在R中使用支持向量機(SVM)進行數據挖掘(下)
第二種使用svm()函數的方式則是根據所給的數據建立模型�����。這種方式形式要復雜一些����,但是它允許我們以一種更加靈活的方式來構建模型����。它的函數使用格式如下(注意我們僅列出了其中的主要參數)���。
[plain] view plain copy
svm(x, y = NULL, scale = TRUE, type = NULL, kernel = "radial",
degree = 3, gamma = if (is.vector(x)) 1 else 1 / ncol(x),
coef0 = 0, cost = 1, nu = 0.5, subset, na.action = na.omit)
此處�����,x可以是一個數據矩陣��,也可以是一個數據向量����,同時也可以是一個稀疏矩陣�����。y是對于x數據的結果標簽����,它既可以是字符向量也可以為數值向量�。x和y共同指定了將要用來建模的訓練數據以及模型的基本形式���。
參數type用于指定建立模型的類別��。支持向量機模型通?����?梢杂米鞣诸惸P?���、回歸模型或者異常檢測模型����。根據用途的差異�����,在svm()函數中的type可取的值有C-classification���、nu-classification�、one-classification�����、eps-regression和nu-regression這五種類型中��。其中��,前三種是針對于字符型結果變量的分類方式����,其中第三種方式是邏輯判別����,即判別結果輸出所需判別的樣本是否屬于該類別��;而后兩種則是針對數值型結果變量的分類方式����。
此外�����,kernel是指在模型建立過程中使用的核函數�����。針對線性不可分的問題����,為了提高模型預測精度�,通常會使用核函數對原始特征進行變換��,提高原始特征維度���,解決支持向量機模型線性不可分問題���。svm()函數中的kernel參數有四個可選核函數�,分別為線性核函數�����、多項式核函數����、高斯核函數及神經網絡核函數���。其中����,高斯核函數與多項式核函數被認為是性能最好�����、也最常用的核函數���。
核函數有兩種主要類型:局部性核函數和全局性核函數���,高斯核函數是一個典型的局部性核函數��,而多項式核函數則是一個典型的全局性核函數����。局部性核函數僅僅在測試點附近小領域內對數據點有影響��,其學習能力強���、泛化性能較弱�;而全局性核函數則相對來說泛化性能較強����、學習能力較弱���。
對于選定的核函數�,degree參數是指核函數多項式內積函數中的參數����,其默認值為3�。gamma參數給出了核函數中除線性內積函數以外的所有函數的參數��,默認值為l���。coef0參數是指核函數中多項式內積函數與sigmoid內積函數中的參數�,默認值為0��。
另外��,參數cost就是軟間隔模型中的離群點權重����。最后�����,參數nu是用于nu-regression�����、nu-classification和one-classification類型中的參數��。
一個經驗性的結論是���,在利用svm()函數建立支持向量機模型時����,使用標準化后的數據建立的模型效果更好��。
根據函數的第二種使用格式�����,在針對上述數據建立模型時����,首先應該將結果變量和特征變量分別提取出來�。結果向量用一個向量表示��,特征向量用一個矩陣表示���。在確定好數據后還應根據數據分析所使用的核函數以及核函數所對應的參數值��,通常默認使用高斯內積函數作為核函數����。下面給出一段示例代碼

在使用第二種格式建立模型時�����,不需要特別強調所建立模型的形式����,函數會自動將所有輸入的特征變量數據作為建立模型所需要的特征向量�����。在上述過程中����,確定核函數的gamma系數時所使用的代碼所代表的意思是:如果特征向量是向量則gamma值取l���,否則gamma值為特征向量個數的倒數�。
在利用樣本數據建立模型之后����,我們便可以利用模型來進行相應的預測和判別��?��;谟蓅vm()函數建立的模型來進行預測時�����,可以選用函數predict()來完成相應工作����。在使用該函數時��,應該首先確認將要用于預測的樣本數據�,并將樣本數據的特征變量整合后放入同一個矩陣���。來看下面這段示例代碼�����。

通常在進行預測之后����,還需要檢查模型預測的準確情況���,這時便需要使用函數table()來對預測結果和真實結果做出對比展示����。從上述代碼的輸出中����,可以看到在模型預測時����,模型將所有屬于setosa類型的鳶尾花全部預測正確���;模型將屬于versicolor類型的鳶尾花中有48朵預測正確�,但將另外兩朵錯誤地預測為virginica類型���;同樣����,模型將屬于virginica類型的鳶尾花中的48朵預測正確����,但也將另外兩朵錯誤地預測為versicolor類型�。
函數predict()中的一個可選參數是decision.values�����,我們在此也對該參數的使用做簡要討論���。默認情況下����,該參數的缺省值為FALSE��。若將其置為TRUE�����,那么函數的返回向量中將包含有一個名為“decision.values”的屬性��,該屬性是一個n*c的矩陣����。這里����,n是被預測的數據量, c是二分類器的決策值�。注意���,因為我們使用支持向量機對樣本數據進行分類���,分類結果可能是有k個類別����。那么這k個類別中任意兩類之間都會有一個二分類器�。所以��,我們可以推算出總共的二分類器數量是k(k-1)/2��。決策值矩陣中的列名就是二分類的標簽���。來看下面這段示例代碼���。
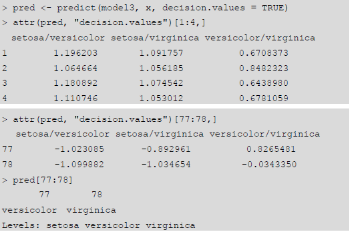
由于我們要處理的是一個分類問題�����。所以分類決策最終是經由一個sign(?)函數來完成的��。從上面的輸出中可以看到��,對于樣本數據4而言�,標簽setosa/versicolor對應的值大于0��,因此屬于setosa類別����;標簽setosa/virginica對應的值同樣大于0��,以此判定也屬于setosa��;在二分類器versicolor/virginica中對應的決策值大于0��,判定屬于versicolor�����。所以�,最終樣本數據4被判定屬于setosa����。依據同樣的羅輯�����,我們還可以根據決策值的符號來判定樣本77和樣本78��,分別是屬于versicolor和virginica類別的�����。
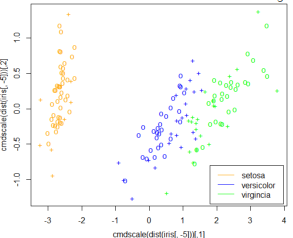
為了對模型做進一步分析��,可以通過可視化手段對模型進行展示�����,下面給出示例代碼�����。結果如圖14-15所示��?����?梢?�,通過plot()函數對所建立的支持向量機模型進行可視化后���,所得到的圖像是對模型數據類別的一個總體觀察����。圖中的“+”表示的是支持向量�,圓圈表示的是普通樣本點����。
[plain] view plain copy
> plot(cmdscale(dist(iris[,-5])),
+ col = c("orange","blue","green")[as.integer(iris[,5])],
+ pch = c("o","+")[1:150 %in% model3$index + 1])
> legend(1.8, -0.8, c("setosa","versicolor","virgincia"),
+ col = c("orange","blue","green"), lty = 1)
在圖14-15中我們可以看到����,鳶尾花中的第一種setosa類別同其他兩種區別較大�,而剩下的versicolor類別和virginica類別卻相差很小���,甚至存在交叉難以區分�。注意�����,這是在使用了全部四種特征之后仍然難以區分的��。這也從另一個角度解釋了在模型預測過程中出現的問題���,所以模型誤將2朵versicolor 類別的花預測成了virginica 類別���,而將2朵virginica 類別的花錯誤地預測成了versicolor 類別�,也就是很正?�,F象了�����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
