關系���,也可以通過公式推導一步一步的得出���。首先����,在給定條件a的情況下�,J和M條件獨立���,所以有P(j,m|a) = P(j|a)P(m|a)����。B和E獨立����,所以有P(b)P(E)=P(b,E)�����。進而有P(b)P(E)P(a|b,E)=P(a,b,E)�����。在給定a的時候����,b�、E和j�����、m獨立(對應圖1中的第3種情況)�,所以有P(j,m|a) = P(j,m|a,b,E)����。由這幾個關系式就能得出上述結論����。
下面我們來循環枚舉并加和消元���。
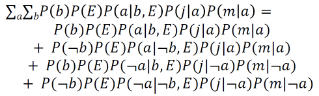
在計算上還可以稍微做一點改進�。因為P(E)對于ΣaΣb來說是一個常數���,所以可以把它提出來��。這樣就避免了多次乘以P(E)所造成的低效����。
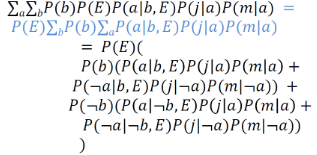
上式中所有的值都可以基于CPT求得����,算術當然是很繁雜的��,我們這里不具體給出最終的結果����。但一個顯而易見的事實是當變量的數目變多時����,全聯合分布的表長增長是相當驚人的�����!所以我們非常希望能夠有一種更輕巧的辦法來替代這種枚舉法��,于是便有了下面將要介紹的消去法�����。
4.2 消去法
變量消去算法(Variable Elimination Algorithm)是一種基于動態規劃思想設計的算法���。而且在算法執行的過程中需要使用因子表來儲存中間結果�,當再次需要使用時無需重新計算而只需調用已知結果����,這樣就降低了算法執行的時間消耗�。
Each factor is a matrix indexed by the values of its argument variable. 例如��,與P(j|a)和P(m|a)相對應的因子fJ(A)和fM(A)只依賴于A�����,因為J和M在我們的問題里是已知的����,因此fJ(A)和fM(A)都是兩個元素的矩陣(也是向量)
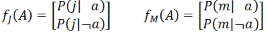
在這種記法中括號里的參數表示的是變量�����,而下標僅僅是一種記號���,所以你也可以使用f4(A)和f5(A)來代替fJ(A)和fM(A)��。但我們這里使用J和M來作為下標的意圖是考慮用P( _ | A)的 _ 來作為標記�����。所以P(a|b,E)可以寫成fA(A, B, E)��,注意因為A����,B, E都是未知的�����,所以fA(A, B, E) 就是一個2×2×2的矩陣��,即數據分析師培訓
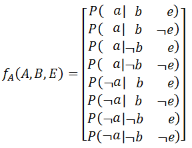
最初的因子表是經CPT改造而來的��,如下圖所示����。
然后進行自底向上的計算����,Step1: fJ(A)×fM(A) = fJM(A)��,A仍然是變量�,則有
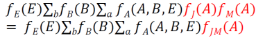
此時新產生的因子表為
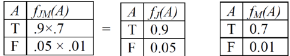
Step2: fA(A, B, E)×fJM(A) = fAJM(A, B, E)�,即
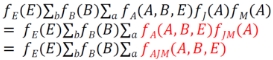
此時新產生的因子表為

Step3:
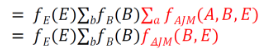
此時新產生的因子表為
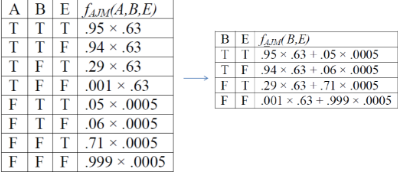
Step4:
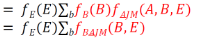
此時新產生的因子表為

Step5:
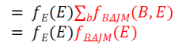
此時新產生的因子表為

Step6:
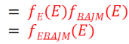
此時新產生的因子表為
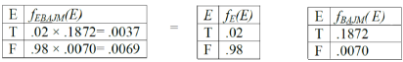
由此便可根據上表算得問題之答案
P(E=T | j,m) = P(E=T | j,m) / [P(E=T | j,m) + P(E=F | j,m)] = 0.0037/(0.0037 + 0.0069) = 0.3491
最后總結一下消去算法的執行步驟:

CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
