Python 近幾年在數據科學行業獲得了人們的極大青睞���,各種資源也層出不窮�����。數據科學解決方案公司 ActiveWizards 近日根據他們自己的應用開發經驗�,總結了數據科學家和工程師將在 2017 年最常使用的 Python 庫���。
核心庫
1)NumPy
地址:http://www.numpy.org
當使用 Python 開始處理科學任務時��,不可避免地需要求助 Python 的 SciPy Stack�,它是專門為 Python 中的科學計算而設計的軟件的集合(不要與 SciPy 混淆�,它只是這個 stack 的一部分�,以及圍繞這個 stack 的社區)���。這個 stack 相當龐大�����,其中有十幾個庫���,所以我們想聚焦在核心包上(特別是最重要的)��。
NumPy(代表 Numerical Python)是構建科學計算 stack 的最基礎的包��。它為 Python 中的 n 維數組和矩陣的操作提供了大量有用的功能�。該庫還提供了 NumPy 數組類型的數學運算向量化�,可以提升性能���,從而加快執行速度����。
2)SciPy
地址:https://www.scipy.org
SciPy 是一個工程和科學軟件庫��。除此以外���,你還要了解 SciPy Stack 和 SciPy 庫之間的區別�����。SciPy 包含線性代數��、優化����、集成和統計的模塊���。SciPy 庫的主要功能建立在 NumPy 的基礎之上��,因此它的數組大量使用了 NumPy����。它通過其特定的子模塊提供高效的數值例程操作��,比如數值積分����、優化和許多其他例程����。SciPy 的所有子模塊中的函數都有詳細的文檔�����,這也是一個優勢�。
3)Pandas
地址:http://pandas.pydata.org
Pandas 是一個 Python 包��,旨在通過「標記(labeled)」和「關系(relational)」數據進行工作��,簡單直觀�����。Pandas 是 data wrangling 的完美工具�。它設計用于快速簡單的數據操作�、聚合和可視化���。庫中有兩個主要的數據結構:
 Series:一維
Series:一維
 Data Frames:二維
例如�,當你要從這兩種類型的結構中接收到一個新的「Dataframe」類型的數據時����,你將通過傳遞一個「Series」來將一行添加到「Dataframe」中來接收這樣的 Dataframe:
Data Frames:二維
例如�,當你要從這兩種類型的結構中接收到一個新的「Dataframe」類型的數據時����,你將通過傳遞一個「Series」來將一行添加到「Dataframe」中來接收這樣的 Dataframe:
 這里只是一小撮你可以用 Pandas 做的事情:
· 輕松刪除并添加「Dataframe」中的列
· 將數據結構轉換為「Dataframe」對象
· 處理丟失數據�����,表示為 NaN(Not a Number)
· 功能強大的分組
可視化
4)Matplotlib
地址:https://matplotlib.org
Matplotlib 是另一個 SciPy Stack 核心軟件包和另一個 Python 庫����,專為輕松生成簡單而強大的可視化而量身定制�����。它是一個頂尖的軟件�����,使得 Python(在 NumPy���、SciPy 和 Pandas 的幫助下)成為 MatLab 或 Mathematica 等科學工具的顯著競爭對手����。然而��,這個庫比較底層��,這意味著你需要編寫更多的代碼才能達到高級的可視化效果�����,通常會比使用更高級工具付出更多努力��,但總的來說值得一試�����?����;ㄒ稽c力氣�����,你就可以做到任何可視化:
· 線圖
· 散點圖
· 條形圖和直方圖
· 餅狀圖
· 莖圖
· 輪廓圖
· 場圖
· 頻譜圖
還有使用 Matplotlib 創建標簽�、網格��、圖例和許多其他格式化實體的功能��?����;旧?,一切都是可定制的��。
該庫支持不同的平臺�����,并可使用不同的 GUI 工具套件來描述所得到的可視化��。許多不同的 IDE(如 IPython)都支持 Matplotlib 的功能���。
還有一些額外的庫可以使可視化變得更加容易�。
這里只是一小撮你可以用 Pandas 做的事情:
· 輕松刪除并添加「Dataframe」中的列
· 將數據結構轉換為「Dataframe」對象
· 處理丟失數據�����,表示為 NaN(Not a Number)
· 功能強大的分組
可視化
4)Matplotlib
地址:https://matplotlib.org
Matplotlib 是另一個 SciPy Stack 核心軟件包和另一個 Python 庫����,專為輕松生成簡單而強大的可視化而量身定制�����。它是一個頂尖的軟件�����,使得 Python(在 NumPy���、SciPy 和 Pandas 的幫助下)成為 MatLab 或 Mathematica 等科學工具的顯著競爭對手����。然而��,這個庫比較底層��,這意味著你需要編寫更多的代碼才能達到高級的可視化效果�����,通常會比使用更高級工具付出更多努力��,但總的來說值得一試�����?����;ㄒ稽c力氣�����,你就可以做到任何可視化:
· 線圖
· 散點圖
· 條形圖和直方圖
· 餅狀圖
· 莖圖
· 輪廓圖
· 場圖
· 頻譜圖
還有使用 Matplotlib 創建標簽�、網格��、圖例和許多其他格式化實體的功能��?����;旧?,一切都是可定制的��。
該庫支持不同的平臺�����,并可使用不同的 GUI 工具套件來描述所得到的可視化��。許多不同的 IDE(如 IPython)都支持 Matplotlib 的功能���。
還有一些額外的庫可以使可視化變得更加容易�。
 5)Seaborn
地址:https://seaborn.pydata.org
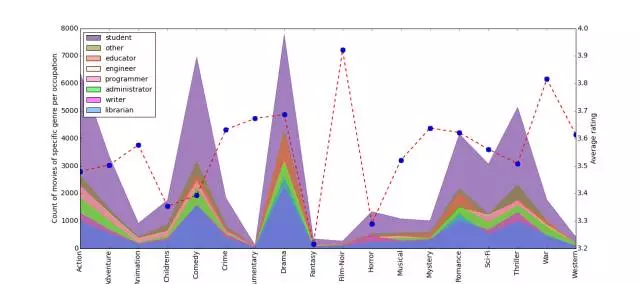
Seaborn 主要關注統計模型的可視化���;這種可視化包括熱度圖(heat map)�,可以總結數據但也描繪總體分布���。Seaborn 基于 Matplotlib�,并高度依賴于它�。
5)Seaborn
地址:https://seaborn.pydata.org
Seaborn 主要關注統計模型的可視化���;這種可視化包括熱度圖(heat map)�,可以總結數據但也描繪總體分布���。Seaborn 基于 Matplotlib�,并高度依賴于它�。
 6)Bokeh
地址:http://bokeh.pydata.org
Bokeh 也是一個很好的可視化庫��,其目的是交互式可視化����。與之前的庫相反�����,這個庫獨立于 Matplotlib�。正如我們已經提到的那樣����,Bokeh 的重點是交互性�����,它通過現代瀏覽器以數據驅動文檔(d3.js)的風格呈現���。
6)Bokeh
地址:http://bokeh.pydata.org
Bokeh 也是一個很好的可視化庫��,其目的是交互式可視化����。與之前的庫相反�����,這個庫獨立于 Matplotlib�。正如我們已經提到的那樣����,Bokeh 的重點是交互性�����,它通過現代瀏覽器以數據驅動文檔(d3.js)的風格呈現���。
 7)Plotly
地址:https://plot.ly
最后談談 Plotly���。它是一個基于 Web 的工具箱��,用于構建可視化�,將 API 呈現給某些編程語言(其中包括 Python)����。在 plot.ly 網站上有一些強大的�����、開箱即用的圖形��。為了使用 Plotly����,你需要設置你的 API 密鑰���。圖形處理會放在服務器端�,并在互聯網上發布��,但也有一種方法可以避免這么做��。
7)Plotly
地址:https://plot.ly
最后談談 Plotly���。它是一個基于 Web 的工具箱��,用于構建可視化�,將 API 呈現給某些編程語言(其中包括 Python)����。在 plot.ly 網站上有一些強大的�����、開箱即用的圖形��。為了使用 Plotly����,你需要設置你的 API 密鑰���。圖形處理會放在服務器端�,并在互聯網上發布��,但也有一種方法可以避免這么做��。
 機器學習
8)SciKit-Learn
地址:http://scikit-learn.org
Scikits 是 SciPy Stack 的附加軟件包���,專為特定功能(如圖像處理和輔助機器學習)而設計���。在后者方面��,其中最突出的一個是 scikit-learn�����。該軟件包構建于 SciPy 之上�,并大量使用其數學操作�。
scikit-learn 有一個簡潔和一致的接口�����,可利用常見的機器學習算法�����,讓我們可以簡單地在生產中應用機器學習����。該庫結合了質量很好的代碼和良好的文檔�,易于使用且有著非常高的性能����,是使用 Python 進行機器學習的實際上的行業標準����。
深度學習:Keras / TensorFlow / Theano
在深度學習方面���,Python 中最突出和最方便的庫之一是 Keras��,它可以在 TensorFlow 或者 Theano 之上運行�����。讓我們來看一下它們的一些細節�����。
9)Theano
地址:https://github.com/Theano
首先����,讓我們談談 Theano��。Theano 是一個 Python 包����,它定義了與 NumPy 類似的多維數組��,以及數學運算和表達式���。該庫是經過編譯的����,使其在所有架構上能夠高效運行�。這個庫最初由蒙特利爾大學機器學習組開發�,主要是為了滿足機器學習的需求�。
要注意的是�����,Theano 與 NumPy 在底層的操作上緊密集成���。該庫還優化了 GPU 和 CPU 的使用���,使數據密集型計算的性能更快��。
效率和穩定性調整允許更精確的結果��,即使是非常小的值也可以��,例如���,即使 x 很小���,log(1+x) 也能得到很好的結果��。
10)TensorFlow
地址:https://www.tensorflow.org
TensorFlow 來自 Google 的開發人員����,它是用于數據流圖計算的開源庫�����,專門為機器學習設計��。它是為滿足 Google 對訓練神經網絡的高要求而設計的�����,是基于神經網絡的機器學習系統 DistBelief 的繼任者����。然而�,TensorFlow 并不是谷歌的科學專用的——它也足以支持許多真實世界的應用��。
TensorFlow 的關鍵特征是其多層節點系統����,可以在大型數據集上快速訓練人工神經網絡���。這為 Google 的語音識別和圖像識別提供了支持��。
11)Keras
地址:https://keras.io
最后�����,我們來看看 Keras�����。它是一個使用高層接口構建神經網絡的開源庫�����,它是用 Python 編寫的����。它簡單易懂�����,具有高級可擴展性����。它使用 Theano 或 TensorFlow 作為后端�,但 Microsoft 現在已將 CNTK(Microsoft 的認知工具包)集成為新的后端�。
其簡約的設計旨在通過建立緊湊型系統進行快速和容易的實驗���。
Keras 極其容易上手��,而且可以進行快速的原型設計���。它完全使用 Python 編寫的�����,所以本質上很高層��。它是高度模塊化和可擴展的��。盡管它簡單易用且面向高層��,但 Keras 也非常深度和強大���,足以用于嚴肅的建模�。
Keras 的一般思想是基于神經網絡的層���,然后圍繞層構建一切�����。數據以張量的形式進行準備����,第一層負責輸入張量�,最后一層用于輸出����。模型構建于兩者之間����。
自然語言處理
12)NLTK
地址:http://www.nltk.org
這套庫的名稱是 Natural Language Toolkit(自然語言工具包)�����,顧名思義���,它可用于符號和統計自然語言處理的常見任務�。NLTK 旨在促進 NLP 及相關領域(語言學�����、認知科學和人工智能等)的教學和研究��,目前正被重點關注�����。
NLTK 允許許多操作�����,例如文本標記���、分類和 tokenizing����、命名實體識別��、建立語語料庫樹(揭示句子間和句子內的依存性)����、詞干提取���、語義推理�����。所有的構建塊都可以為不同的任務構建復雜的研究系統�����,例如情緒分析�����、自動摘要�����。
13)Gensim
地址:http://radimrehurek.com/gensim
這是一個用于 Python 的開源庫���,實現了用于向量空間建模和主題建模的工具���。這個庫為大文本進行了有效的設計��,而不僅僅可以處理內存中內容�����。其通過廣泛使用 NumPy 數據結構和 SciPy 操作而實現了效率����。它既高效又易于使用����。
Gensim 的目標是可以應用原始的和非結構化的數字文本�。Gensim 實現了諸如分層 Dirichlet 進程(HDP)����、潛在語義分析(LSA)和潛在 Dirichlet 分配(LDA)等算法�,還有 tf-idf�����、隨機投影�����、word2vec 和 document2vec�,以便于檢查一組文檔(通常稱為語料庫)中文本的重復模式����。所有這些算法是無監督的——不需要任何參數�����,唯一的輸入是語料庫�。
數據挖掘與統計
14)Scrapy
地址:https://scrapy.org
Scrapy 是用于從網絡檢索結構化數據(如聯系人信息或 URL)的爬蟲程序(也稱為 spider bots)的庫���。它是開源的���,用 Python 編寫����。它最初是為 scraping 設計的�,正如其名字所示的那樣��,但它現在已經發展成了一個完整的框架���,可以從 API 收集數據���,也可以用作通用的爬蟲���。
該庫在接口設計上遵循著名的 Don』t Repeat Yourself 原則——提醒用戶編寫通用的可復用的代碼�����,因此可以用來開發和擴展大型爬蟲�����。
Scrapy 的架構圍繞 Spider 類構建����,該類包含了一套爬蟲所遵循的指令��。
15)Statsmodels
地址:http://www.statsmodels.org
statsmodels 是一個用于 Python 的庫���,正如你可能從名稱中猜出的那樣����,其讓用戶能夠通過使用各種統計模型估計方法以及執行統計斷言和分析來進行數據探索�。
許多有用的特征是描述性的����,并可通過使用線性回歸模型��、廣義線性模型��、離散選擇模型����、穩健的線性模型���、時序分析模型�����、各種估計器進行統計�。
該庫還提供了廣泛的繪圖函數����,專門用于統計分析和調整使用大數據統計數據的良好性能���。
結論
這個列表中的庫被很多數據科學家和工程師認為是最頂級的�,了解和熟悉它們是很有價值的�����。這里有這些庫在 GitHub 上活動的詳細統計:
機器學習
8)SciKit-Learn
地址:http://scikit-learn.org
Scikits 是 SciPy Stack 的附加軟件包���,專為特定功能(如圖像處理和輔助機器學習)而設計���。在后者方面��,其中最突出的一個是 scikit-learn�����。該軟件包構建于 SciPy 之上�,并大量使用其數學操作�。
scikit-learn 有一個簡潔和一致的接口�����,可利用常見的機器學習算法�����,讓我們可以簡單地在生產中應用機器學習����。該庫結合了質量很好的代碼和良好的文檔�,易于使用且有著非常高的性能����,是使用 Python 進行機器學習的實際上的行業標準����。
深度學習:Keras / TensorFlow / Theano
在深度學習方面���,Python 中最突出和最方便的庫之一是 Keras��,它可以在 TensorFlow 或者 Theano 之上運行�����。讓我們來看一下它們的一些細節�����。
9)Theano
地址:https://github.com/Theano
首先����,讓我們談談 Theano��。Theano 是一個 Python 包����,它定義了與 NumPy 類似的多維數組��,以及數學運算和表達式���。該庫是經過編譯的����,使其在所有架構上能夠高效運行�。這個庫最初由蒙特利爾大學機器學習組開發�,主要是為了滿足機器學習的需求�。
要注意的是�����,Theano 與 NumPy 在底層的操作上緊密集成���。該庫還優化了 GPU 和 CPU 的使用���,使數據密集型計算的性能更快��。
效率和穩定性調整允許更精確的結果��,即使是非常小的值也可以��,例如���,即使 x 很小���,log(1+x) 也能得到很好的結果��。
10)TensorFlow
地址:https://www.tensorflow.org
TensorFlow 來自 Google 的開發人員����,它是用于數據流圖計算的開源庫�����,專門為機器學習設計��。它是為滿足 Google 對訓練神經網絡的高要求而設計的�����,是基于神經網絡的機器學習系統 DistBelief 的繼任者����。然而�,TensorFlow 并不是谷歌的科學專用的——它也足以支持許多真實世界的應用��。
TensorFlow 的關鍵特征是其多層節點系統����,可以在大型數據集上快速訓練人工神經網絡���。這為 Google 的語音識別和圖像識別提供了支持��。
11)Keras
地址:https://keras.io
最后�����,我們來看看 Keras�����。它是一個使用高層接口構建神經網絡的開源庫�����,它是用 Python 編寫的����。它簡單易懂�����,具有高級可擴展性����。它使用 Theano 或 TensorFlow 作為后端�,但 Microsoft 現在已將 CNTK(Microsoft 的認知工具包)集成為新的后端�。
其簡約的設計旨在通過建立緊湊型系統進行快速和容易的實驗���。
Keras 極其容易上手��,而且可以進行快速的原型設計���。它完全使用 Python 編寫的�����,所以本質上很高層��。它是高度模塊化和可擴展的��。盡管它簡單易用且面向高層��,但 Keras 也非常深度和強大���,足以用于嚴肅的建模�。
Keras 的一般思想是基于神經網絡的層���,然后圍繞層構建一切�����。數據以張量的形式進行準備����,第一層負責輸入張量�,最后一層用于輸出����。模型構建于兩者之間����。
自然語言處理
12)NLTK
地址:http://www.nltk.org
這套庫的名稱是 Natural Language Toolkit(自然語言工具包)�����,顧名思義���,它可用于符號和統計自然語言處理的常見任務�。NLTK 旨在促進 NLP 及相關領域(語言學�����、認知科學和人工智能等)的教學和研究��,目前正被重點關注�����。
NLTK 允許許多操作�����,例如文本標記���、分類和 tokenizing����、命名實體識別��、建立語語料庫樹(揭示句子間和句子內的依存性)����、詞干提取���、語義推理�����。所有的構建塊都可以為不同的任務構建復雜的研究系統�����,例如情緒分析�����、自動摘要�����。
13)Gensim
地址:http://radimrehurek.com/gensim
這是一個用于 Python 的開源庫���,實現了用于向量空間建模和主題建模的工具���。這個庫為大文本進行了有效的設計��,而不僅僅可以處理內存中內容�����。其通過廣泛使用 NumPy 數據結構和 SciPy 操作而實現了效率����。它既高效又易于使用����。
Gensim 的目標是可以應用原始的和非結構化的數字文本�。Gensim 實現了諸如分層 Dirichlet 進程(HDP)����、潛在語義分析(LSA)和潛在 Dirichlet 分配(LDA)等算法�,還有 tf-idf�����、隨機投影�����、word2vec 和 document2vec�,以便于檢查一組文檔(通常稱為語料庫)中文本的重復模式����。所有這些算法是無監督的——不需要任何參數�����,唯一的輸入是語料庫�。
數據挖掘與統計
14)Scrapy
地址:https://scrapy.org
Scrapy 是用于從網絡檢索結構化數據(如聯系人信息或 URL)的爬蟲程序(也稱為 spider bots)的庫���。它是開源的���,用 Python 編寫����。它最初是為 scraping 設計的�,正如其名字所示的那樣��,但它現在已經發展成了一個完整的框架���,可以從 API 收集數據���,也可以用作通用的爬蟲���。
該庫在接口設計上遵循著名的 Don』t Repeat Yourself 原則——提醒用戶編寫通用的可復用的代碼�����,因此可以用來開發和擴展大型爬蟲�����。
Scrapy 的架構圍繞 Spider 類構建����,該類包含了一套爬蟲所遵循的指令��。
15)Statsmodels
地址:http://www.statsmodels.org
statsmodels 是一個用于 Python 的庫���,正如你可能從名稱中猜出的那樣����,其讓用戶能夠通過使用各種統計模型估計方法以及執行統計斷言和分析來進行數據探索�。
許多有用的特征是描述性的����,并可通過使用線性回歸模型��、廣義線性模型��、離散選擇模型����、穩健的線性模型���、時序分析模型�����、各種估計器進行統計�。
該庫還提供了廣泛的繪圖函數����,專門用于統計分析和調整使用大數據統計數據的良好性能���。
結論
這個列表中的庫被很多數據科學家和工程師認為是最頂級的�,了解和熟悉它們是很有價值的�����。這里有這些庫在 GitHub 上活動的詳細統計:
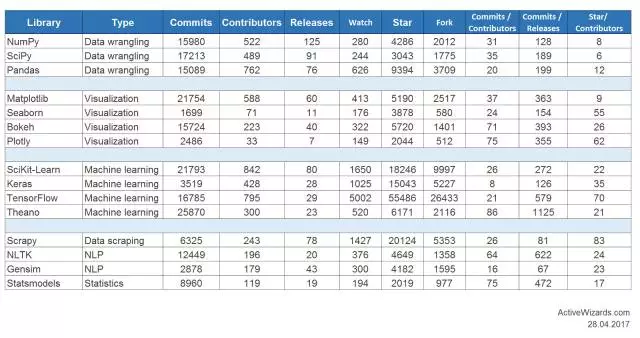 當然�����,這并不是一份完全詳盡的列表�����,還有其它很多值得關注的庫�、工具包和框架�����。比如說用于特定任務的 SciKit 包��,其中包括用于圖像的 SciKit-Image�。如果你也有好想法�����,不妨與我們分享��。
當然�����,這并不是一份完全詳盡的列表�����,還有其它很多值得關注的庫�、工具包和框架�����。比如說用于特定任務的 SciKit 包��,其中包括用于圖像的 SciKit-Image�。如果你也有好想法�����,不妨與我們分享��。
原文鏈接:https://medium.com/activewizards-machine-learning-company/top-15-python-libraries-for-data-science-in-in-2017-ab61b4f9b4a7
作者 Igor Bobriakov
編譯 機器之心 朱朝陽����、吳攀
本文轉自機器之心����,轉載需授權
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
