Hadoop之HDFS與小文件
Hadoop有一個名為“HDFS”的分布式文件系統�����,它的設計目的是提供一個高容錯���,且能部署在廉價硬件的分布式系統�;它的設計參照了Google的GFS(Google分布式文件系統)���;它能支持高吞吐量�,適合大規模數據集應用����。
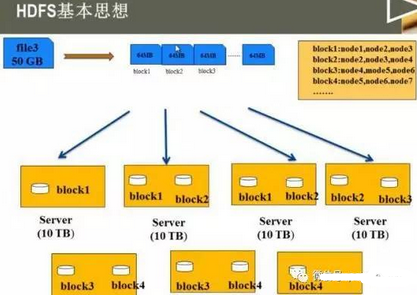
HDFS上的文件被劃分為以固定塊大小的多個分塊(默認為64MB����,如此大是為了最小化尋址開銷)����,每個塊作一個獨立的存儲單元�����。
這樣做有兩個好處:第一可以存儲容量大于單一磁盤容量的文件����;第二大大簡化了存儲子系統的設計(只需要管理塊����,而且塊的元數據并不需要與塊一同存儲)��。將每個塊復制到少數幾個獨立的機器上(默認為3個)�����,可以確保在塊�����、磁盤或機器發生故障后數據不會丟失(即發現一個塊不可用��,系統會從其他地方讀取另一個復本���,同時重新復制該復本到一臺正常的機器上)��。下圖展示了這些特性�����。
HDFS集群由一個NameNode(管理者)和多個dataNode(工作者)組成���。HDFS解決了單點問題����,HDFS集群的管理者是非常重要���。NameNode管理文件系統的命名空間�,它維護著文件系統樹及整顆樹內所有的文件和目錄���,同時也記錄著每個文件中各個塊到DataNode���。同時��,NameNode(管理者)包含主要節點(Primary)和備份節點(Stand by)���,如果Primary出現問題���,Stand By可自動接替Primary繼續工作��。DataNode主要負責響應文件系統客戶端發出的讀寫請求����,同時還將在NameNode的指導下負責執行文件的創建�、刪除以及復制�����。
Hadoop的MapReduce(分布式計算模型)處理框架正是基于HDFS構建����,它充分利用集群的并行優勢來處理存儲在HDFS上的數據文件�。一個MapReduce任務在集群上以任務跟蹤(TaskTracker)執行�����。每個TaskTracker被Job監控���,當發現一個TaskTracker執行失敗是�,JobTracker就會將該任務分配到其他機器上運行�����。
在運行MapReduce作業經常會遇到各種問題�����,為了能進行必要的優化���,理解HDFS原理還是很有必要的���。下面介紹比較常見的一種情況:小文件如何拖累MapReduce作業及可采取的優化措施�。
在MapReduce作業中�,Hadoop將其輸入數據劃分成等長的小數據塊�����,稱為輸入分片�����。Hadoop為每個分片構建一個map任務�,或者說每一個map操作只處理一個輸入分片��。每個分片被劃分為若干個記錄�����,每條記錄就是一個鍵值對����,map一個接一個地處理記錄���。輸入分片包括自己的大小和存儲位置��,存儲位置供MapReduce系統將map任務盡量放在分片附近��,分片大小用于排序分片�����,以便優先處理最大的分片�,從而最小化作業運行時間���。
在一般的MapReduce作業中��,使用最多的輸入數據格式通常是存儲在HDFS上的文件����。Hadoop自帶的FileInputFormat類是所有使用文件作為其數據源實現的基類����。它提供兩個功能:一個用于指出作業的輸入文件位置�����;一個是輸入文件生成分片的實現代碼段�。
一個文件如果大于HDFS的塊大小�����,那么它會被分割成多個塊���,存儲在不同的位置����。如果分片的大小大于HDFS的塊大小�����,那么一個分片就會從不同位置讀取�,需要通過網絡傳輸到map任務節點���,與使用本地數據運行整個map任務相比�,這種方法效率更低�。另一方面�����,如果分片切分得太小���,那么管理分片的總時間和構建map任務的總時間將決定作業的整個執行時間�����。因此�����,對于大多數作業來說��,一個合理的分片大小趨向于HDFS的一個塊的大小�,即64MB����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
