Python做文本挖掘的情感極性分析
「情感極性分析」是對帶有感情色彩的主觀性文本進行分析���、處理�����、歸納和推理的過程��。按照處理文本的類別不同����,可分為基于新聞評論的情感分析和基于產品評論的情感分析��。其中���,前者多用于輿情監控和信息預測�,后者可幫助用戶了解某一產品在大眾心目中的口碑����。目前常見的情感極性分析方法主要是兩種:基于情感詞典的方法和基于機器學習的方法����。
1. 基于情感詞典的文本情感極性分析
筆者是通過情感打分的方式進行文本情感極性判斷�����,score > 0判斷為正向�����,score < 0判斷為負向�。
1.1 數據準備
1.1.1 情感詞典及對應分數
詞典來源于BosonNLP數據下載http://bosonnlp.com/dev/resource 的情感詞典����,來源于社交媒體文本��,所以詞典適用于處理社交媒體的情感分析���。
詞典把所有常用詞都打上了唯一分數有許多不足之處����。
不帶情感色彩的停用詞會影響文本情感打分�����。由于中文的博大精深�����,詞性的多變成為了影響模型準確度的重要原因��。一種情況是同一個詞在不同的語境下可以是代表完全相反的情感意義��,用筆者模型預測偏最大的句子為例(來源于朋友圈文本):
有車一族都用了這個寶貝����,后果很嚴重哦[偷笑][偷笑][偷笑]1�����,交警工資估計會打5折��,沒有超速罰款了[呲牙][呲牙][呲牙]2��,移動聯通公司大幅度裁員���,電話費少了[呲牙][呲牙][呲牙]3���,中石化中石油裁員2成�����,路癡不再迷路�,省油[悠閑][悠閑][悠閑]5�,保險公司裁員2成���,保費折上折2成�����,全國通用[憨笑][憨笑][憨笑]買不買你自己看著辦吧[調皮][調皮][調皮]
里面嚴重等詞都是表達的相反意思�,甚至整句話一起表示相反意思��,不知死活的筆者還沒能深入研究如何用詞典的方法解決這類問題��,但也許可以用機器學習的方法讓神經網絡進行學習能夠初步解決這一問題�����。另外���,同一個詞可作多種詞性����,那么情感分數也不應相同�����,例如:
這部電影真垃圾
垃圾分類
很明顯在第一句中垃圾表現強烈的貶義���,而在第二句中表示中性���,單一評分對于這類問題的分類難免有失偏頗�。
1.1.2 否定詞詞典
否定詞的出現將直接將句子情感轉向相反的方向�,而且通常效用是疊加的���。常見的否定詞:不��、沒�����、無���、非��、莫�����、弗�、勿��、毋�、未����、否�、別����、無��、休��、難道等��。
1.1.3 程度副詞詞典
既是通過打分的方式判斷文本的情感正負��,那么分數絕對值的大小則通常表示情感強弱��。既涉及到程度強弱的問題��,那么程度副詞的引入就是勢在必行的�����。
詞典內數據格式可參考如下格式����,即共兩列����,第一列為程度副詞�,第二列是程度數值���,> 1表示強化情感����,< 1表示弱化情感�。


1.2 數據預處理
1.2.1 分詞
即將句子拆分為詞語集合�����,結果如下:
e.g. 這樣/的/酒店/配/這樣/的/價格/還算/不錯
Python常用的分詞工具(在此筆者使用Jieba進行分詞):結巴分詞 Jieba
Pymmseg-cpp
Loso
smallseg
from collections import defaultdict
import os
import re
import jieba
import codecs
“””
1. 文本切割
“””def sent2word(sentence):
“””
Segment a sentence to words
Delete stopwords
“””
segList = jieba.cut(sentence)
segResult = [] for w in segList:
segResult.append(w)
stopwords = readLines(‘stop_words.txt’)
newSent = [] for word in segResult: if word in stopwords:
continue
else:
newSent.append(word) return newSent
1.2.2 去除停用詞
遍歷所有語料中的所有詞語�����,刪除其中的停用詞
e.g. 這樣/的/酒店/配/這樣/的/價格/還算/不錯–> 酒店/配/價格/還算/不錯
1.3 構建模型
1.3.1 將詞語分類并記錄其位置
將句子中各類詞分別存儲并標注位置����。
“””2. 情感定位”””
def classifyWords(wordDict): # (1) 情感詞
senList = readLines(‘BosonNLP_sentiment_score.txt’) senDict = defaultdict()
for s in senList:
senDict[s.split(‘ ‘)[0]] = s.split(‘ ‘)[1] # (2) 否定詞
notList = readLines(‘notDict.txt’) # (3) 程度副詞 degreeList = readLines(‘degreeDict.txt’)
degreeDict = defaultdict()
for d in degreeList:
degreeDict[d.split(‘,’)[0]] = d.split(‘,’)[1]
senWord = defaultdict()
notWord = defaultdict()
degreeWord = defaultdict()
for word in wordDict.keys():
if word in senDict.keys() and word not in notList and word not in degreeDict.keys():
senWord[wordDict[word]] = senDict[word]
elif word in notList and word not in degreeDict.keys(): notWord[wordDict[word]] = -1
elif word in degreeDict.keys(): degreeWord[wordDict[word]] = degreeDict[word]
return senWord, notWord, degreeWord
1.3.2 計算句子得分
在此�,簡化的情感分數計算邏輯:所有情感詞語組的分數之和.
定義一個情感詞語組:兩情感詞之間的所有否定詞和程度副詞與這兩情感詞中的后一情感詞構成一個情感詞組��,即notWords
+ degreeWords + sentiWords���,例如不是很交好��,其中不是為否定詞���,為程度副詞����,交好為情感詞�����,那么這個情感詞語組的分數為:
finalSentiScore = (-1) ^ 1 * 1.25 * 0.747127733968
其中1指的是一個否定詞���,1.25是程度副詞的數值��,0.747127733968為交好的情感分數���。
“””3. 情感聚合”””
def scoreSent(senWord, notWord, degreeWord, segResult):
W = 1 score = 0 # 存所有情感詞的位置的列表 senLoc = senWord.keys()
notLoc = notWord.keys()
degreeLoc = degreeWord.keys()
senloc = -1 # notloc = -1 # degreeloc = -1
# 遍歷句中所有單詞segResult�,i為單詞絕對位置
for i in range(0, len(segResult)):
# 如果該詞為情感詞
if i in senLoc: # loc為情感詞位置列表的序號 senloc += 1 # 直接添加該情感詞分數 score += W * float(senWord[i])
# print “score = %f” % score
if senloc < len(senLoc) – 1:
# 判斷該情感詞與下一情感詞之間是否有否定詞或程度副詞 # j為絕對位置
for j in range(senLoc[senloc], senLoc[senloc + 1]): # 如果有否定詞
if j in notLoc:
W *= -1 # 如果有程度副詞
elif j in degreeLoc:
W *= float(degreeWord[j])
# i定位至下一個情感詞
if senloc < len(senLoc) – 1:
i = senLoc[senloc + 1]
return score
1.4 模型評價
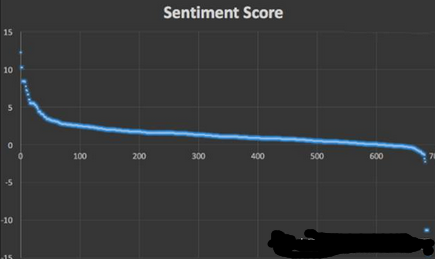
其中大多數文本被判為正向文本符合實際情況����,且絕大多數文本的情感得分的絕對值在10以內��,這是因為筆者在計算一個文本的情感得分時����,以句號作為一句話結束的標志��,在一句話內����,情感詞語組的分數累加��,如若一個文本中含有多句話時���,則取其所有句子情感得分的平均值�。然而����,這個模型的缺點與局限性也非常明顯:
首先�����,段落的得分是其所有句子得分的平均值�,這一方法并不符合實際情況�。正如文章中先后段落有重要性大小之分���,一個段落中前后句子也同樣有重要性的差異�����。
其次���,有一類文本使用貶義詞來表示正向意義��,這類情況常出現與宣傳文本中�,還是那個例子:
有車一族都用了這個寶貝����,后果很嚴重哦[偷笑][偷笑][偷笑]1�����,交警工資估計會打5折��,沒有超速罰款了[呲牙][呲牙][呲牙]2��,移動聯通公司大幅度裁員�����,電話費少了[呲牙][呲牙][呲牙]3��,中石化中石油裁員2成���,路癡不再迷路�,省油[悠閑][悠閑][悠閑]5���,保險公司裁員2成�����,保費折上折2成����,全國通用[憨笑][憨笑][憨笑]買不買你自己看著辦吧[調皮][調皮][調皮]2980元軒轅魔鏡帶回家����,推廣還有返利[得意]
Score Distribution中得分小于-10的幾個文本都是與這類情況相似��,這也許需要深度學習的方法才能有效解決這類問題�,普通機器學習方法也是很難的�����。
對于正負向文本的判斷���,該算法忽略了很多其他的否定詞��、程度副詞和情感詞搭配的情況��;用于判斷情感強弱也過于簡單�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
