異常檢測的數據挖掘方法
我們正淹沒在從世界范圍內收集的海量的數據里����,同時我們也渴求知識
異常事件發生相對較少
然而��,一旦發生����,它們的影響將會很戲劇性�����,并且通常具有負面影響

"在草堆中找針��,草是如些多����,時間如此少"
什么是異常����?
異常是數據中不滿足期望行為的模式
也指離群點���,異常值�����,特異性��,驚奇性等
異常與現實生活中的實體對應
--網絡入侵
--信用卡欺詐
--機械系統中的缺陷
真實世界中的異常
信用卡欺詐
-信用卡上的費用異常高的定單
網絡入侵
-與FTP流量相關的WEB服務器
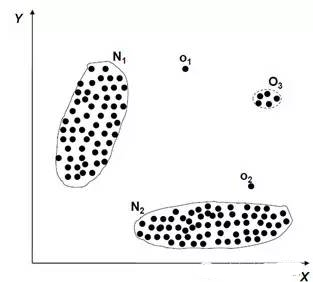
簡單例子
N1和N2是正常行為范
點o1和o2是異常點
在區域O3中的點也是異常點
相關的問題
稀有類挖掘
發現機會
新奇事物檢測
異常挖掘
消除噪聲
黑天鵝
關鍵的挑戰
定義一個具有代表性的正常區域很有挑戰性
正常行為與邊遠行為的界限通常是不精確的
標記數據對于訓練驗證的有效性
異常的精確定義在不同的應用領域是不一樣的
惡意的敵人
數據可能包含噪聲
正常行為不斷在演變
相關特征的適當選擇
Aspects of Anomaly Detection Problem(異常檢測問題的方面)
輸入數據的性質
略�。
指導的有效性
略��。
異常類型
點異常
單獨的數據實例是異常的
上下文異常
在一個上下文中單獨的數據實例是異常的
需要一個上下文的概念
也被稱為條件異常

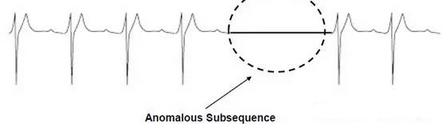
集體異常
相關數據實例的集體是異常的
在數據實例間需要一個關系
-有序數據
-空間數據
-圖數據
在一個集體異常中單獨的實例���,從它們自己看來并不是異常的
異常檢測的輸出
標記
-每一個測試實例給一個正?���;虍惓5臉擞?
-對基于分類的方法特別適用
得分
-每一個測試實例分配一個異常得分
允許排序輸出
需要一個附加的閥值參數
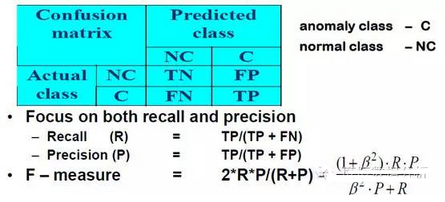
異常檢測技術的評估-F值
準確率對于評估來講并不是充分的度量
-舉例:網絡流量數據集��,具有99.9%的正常數據和0.1%的入侵數據
-簡單的分類器(使用正常類型標記)可以達到99.9%的準確率
Applications(應用)
網絡入侵檢測
保險/信用卡欺詐檢測
醫療信息/醫學診斷
工業損傷檢測
圖像處理/視頻監控
文本挖掘中的小說主題檢測
Different Types of Anomaly Detection Techniques(異常檢測技術的不同類型)
基于分類的技術
有指導的分類技術
半指導的分類技術
優勢:
(1)有指導分類技術
模型好理解
在檢測已經多類型的異常時���,具有較高的精度
(2)半指導分類技術
模型好理解
正常行為能夠精確地學習
劣勢:
(1)有指導分類技術
需要正常與異常類型的兩種標簽數據
不能檢測未知新出現的異常
(2)半指導分類技術
需要正常類型的標簽數據
對未使用的正常數據���,也可能以高的概率識別為異常
有指導的分類技術
操作數據記錄(過抽樣/欠抽樣/人工產生異?��!維MOTE】)
基于規則的技術【PN-rule, CREDOS】
基于模型的技術
基于神經網絡的方法
基于支持向量機的方法
基于貝葉斯網絡的方法
代價敏感的分類技術
基于總體的算法(SMOTEBoost��,RareBoost����,MetaCost)
半指導的分類技術
基于神經網絡的方法
基于支持向量機的方法
基于馬爾可夫模型的方法
基于規則的方法
基于最近鄰技術
重要假設:正常點有近鄰�,而異常點離其它點很遠
通常兩步方法
1����、計算每個數據記錄的鄰居
2��、分析鄰居決定數據記錄是否異常
分類:
基于距離的方法:異常點是那些離其它點最遠的點
基于密度的方法:異常點是處于低密度區域的點
優勢:
可用于無指導或半指導的情形中(對數據的分布無任何假設)
劣勢:
如果正常點沒有充足的鄰居數量�,該技術可能會失敗
運算量
在高維空間中���,數據是稀疏的����,相似性的概念也許不再有意義了��。由于稀疏性�����,兩個數據記錄之間的距離也許變得很相似���,這樣每個數據記錄也許會作為潛在的異常點被考慮
基于密度的方法
局部異常因子(LOF,Local Outlier Factor)
連接異常因子(COF,Connectivity Outlier Factor)
多粒度偏差因子(MDEF,Multi-Granularity Deviation Factor)LOCI
基于聚類的技術
主要假設:
正常數據屬于大的稠密的聚類���,而異常數據不屬性于任何有效的聚類
常用方法:
將數據聚成有限數量的聚類
至于它的最近的聚類�����,分析每一個數據實例
異常實例:
不符合任何聚類的數據實例
小聚類數據實例
低密度數據實例
在同一個聚類中�,離其它點很遠的數據實例
優勢:
無指導算法
存在的聚類算法可以被接入
劣勢:
如果數據沒有自然的聚類或聚類算法不能檢測自然的聚類��,該技術將失效
運算量大:使用索引結構也許會減輕該問題
在高維空間中���,數據是稀疏的�,兩個數據記錄間的距離也許會變得也很似
FindOut算法作為小波聚類(WaveCluster)的副產品
使用小波變換將數據轉換成多維信號
高頻信息符合聚類的分布邊界快速改變的區域
低頻部分符合數據集中的區域
移除這些高頻和低頻部分�,所有剩下的點就是異常點
使用聚類進行異常檢測
固定寬度的聚類首先被應用
第一個點是第一個聚類的中心
如果d(x1,x2)<=w����,那么x1和x2是靠近的�,其中w是用戶定義的參數
如果每個隨后的點是靠近的����,增加到一個類���,否則創建一個新的類
那些在小聚類中的點就是異常點
基于聚類的局部異常因子CBLOF
使用擠壓聚類算法執行聚類
為每一個數據實例確定CBLOF
如果數據記錄位于小聚類中����,CBLOF=聚類的大小*該數據實例與最近的更大一點聚類的距離
如果數據記錄位于大數據中��,CBLOF=聚類的大小*該數據實例與該數據實例所屬聚類的距離
基于統計的技術
主要假設:正常數據實例發生在統計分布的高概率區域����,然而異常發生在統計分布的低密度區別
常用方法:使用給定的數據估計一個統計分布��,然后應用一個統計推斷檢測來確定該檢驗的實例是否屬性該分布
如果一個觀測離樣本的平均值超過3倍標準差���,那么它就是異常的
優勢:
利用現有統計建模技術對不同的分布類型建模
提供一種統計上合理的解決方案來檢測異常值
劣勢:
由于具有高維度����,進行參數估計同時構建假設檢驗是很難的
假設的參數對真實數據未必有效
統計技術的類型
參數技術
假設正常數據(也有可能異常)產生自一個潛在的參數分布
從訓練樣本中學習參數
非參數技術
不會假設參數的任何知識
使用非參技術估計分布的密度
SmartSifter(SS)
具有連續與分類屬性數據的統計建模
直方圖密度用于表示分類屬性的概率密度
有限混合模型用于表示連續屬性的概率密度
對于一個測試實例�����,SS估計了由學習統計模型產生的測試實例的概率p(t-1)
接著���,測試實例被加入樣本���,然后該模型將重新估計
由新模型產生的測試實例的概率為p(t)
對于測試實例的異常得分是|p(t)-p(t-1)|
對正常與異常數據建模
如下給出數據D的分布:
D=(1-x)*M+x*A
M代表主體分布�����;A代表異常分布
M���,A分別代表正常與異常元素的集合
第1步:將所有的實例賦值給M�����,A初始化為空
第2步:對每個M中的實例xi
(1)估計M和A的參數
(2)計算分布D的log似然函數L
(3)從M中移走x�����,并且插入A
(4)重新估計M和A的參數
(5)計算分布D的log似然函數L'
(6)如果L'-L>a�,那么x是異常值����,否則從M中移除x
第3步:回到第2步
基于信息理論的技術
重要假設:異常值顯著地改變了數據集的信息內容
常用方法:檢測能夠顯著改變信息內容的數據實例
--需要一個信息理論度量
優勢:
可以在一個無指導的模式下操作
劣勢:
需要一個足夠敏感的信息理論度量來檢測由少數異常引起的不規則性
使用熵
找一個k大小的數據子集�����,該子集的移出�,將導致整個數據集熵的最大減少
使用一個近似的線性查找算法以直線性的方式搜索k大小的子集
其它的信息理論度量已經被研究了����,比如條件熵�����、相對條件熵��、信息增益��,等等
光譜技術
基于數據特征分解的分析
關鍵思想:
找到能夠捕捉大部分變化的屬性組合
屬性的縮減集能夠將正常的數據解釋得很好��,對于異常數據卻不是必要的
優勢:
在非指導模式下可以操作
劣勢:
它是基于這樣的假設�����,即異常和正常的實例在縮減后的空間中是可區分的
使用穩健的主成份分析
計算數據集的主成分
對每個測試的點�����,計算它在這些主成份下的投影
如果yi表示第i個主成份�,那么如下有一個卡方分布
sum(<i=1,q>,yi^2/ai)=y1^2/a1+y2^2/a2+y3^2/a3+...+yq^2/aq,q<=p
如果對于一個給定的顯著水平����,滿足如下條件��,那么這個觀測是異常的:
sum(<i=1,q>,yi^2/ai)>kfq^2(b)
另外一個觀察最后幾個主成份的度量是
sum(<i=p-r+1,p>,yi^2/ai)
對于以上的度量���,異常點具有較高的值
PCA用于異常檢測
一些主要的主成份�����,捕獲了普通數據的可變性
最小的主成份對普通數據來說����,應該有的常量值
異常值在最小的主成份中有變異性
使用PCA進行網絡入侵檢測
-對每個時間t,計算主成份
-隨時間����,堆積所有的主成份�,形成一個矩陣
-矩陣的左奇異向量捕獲了正常行為
-對于任意的t,主成份與奇異向量間的角度給出了異常度
基于可視化的技術
使用可視化工具觀察數據
為人工檢查提供數據的替代視圖
更形象地發現異常點
優勢
-圈定一個人
劣勢
-對低維數據表現較好
-對于高維數據��,在聚合或部分視圖中����,異常值也許是不可區分的
-對于實時異常檢測不合適
可視化數據挖掘
檢測電信欺詐
用圖展現電話呼叫模式
用顏色標記出欺騙性的電話呼叫(異常)
上下文異常檢測
檢測上下文異常
重要假設:在一個上下文內的所有正常實例是彼此相似的(在行為屬性方面)�����,然而在同一個上下文中��,異常實例與其它實例不同
常用方法:
-圍繞一個數據實例�����,確定一個上下文(使用上下文屬性的集合)
-確定測試數據在上下文中是否是異常值(使用行為屬性集合)
優勢:
-當在全局視圖下分析時���,可以檢測那些很難發現的異常值
劣勢:
-確定一個好的上下文屬性的集合
-使用上下文屬性確定一個上下文
上下文屬性
上下文屬性為每個實例定義了一個鄰居(上下文)
舉例:
-空間上下文:經度��、緯度
-圖上下文:邊����、權重
-有序上下文:位置����、時間
-輪廓上下文:用戶的人口統計資料
上下文異常檢測技術
減少異常點檢測
-使用上下文屬性的分段數據
-使用行為屬性在每一個上下文中應用一個傳統的離群點異常
-通常��,上下文檢測 不能輕易地分段
利用結構數據
-使用上下文屬性����,從數據中建立模型
-關于它們的上下文�,模型自動地分析數據實例
條件異常檢測
每個數據點表示為[x,y]�,這里的x表示上下文屬性����,y表示行為屬性
nU高斯模型的混合�����,U從上下文數據學習而來
nV高斯模型的混合�����,V從行為數據學習而來
p(Vj|Ui)表示����,當上下文部分由Ui產生時��,行為部分由Vj產生的概率
一個數據實例[x,y]的異常得分:
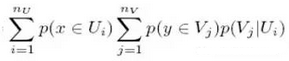
集體異常檢測
檢測集體的異常值
挖掘數據實例間的關系
序列異常檢測
-檢測異常序列
空間異常檢測
-在一個空間數據集中檢測異常子區域
圖的異常檢測
-在圖數據中檢測異常子圖
序列異常檢測
多個子規則
-在序列數據庫中檢測異常序列
-在一個序列中���,檢測異常子序列
提綱
問題陳述
技術
-- 基于核函數的技術
-- 基于窗口的技術
-- 馬爾可夫鏈的技術
實驗評價
-- 實驗方法
-- 數據集
-- 人工數據生成器
-- 結果
結論
動機和問題陳述
用于符號序列的幾個異常檢測技術已經被提出來了
-每個被提出的技術用于一個單獨的應用領域
-對于跨領域的技術沒有比較的評估
-這種評估對于區別技術的相對優劣勢是必要的
問題陳述:給定一個具有n個序列的集合S��,和一個查詢序列Sq���,為Sq找到一個關于S的異常得分
-在S中的序列假設是(或者大部分)正常的
該定義在如下的多領域是適用的
--飛行安全
--系統調用入侵檢測
--蛋白質組���,蛋白質組學
基于核函數的技術
定義序列間的一個相似核函數
--曼哈頓距離-對不同長度的序列不適用
--規范化最長共同序列
應用任何基于傳統距離的異常檢測技術
-CLUSTER
將普通序列聚成一個固定個數的聚類
測試序列的異常得分是與離它最近聚類中心相似性的倒數
-KNN
測試序列的異常得分是在普通序列數據中離它第k個最近鄰居的相似性的倒數
基于窗口的技術(tSTIDE)
從測試序列中抽取有限長度的滑動窗口
對每一個滑動窗口�����,找到它在訓練數據集中的頻率
-對于滑動窗口來說���,頻率代表異常得分的倒數
組合每個窗口異常得分的異常得分����,為測試序列得到全局的異常得分
馬爾可夫鏈的技術
基于之前觀察事件的條件�,估計測試序列的每個事件發概率
組合每個事件的概率獲得全局異常的得分
FSA
--事件概率是基于前L-1事件條件下的概率
--如果前L-1事件沒有訓練數據集中發生�����,該事件將被忽略
FSA-z
和FSA一樣�,只是當前L-1事件未發生在訓練數據中時�����,該事件的概率為0
PST
-如果前L-1事件在訓練集中未發生足夠的次數����,它們將會被最大的suffix替代�����,這里的suffix發生的次數超過了需要的閥值
Ripper
如果前L-1事件在訓練集中未發生足夠的次數�,它將會被最大的subset替代�����,這里的subset發生的次數超過了需要的閥值
HMM
事件的概率�,等于從訓練集的學習生成的HMM中的相應的轉移概率
在線異常檢測
通常數據以流式的方式傳達
應用
--視頻分析
--網絡流量監控
--飛行安全
--信用卡欺詐交易
挑戰
異常需實時檢測
什么時候拒絕���?
什么時候更新��?
-周期性地更新-一段固定的時間周期之后����,模型更新
-插入每條數據記錄��,增量更新
需要增量建模更新技術重要訓練模型�,會很昂貴
-被動更新-模型只有當被需要的時候才會更新
模型更新的動機
如果正在到達的數據點開始創建一個新的數據聚類����,該方法將不能檢測這些點為異常點
增量的LOF和COF
增量LOF算法
-增量的LOF算法為每條插入的數據記錄計算LOF值�����,并且立即決定是否該數據實例是一個異常點
-如果有必要的話��,根據已存在的數據記錄更新LOF值
增量COF算法
-為每個插入的數據記錄計算COF值
-需要的話�,更新ac-dist
分布式異常檢測的必要性
在諸多異常檢測應用中的數據來源不同
-網絡入侵檢測
-信用卡欺詐
-航空安全
同時發生在多位置失敗�,也許僅分析單獨一個位置的數據并不能檢測出來
-在如此復雜的系統中檢測異常也許需要來自于單個位置的檢測異常的信息集成�����,以在一個復雜系統全局水平上檢測異常
用于異常相關和集成的高性能和分布式算法是必要的
分布式異常檢測技術
簡單的數據交換方法
-將數據融合到一個位置
-在分布式的位置間交換數據
分布式的近鄰方法
-每一次距離計算交換一條數據記錄-計算效率低下
-基于跨站點距離計算的隱私保護異常檢測算法
基于模型交換的方法
-探索合適的統計或數據挖掘模型的交換�,以致能描述正?�;虍惓5男袨?
---區別普通行為的模式
---使用統計或數據挖掘學習模型描述這些模式
---跨多位置交換模型�����,在每一個的位置進行組合����,以檢測出全局的異常點
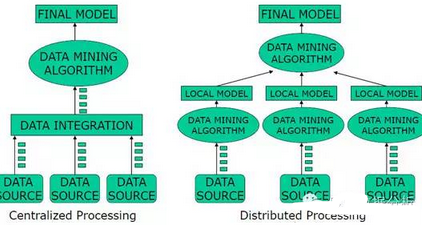
集中式和分布式體系架構
分布式異常檢測算法
參數
-基于分布
-基于圖
-基于深度
非參
-基于密度
-基于聚類
半參
-基于模型(ANN,SVM)
Case Study(案例研究)
略�。
Discussion and Conclusions(討論和結論)
異常檢測能夠在數據中檢測出危急信息(臨界信息)
在多個應用領域非常適用
異常檢測問題的本質依賴于某個應用領域
需要不同的方法來解決一個特定問題的制定
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
