SAS信用評分之模型擬合以及驗證的大坑
今天的內容是來講我這段時間被模型擬合和模型驗證坑過的那些事�。我也是千辛萬苦終于是把模型給建出來了�。此處應該有掌聲����。因為模型老是效果不好這件事��,我躲在被窩里哭了好幾次����。好吧��,講正事�����。
leslie模型擬合
首先����,我們來講下模型擬合的事情�����,其實模型擬合在我這里就是我到底要選擇什么變量進入模型�,我到底應該選擇多少個變量進入模型�����。我之前發過一個循環產出變量組合代碼���,然后算ks值的代碼��。具體鏈接在這里:SAS信用評分之邏輯回歸的變量選擇 現在回頭看有點瞎�,哈哈哈哈哈��。
你可能剛開始200個變量變量輸入proc logistic過程�����,你設置參數 sls=0.05,sle=0.05(SLE:sas中在變量選舉進入的參數�����,SLE(sets criterion for entry into model) 是變量進入模型的標準即統計意義水平值P<0.3���,是定邏輯回歸中變量納入的主要條件��。SLS:sas中在變量選舉進入的參數��,SLS(sets criterion for staying in model)是變量在模型中保留的標準即統計意義水平值P<0.3����,是定邏輯回歸中變量保留的主要條件�。邏輯回歸變量進入后�,因為新的變量進入導致老的變量對整個模型的貢獻不足����,從中移出的閥值�。)0.3是默認條件���。那么卡方檢驗小于0.05的變量都會被篩選出來����。
假設你的領導發話了����,你最終的模型的變量個數要控制在10-14個�,但是這時候可能篩選出來有30幾個����。那么這30幾個你要怎么知道那十幾個組合��,ks很好����,而且達到了要求�,之前有人說用主成分分析�����,主成分分析的理論好像也有這個道理���。但是需要注意的是:
小知識
主成分分析:利用降維(線性變換)的思想����,在損失很少信息的前提下把多個指標轉化為幾個綜合指標(主成分),用綜合指標來解釋多變量的方差- 協方差結構����,即每個主成分都是原始變量的線性組合,且各個主成分之間互不相關,使得主成分比原始變量具有某些更優越的性能(主成分必須保留原始變量90%以上的信息)���,從而達到簡化系統結構�����,抓住問題實質的目的綜合指標即為主成分�。
但是在我腦子存在的邏輯回歸理論是�,邏輯回歸是一個非線性回歸����,自然就推翻了主成分分析來降維的方案�。具體的為什么不可以用主成分分析�����,歡迎大神在留言區給出更具體的解釋�。
我們回到我們那個篩選出來的30幾個變量的問題上��。其實這個方法是一個關注我公眾號的大神告訴我的�,謝謝大神�����。讓我來演示一下代碼����。
Ods Output ParameterEstimates=aa ;
proc logistic data=raw.rong_test12 outest=bb ;
model APPL_STATUS_1(event="1")=
woe_new_industry
woe_new_G_MARITAL_P
woe_new_Q_TLNINE_CNT
woe_new_EDUCATION
woe_new_query_time_n
woe_new_OPERATOR_num_N
woe_new_q_lcc_six
woe_new_a_muser_rate
woe_new_cq_cc_rate
woe_new_o_recently_C
woe_new_q_cc_o
woe_new_q_othree_cnt
woe_new_ACCOUNT_HOUSELOAN
woe_new_c_DELQ_cnt
/selection=score start=14 stop=14 best=10
outROC=ROC_train;
output out=pp
p=pred_status lower=pi_l upper=pi_u ;
run;
其實這個代碼中�,可能你覺得有疑問就是start=14 stop=14 best=10這三個參數是什么意思��。這三個參數的大概的意思就是表達���,我要14個變量�,然后�����,你顯示前十種最好的組合給我����。
小知識
卡方檢驗就是統計樣本的實際觀測值與理論推斷值之間的偏離程度��,實際觀測值與理論推斷值之間的偏離程度就決定卡方值的大小�,卡方值越大�,越不符合�����;卡方值越小�����,偏差越小�����,越趨于符合�,若兩個值完全相等時�,卡方值就為0���,表明理論值完全符合���。

然后代碼跑出來就有“評分卡方”評分的前十個的變量組合�,這時候你要是設定best=20,那就是前20�����。至于這個得分是怎么計算的��,我等級還不夠�����,所以我沒辦法解釋����。Sorry啦���。
那么這10種組合你就可以去挑選�����,符合業務的啊����,或者說ks值比較高的��,或者說你做點其他的檢驗計算���,就看你的領導對于模型的評估啦����。
以上就是模型擬合的內容���,其實還是選擇變量的內容啦��。
leslie模型檢驗
驗證的內容�����。其實驗證同個數據源的測試數據集的測試這個是比較簡單的��,畢竟這批數據是跟你的訓練數據集一起產生的�����。有點麻煩是關于跨期數據的驗證����,這里的跨期的意思�����,是譬如我取得是2015.8-2016.8的數據�����,那么我會用2016.9-2016.10的數據作為跨期數據來驗證下原模型的效果����。
這部分我就沒什么代碼給你們啦��,只是在這里要說一個注意的點�,這也是一個關注我的公眾號的大神告訴我的��。就是在跨期驗證的時候�����,可能效果不是很理想�,但是這時候呢�,你不要急于泄氣�����。
現在我舉一個例子����,說下你大概就懂了���。
跨期驗證某變量的分布:
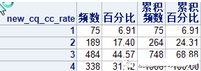
原模型某變量的分布:
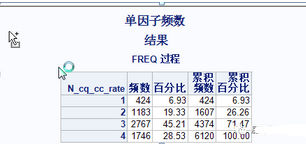
這是一個連續變量在跨期驗證以及原模型中分段的分布��。那么既然分段的壞賬率我們沒辦法控制��,但是需要控制的是���,分段的分布我們還是應該調節到和原來模型的分布是差不多���,所以在生成跨期數據的時候�,需要每個變量都檢查跟原來的分布是不是一致�,假設對于連續變量分布有5%-10%的偏差就建議調節一下分段范圍��,讓分段接近一下原模型的分布���。
假設這個辦法都讓你的模型效果都達到不到領導要求的話���,而且你的變量也是沒辦法怎么衍生����,或者也沒有什么其他變量可以拿來用的話�����。假設在數據量足夠的情況下��,建議可以分成兩部分���,譬如分成男女分開建模��。這種分開建模的方式也只是建議��,還是你要征得領導同意啦��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
