R語言基因組數據分析可能會用到的data.table函數整理
R語言data.table包是自帶包data.frame的升級版����,用于數據框格式數據的處理����,最大的特點快���。包括兩個方面�����,一方面是寫的快���,代碼簡潔�,只要一行命令就可以完成諸多任務�,另一方面是處理快�����,內部處理的步驟進行了程序上的優化����,使用多線程��,甚至很多函數是使用C寫的���,大大加快數據運行速度���。因此��,在對大數據處理上���,使用data.table無疑具有極高的效率����。這里主要介紹在基因組數據分析中可能會用到的函數�����。
fread
做基因組數據分析時��,常常需要讀入處理大文件��,這個時候我們就可以舍棄read.table��,read.csv等����,使用讀入速度快的fread函數
fread(input, sep="auto", sep2="auto", nrows=-1L, header="auto", na.strings="NA", file,
stringsAsFactors=FALSE, verbose=getOption("datatable.verbose"), autostart=1L,
skip=0L, select=NULL, drop=NULL, colClasses=NULL,
integer64=getOption("datatable.integer64"),# default: "integer64"
dec=if (sep!=".") "." else ",", col.names,
check.names=FALSE, encoding="unknown", quote="\"",
strip.white=TRUE, fill=FALSE, blank.lines.skip=FALSE, key=NULL,
showProgress=getOption("datatable.showProgress"), # default: TRUE
data.table=getOption("datatable.fread.datatable") # default: TRUE
)
input 輸入的文件�����,或者字符串(至少有一個"\n")��;
sep 列之間的分隔符���;
sep2 分隔符內再分隔的分隔符��,功能還沒有應用����;
nrow 讀取的行數��,默認-l全部��,nrow=0僅僅返回列名��;
header 第一行是否是列名�����;
na.strings 對NA的解釋��;
file 文件路徑��,再確保沒有執行shell命令時很有用�����,也可以在input參數輸入;
stringsASFactors 是否轉化字符串為因子;
verbose 是否交互和報告運行時間���;
autostart 機器可讀這個區域任何行號�,默認1L,如果這行是空���,就讀下一行;
skip 跳過讀取的行數���,為1則從第二行開始讀��,設置了這個選項��,就會自動忽略autostart選項�����,也可以是一個字符,skip="string",那么會從包含該字符的行開始讀�;
select 需要保留的列名或者列號����,不要其它的��;
drop 需要取掉的列名或者列號�,要其它的����;
colClasses 類字符矢量�����,用于罕見的覆蓋而不是常規使用�,只會使一列變為更高的類型��,不能降低類型�;
integer64 讀如64位的整型數;
dec 小數分隔符��,默認"."不然就是","
col.names 給列名�,默認試用header或者探測到的�,不然就是V+列號;
encoding 默認"unknown"����,其它可能"UTF-8"或者"Latin-1"����,不是用來重新編碼的��,而是允許處理的字符串在本機編碼;
quote 默認"""��,如果以雙引開頭�����,fread強有力的處理里面的引號�,如果失敗了就會用其它嘗試���,如果設置quote="",默認引號不可用
strip.white 默認TRUE�,刪除結尾空白符�����,如果FALSE,只取掉header的結尾空白符���;
fill 默認FALSE�,如果TRUE�,不等長的區域可以自動填上�,利于文件順利讀入�;
blank.lines.skip 默認FALSE,如果TRUE��,跳過空白行
key 設置key�����,用一個或多個列名����,會傳遞給setkey
showProgress TRUE會顯示腳本進程��,R層次的C代碼
data.table TRUE返回data.table��,FALSE返回data.frame

可見1.8GB的數據讀入94秒�,讀入文件速度非?��??br />
fwrite
對數據框數據進行處理后�,需要保存到文件��,我們就可以使用fwrite多線程寫出����,速度特別快
fwrite(x, file = "", append = FALSE, quote = "auto",
sep = ",", sep2 = c("","|",""),
eol = if (.Platform$OS.type=="windows") "\r\n" else "\n",
na = "", dec = ".", row.names = FALSE, col.names = TRUE,
qmethod = c("double","escape"),
logicalAsInt = FALSE, dateTimeAs = c("ISO","squash","epoch","write.csv"),
buffMB = 8L, nThread = getDTthreads(),
showProgress = getOption("datatable.showProgress"),
verbose = getOption("datatable.verbose"))
x 具有相同長度的列表�����,比如data.frame和data.table等�;
file 輸出文件名,""意味著直接輸出到操作臺�;
append 如果TRUE,在原文件的后面添加��;
quote 如果"auto",因子和列名只有在他們需要的時候才會被加上雙引號����,例如該部分包括分隔符�����,或者以"\n"結尾的一行�,或者雙引號它自己��,如果FALSE�,那么區域不會加上雙引號���,如果TRUE�����,就像寫入CSV文件一樣���,除了數字����,其它都加上雙引號����;
sep 列之間的分隔符����;
sep2 對于是list的一列�,寫出去時list成員間以sep2分隔�,它們是處于一列之內����,然后內部再用字符分開�����;
eol 行分隔符��,默認Windows是"\r\n",其它的是"\n"�;
na,na 值的表示�����,默認""���;
dec 小數點的表示���,默認"."���;
row.names 是否寫出行名�,因為data.table沒有行名�,所以默認FALSE�����;
col.names 是否寫出列名�,默認TRUE�����,如果沒有定義����,并且append=TRUE和文件存在���,那么就會默認使用FALSE;
qmethod 怎樣處理雙引號��,"escape",類似于C風格�����,用反斜杠逃避雙引�,“double",默認�,雙引號成對����;
logicalAsInt 邏輯值作為數字寫出還是作為FALSE和TRUE寫出����;
dateTimeAS 決定 Date/IDate,ITime和POSIXct的寫出����,"ISO"默認�,-2016-09-12, 18:12:16和2016-09-12T18:12:16.999999Z;"squash",-20160912,181216和20160912181216999;"epoch",-17056���,65536和1473703936;"write.csv"��,就像write.csv一樣寫入時間�����,僅僅對POSIXct有影響��,as.character將digits.secs轉化字符并通過R內部UTC轉回本地時間����。前面三個選項都是用新的特定C代碼寫的����,較快;
buffMB 每個核心給的緩沖大小��,在1到1024之間�,默認80MB;
nThread 用的核心數;
showProgress 在工作臺顯示進程���,當用file==""時���,自動忽略此參數;
verbose 是否交互和報告時間

dcast.data.table
和reshape2包的dcast一樣�, 這個函數用來重鑄表格����,并且再在大數據的處理上��,比reshape2的內存更優化����,函數效果如下

原表格 鑄造后(v4作為value)
dcast(data, formula, fun.aggregate = NULL, sep = "_",
..., subset = NULL, margins=NULL,fill = NULL,
drop = TRUE, value.var = guess(data),
verbose = getOption("datatable.verbose"))
data 一個data.table;
formula 要鑄造的表格的LHS~RHS格式;LHS和RHS可以是"..."和“.",其中"..."代表全部變量,"."代表無變量�����;
fun.aggregate 是否在鑄造之前匯總���,應提供函數list(比如mean�����,sum或者c(sum,mean))��,默認length�����;
sep 鑄造的時候連接字符變量的連接符����,默認_����;
subset 指定要鑄造的子集;利用��;
margins 函數尚不能應用(作者還沒寫好)����,預計設定編輯匯總方向��;
fill 填充缺失值�;
drop 設置成FALSE顯示沒有聯合成功的行列
value.var 填充值的列�,默認會猜測
現在我需要取數據DT的v1,v2兩列相同的情況作為匯總的一類�����,對它們的v4值取平均���,轉換如下�,

轉換前轉換后
當然�,上述過程也可以用data.table[ i , j , by ]語法做
但是如果我要將上述DT中的v3作為一個影響因素��,作為tag�,先按v1����、v2匯總�����,再將對應的v4值分為v3=1和v3=2兩類����,查看v1�����、v2取值相同v3不同對應v4的情況�����,這個時候用dcast或者會更加方便���,如下

melt
和reshape2包的melt一樣���,融合表格�,這個是用C語言寫的���,處理速度更快��。
處理前:

處理后:

melt(data, id.vars, measure.vars,
variable.name = "variable", value.name = "value",
..., na.rm = FALSE, variable.factor = TRUE,
value.factor = FALSE,
verbose = getOption("datatable.verbose"))
data data.table對象���;
id.vars id變量組成的矢量�����,可以對應列號���,也可以對應列名���;缺失的話�,非測量變量會被賦值��;
measure.vars 測量變量組成的是矢量或者列表�,可以對應列號和列名��,也支持pattern函數��,下面會提到�����,如果缺失����,非id變量會被賦值�;如果measure.vars和id.vars都沒有賦予����,全部非數字列會作為id.vars�����,剩余作為measure.vars��;如果measure變量不是同一種類型����,那么會被強制轉換���,等級如下list > character > numeric > integer > logical��;
variable.name 測量變量列名�����,默認"variable"����;
value.name 融合后數據的數值列名�;
na.rm 如果TRUE�����,移除NA值�;
variable.factor 如果TRUE,變量列轉化為因子��;
verbose 如果TRUE�,在工作臺產生交互信息��,默認options(datatable.verbose=TRUE)
對于前面的DT���,我現在將f和d開頭的列名的列作為測量變量���,如下
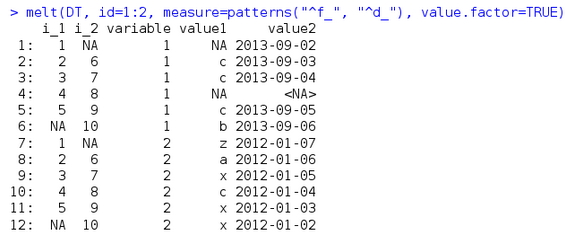
pattern函數下面會講�,這里再講一下的是melt和dcast的聯合使用�����,先用melt融合�,再用dcast重鑄
如下面例子
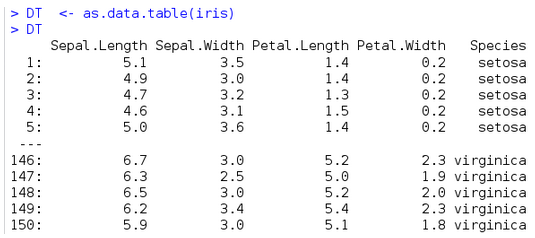
原DT
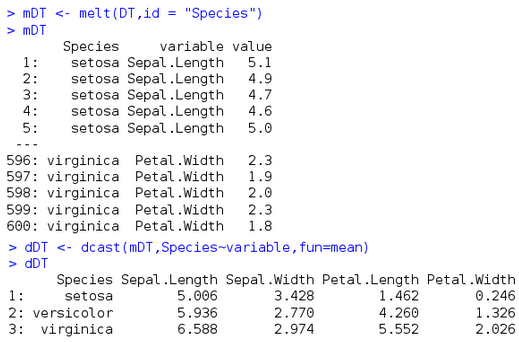
melt 后 再進行dcast后
其實上述過程用data.table [ i , j , by ]語法也可以
看個人需要吧����,各種各樣不同的方法都了解了以后�,當你真正需要用到達到某個目的時����,你的腦海里就會自動匹配上最佳的處理方法���。

patterns
patterns是melt函數內部使用的函數��,匹配正則表達式���。melt的時候可以用正則去匹配列名
patterns(..., cols=character(0))
... 正則表達式集����;
cols 要匹配的字符矢量�;
例子在講melt函數的時候已有
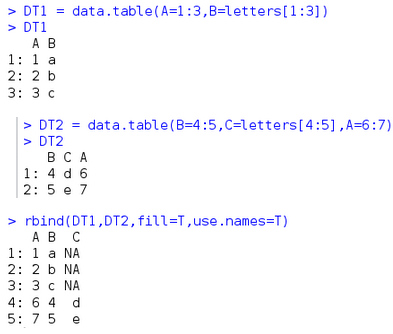
rbindlist
類似于data.frame的rbind�,不過比rbind的速度更快����,并且總是返回data.table��。也有不同之處�,一是use.names參數��,可以指定是否使用相同列名bind���,二是rbindlist可以使用在不知道對象名字的情況下�����,比如lapply(fileNames, fread) ���。
rbindlist(l, use.names=fill, fill=FALSE, idcol=NULL)
l 對象列表��,也可以分開寫
use.names 如果TRUE, bind的時候匹配行名����,默認FALSE���,像rbind一樣�,直接bind�,當時TRUE的時候����,至少要有一個對象的一列要存在行名�;
fill 如果TRUE���,缺失的列用NA填充�,這個時候bind的對象可以不同列數��,并且use.names自動設為TRUE,這個時候至少要有一個對象的一列要存在行名�����;
idcol 產生一個index列��,默認(NULL)不產生�,如果idcol=TRUE����,行名自動為.id�,當然你也可以直接命名���,比如idcol="id"���;
between
是data.table i 語法的擴展功能����,between等同于x >= lower 并且 x <= upper 當incbounds設置為TRUE的時候��,設置為FALSE的時候則是x > lower 并且 x < upper
between(x, lower, upper, incbounds=TRUE)
x %between% y
x 任意的可以排序的矢量����,可以用"<="比較的
lower 較低的范圍����;
upper 較高的范圍����;
y 長度為2的矢量或者列表,y[1] 相當于lower����,y[2] 相當于upper��;
incbounds 如果TRUE意味著包括邊界���,即<=或者>= ���,默認TRUE����;
例如有基因組注釋文件如下
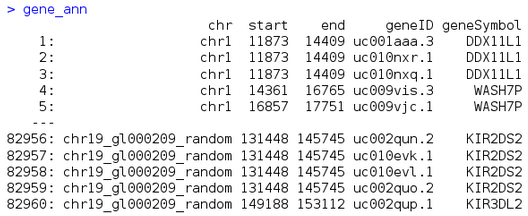
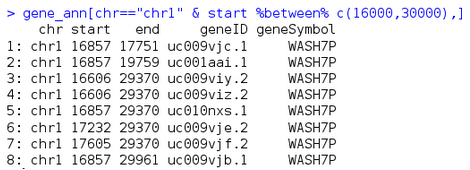
我想取出在chr1上�,start在16000到30000之間的geneID��,可以用beween
foverlaps
尋找重疊的區域,返回index對,x是數據很大但都是小區域的data.table����,用來檢索��,y是檢索用的資料�����,數據較小���,都是大區域���。

foverlaps(x, y, by.x = if (!is.null(key(x))) key(x) else key(y),
by.y = key(y), maxgap = 0L, minoverlap = 1L,
type = c("any", "within", "start", "end", "equal"),
mult = c("all", "first", "last"),
nomatch = getOption("datatable.nomatch"),
which = FALSE, verbose = getOption("datatable.verbose"))
x,y data.table��,y需要設置key����,x并不需要設置key���;
by.x,by.y 用來計算重疊的列名或者列號的矢量���,by.x和by.y的最后兩列都應該對應各自的(x,y的)start和end區間列���,并且start列應該總是小于end列��,如果x設置了key ��,by.x相當于key(x),否則by.x就默認key(y)�����。by.y默認key(y)����;
maxgap 設定兩個區域空白區允許的最大值��,參數尚不能使用��;
minoverlap 設定兩個區域最小的重疊區����,參數尚不能使用��;
type 設置重疊類型����。默認any���?���?梢栽O置為any,within,start,end和equal���。equal尚不能使用��。假設x,y區間分別為[ a,b ]和[ c,d ] , start 要求a==c , end要求b==d , within要求 a>=c 并且b <= d , equal要求a==c,b==d, 如果是any的話�,只要c<=b 并且d>=a 就可以了�;
mult 當y里面的多行都匹配x里面的行���,mult=控制返回��,默認all���,也可以設置為"first”和last�����;
nomatch 默認nomatch=NA,無匹配返回NA�,也可以設置為0���,0不返回該行����;
which 默認FALSE結果返回x和y行的聯合����,當是TRUE時����,如果mult=“all”���,返回兩列���,一列x列號���,一列相對應的y����,如果nomatch=NA�����,不匹配的返回y的NA,如果nomatch=0,則跳過該列��,設置mult="first“�����,mult=”last"則最后返回x一樣的行數�����;
verbose 當時TRUE的時候�����,工作臺交互
chmatch
返回各字符串在第二個對象的首匹配位置���,是match和%in%的加速版本����。和fastmatch包的fmatch相比�,各有優缺點����。fmatch第一次匹配較慢���,第二次匹配快�����,chmatch匹配雖然沒有fmatch第二次匹配快���,但是首次匹配也有較快的速度���。
chmatch(x, table, nomatch=NA_integer_)
x %chin% table
x 字符矢量����,需要去匹配的值��;
table 字符矢量�,匹配的目標�����;
nomatch 不匹配時返回的值�����,強制轉化整型

好了�����,寫到這里寫的都有點累了�,再介紹最后一個函數�,有時候我們需要了解你寫的這個腳本運行所花費的時間�����,這個時候保存開始運行時間和結束運行時間�����,再進行相減之類的好像有點麻煩�,其實我們可以用這個timetaken函數.數據分析師培訓
timetaken
timetaken(started.at)
started.at proc.time( )的結果

CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
