使用 IBM SPSS Modeler 進行數據挖掘之數據理解
在數據挖掘項目中��,數據理解常常不被重視����。但其實數據理解在整個數據挖掘項目中扮演著非常重要的角色���,可以說是整個項目的基石�����。在計算機領域有一句話�,“Garbage
in���,garbage out.”
意思就是說����,如果你的輸入數據沒有經過科學的預處理����,你所得到的結果必將是錯誤的����。通過數據理解���,我們可以理解數據的特性和不足����,進而對數據進行預處理��,使得將來得到的模型更加穩定和精確�����。其次通過理解數據項之間的關系����,我們可以為建模時輸入數據項和模型的選擇提供重要的信息���。
首先�,我們需要了解 CRISP-DM 模型����,從而了解數據理解在數據挖掘工作的位置和作用���。接著我們利用一個例子���,分三個章節來介紹如何利用 Modeler 來理解和處理原始數據中的缺失值��,異常值和各個數據項之間的內在關系���。
CRISP-DM 模型
數據挖掘是一項復雜的工程��,為了讓整個項目便于控制和管理����,我們必須遵從一定的標準流程��。而 CRISP-DM 模型就是數據挖掘業界比較流行的一種模型�����。
圖 1. CRISP-DM 模型圖
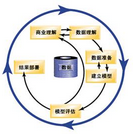
CRISP-DM����,即跨行業數據挖掘標準流程���,這是一種業界認可的用于指導數據挖掘工作的方法��。作為一種方法�,它包含工程中各個典型階段的說明�、每個階段所包含的任務以及這些任務之間的關系的說明����;作為一種流程模型���,CRISP-DM
概述了數據挖掘的生命周期�����。圖 1 展示了 CRISP-DM 中定義的數據挖掘生命周期中的六個階段����。
商業理解:了解進行數據挖掘的業務原因和數據挖掘的目標
數據理解:深入了解可用于挖掘的數據
數據準備:對待挖掘數據進行合并���,匯總�����,排序���,樣本選取等操作
建立模型:根據前期準備的數據選取合適的模型
模型評估:使用在商業理解階段設立的業務成功標準對模型進行評估
結果部署:使用挖掘后的結果提升業務的過程
下面���,我們以某超市的市場推廣活動為例�,從商業理解開始�,一起來學習如何利用 Modeler 的強大功能來進行數據理解�����。
商業理解:
現狀:
某超市新增加了體育服飾用品營業部����。開業一段時間���,由于體育服飾用品地處二樓����,很多顧客還不知道��,營業額沒有達到預期�。
商業目標:
經理決定進行一次促銷活動�,具體活動是向會員中的部分用戶郵寄打折優惠卡���?����?紤]到優惠卡制作費用�����,郵寄費用�,經理希望能夠向那些最有購買潛力的客戶郵寄優惠卡���。使這些潛在用戶了解本超市的體育品牌和刺激他們進行消費���。
活動計劃:
首先調取自體育用品部營業來的所有銷售記錄�����,得到購買體育用品的會員記錄��,建立模型����,對本超市所有會員進行預測���,對那些最有可能購買體育用品且尚未購買的客戶郵寄優惠卡�。以刺激這些潛在客戶的消費��。
驗證條件:
產生潛在客戶名單信息后�����,隨機抽取 100 名進行電話調查���,表示愿意接受優惠券并且表示會來消費的顧客比例高于 70%.
數據理解
經理將這個任務交給小王來負責�,小王首先對超市內現有的數據進行分析:
會員基本信息:會員申請會員卡時登記的信息��,其中包含了會員年齡�����,職業����,學歷����,電話�����,工作���,收入����,住址等信息���。
消費信息:會員消費的明細記錄���。
了解了現有數據后�����,小王發現有以下問題:
會員基本信息是會員提供的�,里邊有很多值是缺失的�,有的看起來是錯誤的��。
而消費信息由于是每次消費后電腦生成���,信息是完整的�,但是信息卻很龐雜�,不利于分析��。
可用的數據項非常多���,到底用哪些數據項來進行數據預測呢��?
這幾個問題都是數據理解需要解決的問題�����,下邊我們就來看一下如何利用 Modeler 來幫助我們進行數據理解:
使用 Modeler 進行缺失值分析
什么是缺失值����?
缺失值就是指數據文件中的某些數據項是未知的值�。幾乎所有的商業數據挖掘中�����,都要遇到缺失值的問題�����,有可能是數據采集中的失誤���,有可能客戶不愿意提供某些信息���,面對這樣的數據����,我們該如何是好
? 使用這樣的數據可能會對我們后期的建模產生不可預料的影響���。如果丟棄���,這些數據中可能包含著寶貴的信息���。下邊我們就來看一下如何利用
Modeler 來進行缺失值分析:
缺失值示例
第一步我們需要利用 Modeler 來確定數據文件中缺失值的類型和數量��。然后才能做進一步的處理�����。
首先我們看一下我們例子中需要用到的數據:
圖 2. 缺失值分析示例數據

從上圖中我們可以看到編號有些記錄的值是缺失的�。
接下來我們打開 Modeler�,新建 Stream�,拖入一個“可變文件”節點到工作區�。雙擊節點���。選擇示例數據文件作為輸入���。然后我們點擊“可變文件”節點的預覽按鈕����。得到結果如圖:
圖 3. 原始數據預覽圖
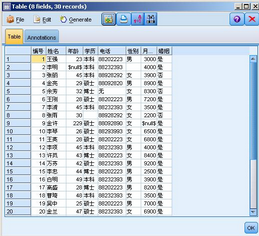
從預覽圖里我們可以看出記錄 002 的年齡為 null����,性別為空 , 這兩個值都可以被 Modeler 自動識別為缺失值�。這是 Modeler
針對不同類型的數據做了不同的處理�����。這里年齡被 Modeler 識別為整數類型���,性別被識別為字符串類型��。另外我們發現 005
的電話號碼依然為“無”�,并沒有做任何替換�。著我們這個示例里電話號碼“無”是一個語義上的缺失值���,在很多數據文件中都可能含有這樣的信息����,那么在
Modeler 里怎么定義這樣的缺失值呢���?這個我們稍后會做介紹�����。
利用“數據審核”節點審核數據
“數據審核”節點可以提供給我們很多有用的信息��,其中就包括數據缺失值信息��。下邊�,我們就將“數據審核”節點加入到我們的 stream 中來��,連接“可變文件”節點和“數據審核”節點���,運行 Stream���,我們可以得到下圖
圖 4. 數據審核結果圖
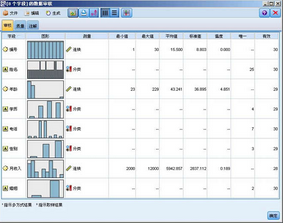
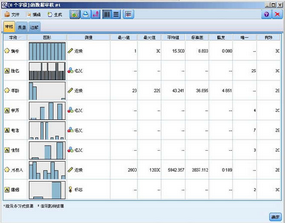
從上圖中我們可以看到很多有用的信息��,數據的分布圖形�����,數據的類型��,統計值等����,在這里我們要關注的是最后一列有效數據���,這里我們發現年齡���,性別��,學歷��,月收入的有效值都不是
30��,這說明 “數據審核”節點已經成功的幫我們識別出了這兩列的缺失值�����。同時我們可以發現電話這一項的有效數據仍然是 30.
下邊我們就來看看如何在 Modeler 中定義缺失值�����。
缺失值定義
雙擊“可變文件”節點�����,選擇類型頁����。如下圖:
圖 5. “可變文件”節點類型頁
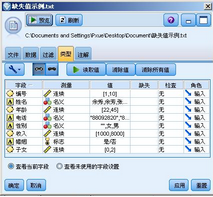
在類型頁里我們發現有一列名為“缺失”�����,我們在電話這一列我們點擊缺失這以空白項�����。
圖 6. 指定缺失值

我們選擇指定…��,會打開一個新的頁面:
圖 7. 配置電話缺失值
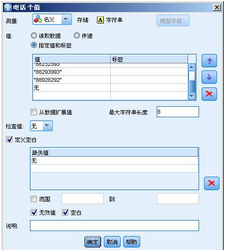
如上圖����,我們選擇“定義空白”�,添加一個缺失值為“無”��。然后點擊確定�����,關閉窗口��。
接著我們再來運行數據審核��,得到如下結果:
圖 8. 數據審核結果圖
這次我們可以發現電話這一項的有效數據變成了 29. 說明我們定義的缺失值成功了�����。
然后我們選擇“數據審核”節點的質量頁��,如下圖 :
圖 9. 數據質量結果圖
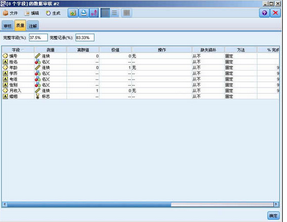
從上圖中可以看出完整的字段為 37.5%�,完整的記錄為
83.33%���,這時我們可以決定如何處理缺失值����,如果我們完整的字段占的比例很高���,那么我們一般應該過濾掉包含缺失值的字段然后進行建模���。另一種情況���,如果完整記錄所占比例較高那么我們應該刪除那些含有缺失值的記錄然后進行建模��。
Modeler 考慮到這兩種情況��,提供了非常實用的功能來幫助我們進行數據的篩選����。我們打開數據審核結果�����,選擇質量頁面�,單擊工具條上的生成按鈕��,里邊可以選擇生成列的過濾節點����,或者值的選擇節點�����。生成的節點可以幫助我們自動過濾含有缺失值的行或者列���。
上面所說的對缺失值的處理是刪除含有缺失值的列或者行���,還有一種辦法是我們可以對缺失值進行填充���,比如我們可以用缺失值所在列的平均值���,隨機值來進行填充��,或者我們對該列進行建模預測�����,來達到填充缺失值的目的�����。
使用 Modeler 進行異常值分析
什么是異常值
異常值就是數據文件中那些和其它值相比有明顯不同的值�,它們可以通過觀察數據分布來確定�。
在具體考慮異常值時��,我們需要注意異常值的類型����,一般分為兩種���,一種是可枚舉類型���,比如超市里的商品名���,商品名不可能有異常值����。假如我們利用會員購買的商品來預測他會不會購買體育用品���,因為商品很多�����,使得購買相同商品的用戶數量很少��,所建模型就會很不穩定�。這時我們應該對商品進行抽象�,比如抽象為水果����,零食�,日用品��,蔬菜��,化妝品等�,用這樣的數據進行預測�����,就會使模型可靠性提升��。利用
Modeler 里的“分布”節點可以對這種可枚舉類型的數據進行分組��。
圖 10. 001 用戶消費記錄
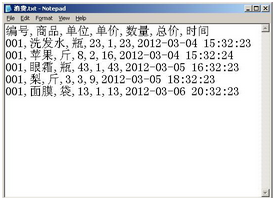
假如我們有上表這樣的數據����,我們如何將商品進行抽象分組呢����?首先我們建立一個 stream����,用“可變文件節點”來讀取數據���。然后連接一個“分布”節點��。運行分布節點�����,得到下圖�����。
圖 11. 分布節點運行結果
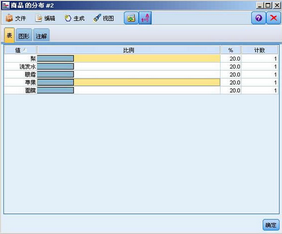
比如我們可以選擇梨�,蘋果����,然后右鍵選擇“組”�,建立一個水果組��。類似的建立一個化妝品組����。然后我們可以選擇“生成”菜單���,讓 Modeler 自動幫我們生成一個分組節點����。這樣�,我們就可以用水果�����,化妝品這樣的具有一定抽象意義的值來代替原來具體的值��。
另一種類型就是連續型數據���,比如用戶收入���,用戶年齡等��。對于連續型數據���,運行數據審核節點��,在質量頁面我們就可以查看離群值和極值�����。默認情況下���,Modeler 是根據平均值的標準差來確定離群值和極值的�����。在運行“數據審核”結果頁面我們也可以設置離群值和極值的處理方法
圖 12. 處理異常值的設置

選擇工具條里的生成按鍵�,選擇離群值和極值超節點�����。這時���,Modeler 會幫我們自動生成一個過濾離群值和極值的超節點�。我們連接“可變文件”節點和這個超節點���,Modeler 就會幫我們按照我們期望的處理方式來處理離群值和極值�����。
還有一種異常值是需要多個列組合才能看出來��。比如某顧客每個月在超市消費額都在 1000 以上�,但是他的會員信息顯示他的月收入為 1000
元��,這條記錄就可以被識別為異常值�。需要進一步分析����。同樣 Modeler 也提供了相應的功能來幫助我們識別這樣的聯合分布的異常值�。
圖 13. 用戶收入消費表
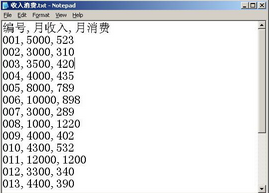
從上邊的數據中��,我們很難發現哪條數據有異常���,下邊我們就用 Modeler 里的“圖”節點來幫助我們分析數據��。
我們將“可變文件”節點的數據文件指向示例數據��,添加一個“圖”節點��,并雙擊“圖”節點�,如圖:
圖 14. 設置圖節點
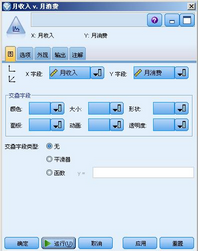
運行圖節點�����。
圖 15. “圖”節點結果
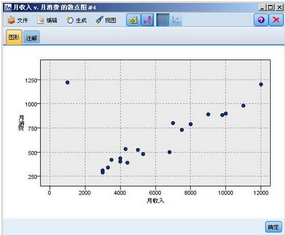
這是我們能明顯看到左上角的一個異常值����,鼠標移動到這個點上���,我們可以看到這個點所代表的詳細信息���。
使用 Modeler 觀察數據項之間聯系
對于數據挖掘來說在進行真正的建模之前����,通過觀察數據項之間的關系����,特別是輸入數據項和目標數據項之間的關系���,是非常有意義的����,它能快速的讓我們對數據之間的關系有個大概了解����,精簡一些不必要的數據項����,提高建模速度和穩定性����。
下邊我們就以超市調查結果來看�����,其中已經將會員消費記錄整合成水果�����,蔬菜���,日常用品����,零食等��,這些列的數字代表此項消費在該會員所有消費中所占的百分比���。最后一列表示用戶是否對體育用品優惠活動感興趣�����。
圖 16. 用戶意向表
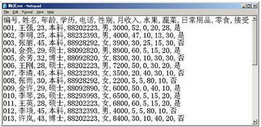
同樣我們新建一個 Stream����,加入一個“可變文件”節點��,修改文件路徑到示例數據��,然后����,我們連接一個“均值”節點�����。雙擊“均值”節點���,進入編輯:
圖 17. 均值節點
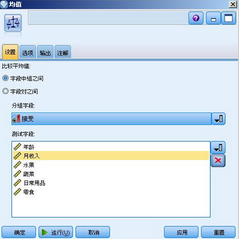
我們選擇接受為分組字段�,年齡�,月收入�����,水果�����,蔬菜�����,日常用品�,零食為測試字段�����。
然后����,我們運行“均值”節點���,得到下表:
圖 18. 均值節點結果
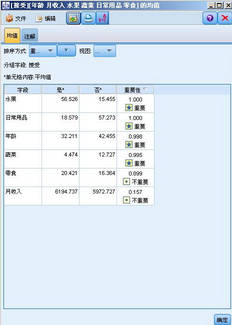
從統計數據來看����,可以決定用戶是否對體育用品感興趣的重要因素為水果�����,日常用品�����,年齡����,蔬菜���。而零食和月收入對預測影響較小��。
結束語
通過本文的描述��,你應該對數據理解所要做的工作��,以及如何利用 Modeler 來幫助你完成相關工作有了一定的了解�����。本文所涉及的 Node 只是
Modeler 中可用于數據理解相關 Node 的一部分���。另外在 Modeler 中�,通過 Node
之間靈活多變的組合����,可以完成更復雜的任務�。這些就留給讀者自己去探索吧���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
