R語言數據集合并�����、數據增減�����、不等長合并
數據選取與簡單操作:
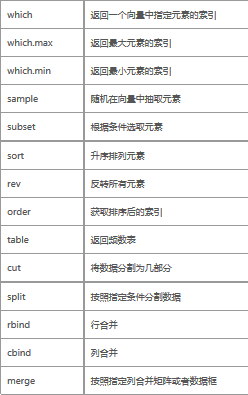
一�����、數據合并
1����、merge()函數
最常用merge()函數�����,但是這個函數使用時候這兩種情況需要注意:
1����、merge(a,b)����,純粹地把兩個數據集合在一起����,沒有溝通a�、b數據集的by���,這樣出現的數據很多��,相當于a*b條數據����;
2���、merge函數是匹配到a,b數據集的并���,都有的才匹配出來���,如果a�����、b數據集ID不同�����,要用all=T(下面有all用法的代碼)��。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#橫向合并
ID<-c(1,2,3,4)
name<-c("Jim","Tony","Lisa","Tom")
score<-c(89,22,78,78)
student1<-data.frame(ID,name)
student2<-data.frame(ID,score)
total_student<-merge(student1,student2,by="ID") #或者rbind()
total_student
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#縱向合并
ID<-c(1,2,3)
name<-c("Jame","Kevin","Sunny")
student1<-data.frame(ID,name)
ID<-c(4,5,6)
name<-c("Sun","Frame","Eric")
student2<-data.frame(ID,name)
total<-cbind(student1,student2)
total
merge的all用法
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> id=c("1","2","3")
> M=c("7","2","3")
> ink2=data.frame(id,M)
>
> merge(ink1,ink2,by="id",all=T) #所有數據列都放進來�����,空缺的補值為NA
id R M
1 1 9 7
2 2 7 2
3 4 9 <NA>
4 3 <NA> 3
> merge(ink1,ink2,by="id",all=F) #默認���,只取兩者的共有的部分
id R M
1 1 9 7
2 2 7 2
其中���,all=T代表全連接���,all.x=T代表左聯結�����;all.y=T代表右連接
2��、dplyr包
dplyr包的數據合并�����,
一般用left_join(x,y,by="name") 以x為主����,y中匹配到的都放進來����, 但�,y中沒有的則不放過來���。
需要這個x數據集是全集����,比較大���。


3����、paste函數
生成一長串字符向量�。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
paste(c("X","Y"),1:10,sep="") #"X”,"Y"是長度為2的字符向量,1:10 長度為10的向量�。命令是讓這兩個向量粘合在一起生成新的字符串向量���,粘合后的新字符之間沒有間隔���。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#—————————paste中seq與collapse區別————————————————————
a = c(1, 2, 3, 4, 5)
names(a) = c('m', 'n','o', 'p', 'q')
# 主要是區分使用sep和collapse
b = paste(a, names(a), sep = "/") #不同向量合并在一起�,但是還是各自向量
c = paste(b, collapse = ",") #不同向量合并在一起����,但是變成一個向量
mode(b) #變量類型
mode(c)
4����、cbind和rbind函數
cbind()和rbind()���,cbind()按照縱向方向���,或者說按列的方式將矩陣連接到一起����。
rbind()按照橫向的方向���,或者說按行的方式將矩陣連接到一起
rbind/cbind對數據合并的要求比較嚴格:合并的變量名必須一致�����;數據等長���;指標順序必須一致��。相比來說�,其他一些方法要好一些�,有dplyr���,sqldf中的union
5�����、sqldf包
利用SQL語句來寫���,進行數據合并��,適合數據庫熟悉的人���,可參考:
R語言︱ 數據庫SQL-R連接與SQL語句執行(RODBC���、sqldf包)
二��、數據增減
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
x=x[,-1] #這個就代表�,刪除了x數據集中第一列數據
或用dplyr包中的mutate函數
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
a=mutate(Hdma_dat,dou=2*survived,dou4=4*survived)
Hdma_dat$dou=a$dou
Hdma_dat$dou4=a$dou4 #兩個新序列��,加入到Hdma數據集匯總
篩選變量服從某值的子集
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
subset(airquality, Temp > 80, select = c(Ozone, Temp))
subset(airquality, Day == 1, select = -Temp)
subset(airquality, select = Ozone:Wind)
三��、數據縱橫加總
R使用rowSums函數對行求和�,使用colSums函數對列求和���。
四���、不等長合并
1���、plyr包
rbind.fill函數可以很好將數據進行合并���,并且補齊沒有匹配到的缺失值為NA��。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#————————————————————————————不等長合并
#如何解決合并時數據不等長問題——兩種方法:do.call函數以及rbind.fill函數(plyr包)
#rbind.fill函數只能合并數據框格式
#do.call函數在數據框中執行函數(函數���,數據列)
library("plyr") #加載獲取rbind.fill函數
#第一種方法
list1<-list()
list1[[1]]=data.frame(t(data.frame(Job_Pwordseg.ct[1])))
list1[[2]]=data.frame(t(data.frame(Job_Pwordseg.ct[2])))
do.call(rbind.fill,list1)
#第二種方法
u=rbind.fill(data.frame(t(data.frame(Job_Pwordseg.ct[1]))),data.frame(t(data.frame(Job_Pwordseg.ct[2]))))
核心函數是plyr包中的rbind.fill函數(合并的數據����,必須是data.frame)�,do.call可以用來批量執行�����。(do.call用法)
關于do.call其他用法(R語言 函數do.call()使用 )
有一個list���,想把里面的所有元素相加求和�。發現了兩個很有意思的函數
list <- list(matrix(1:25, ncol = 5), matrix(4:28, ncol = 5), matrix(21:45, ncol=5))
list.sum<-do.call(sum,list)
list.sum<-do.call(cbind,list)
do.call() 是告訴list一個函數�,然后list里的所有元素來執行這個函數���。
2�、dplyr包
dplyr::bind_rows()
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
mpg cyl hp drat wt qsec vs am gear carb disp
(dbl) (dbl) (dbl) (dbl) (dbl) (dbl) (dbl) (dbl) (dbl) (dbl) (dbl)
1 21.0 6 110 3.90 2.620 16.46 0 1 4 4 NA
2 21.0 6 110 3.90 2.875 17.02 0 1 4 4 NA
3 22.8 4 93 3.85 2.320 18.61 1 1 4 1 NA
4 21.4 6 110 3.08 3.215 19.44 1 0 3 1 NA
5 17.8 6 123 3.92 3.440 18.90 1 0 4 4 167.6
6 16.4 8 180 3.07 4.070 17.40 0 0 3 3 275.8
7 17.3 8 180 3.07 3.730 17.60 0 0 3 3 275.8
8 15.2 8 180 3.07 3.780 18.00 0 0 3 3 275.8
效果是����,不匹配到的放在最后����,且等于NA NA NA NA
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
