R語言與機器學習中的回歸方法學習筆記
機器學習中的一些方法如決策樹�����,隨機森林���,SVM���,神經網絡由于對數據沒有分布的假定等普通線性回歸模型的一些約束���,預測效果也比較不錯���,交叉驗證結果也能被接受�。下面以R中lars包包含數據集diabetes為例說明機器學習中的回歸方法��。
一�、數據集及交叉驗證辦法描述
Diabetes數據集包含在R的lars包中����,數據分為x,y,x2三個部分�����,因變量為y,數據是關于糖尿病的血液化驗等指標��。這個數據集最早被用在偏最小二乘回歸的文章里�����。
交叉驗證采用指標NMSE來評價模型好壞�。這一統計量是計算模型預測性能和基準模型的預測性能之間的比率��。通常采用目標變量的平均值來作為基準模型�。其取值范圍通常為0~1���。如果模型表現優于這個非常簡單的基準模型預測����,那么NMSE應明顯小于1�����。NMSE的值越小��,模型的性能就越好���。NMSE的值大于1���,意味著模型預測還不如簡單地把所有個案的平均值作為預測值��!
交叉驗證辦法為將數據集分為5份�����,取4份作為訓練集�����,1份作為測試集�,共作5次�����,把誤差平均起來作為衡量標準����。選取代碼如下:
n<-length(dataset)
index1<-1:n
index2<-rep(1:5,ceiling(n/5))[1:n]
index2<-sample(index2,n)
二���、回歸樹
決策樹是通過一系列規則對數據進行分類的過程�。它提供一種在什么條件下會得到什么值的類似規則的方法��。決策樹分為分類樹和回歸樹兩種����,分類樹對離散變量做決策樹�,回歸樹對連續變量做決策樹�����。
基本算法:
1.選擇一個屬性放置在根節點����,為每個可能的屬性值產生一個分支
2.將樣本劃分成多個子集�,一個子集對應于一個分支
3.在每個分支上遞歸地重復這個過程���,僅使用真正到達這個分支的樣本
4.如果在一個節點上的所有樣本擁有相同的類別�����,即停止該部分樹的擴展
構造決策樹(集合劃分)時選擇屬性:
1.ID3:Information Gain
2.C4.5:Gain Ratio
3.CART:Gini Index
在R中我們使用rpart包中的rpart()函數實現樹回歸�。我們先把rpart包中的兩個十分重要的函數介紹如下:
構建回歸樹的函數:rpart()用法如下:
rpart(formula, data, weights, subset,na.action = na.rpart, method,
model = FALSE, x = FALSE, y = TRUE, parms, control, cost, ...)
主要參數說明:
fomula回歸方程形式:例如 y~x1+x2+x3�。
data數據:包含前面方程中變量的數據框(dataframe)�。
na.action缺失數據的處理辦法:默認辦法是刪除因變量缺失的觀測而保留自變量缺失的觀測��。
method根據樹末端的數據類型選擇相應變量分割方法,本參數有四種取值:連續型“anova”;離散型“class”;計數型(泊松過程)“poisson”;生存分析型“exp”��。程序會根據因變量的類型自動選擇方法,但一般情況下最好還是指明本參數,以便讓程序清楚做哪一種樹模型����。
parms用來設置三個參數:先驗概率���、損失矩陣�����、分類純度的度量方法����。
control控制每個節點上的最小樣本量��、交叉驗證的次數�、復雜性參量:即cp:complexitypamemeter,這個參數意味著對每一步拆分,模型的擬合優度必須提高的程度,等等�。
進行剪枝的函數:prune()用法如下:
prune(tree, cp, ...)
主要參數說明:
tree一個回歸樹對象,常是rpart()的結果對象����。
cp復雜性參量,指定剪枝采用的閾值����。cp全稱為complexity parameter��,指某個點的復雜度�����,對每一步拆分,模型的擬合優度必須提高的程度����,用來節省剪枝浪費的不必要的時間����,R內部是怎么計算的我不知道�,希望讀者能夠補充�。
進一步補充一點關于CP值的東西:建立樹模型要權衡兩方面問題�����,一個是要擬合得使分組后的變異較小����,另一個是要防止過度擬合���,而使模型的誤差過大�,前者的參數是CP�����,后者的參數是Xerror����。所以要在Xerror最小的情況下���,也使CP盡量小���。如果認為樹模型過于復雜��,我們需要對其進行修剪
���。(摘自推酷上的《分類-回歸樹模型(CART)在R語言中的實現》)
運行代碼:
library(rpart.plot)
reg<-rpart(y~.,w)
rpart.plot(reg,type=2,faclen=T)
得到回歸樹:
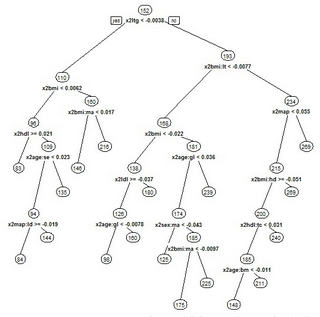
我們可以通過print(reg)來看到樹的各個節點的細節�����。
我們來進行交叉驗證��,運行代碼如下:
w<-diabetes[,2:3]
n<-length(w$y)
index1<-1:n
index2<-rep(1:5,ceiling(n/5))[1:n]
index2<-sample(index2,n)
NMSE<-rep(0,5)
NMSE0<-NMSE
for(i in 1:5){
m<-index1[index2==i]
reg<-rpart(y~.,w[-m,])
y0<-predict(reg,w[-m,])
y1<-predict(reg,w[m,])
NMSE0[i]<-mean((w$y[-m]-y0)^2)/mean((w$y[-m]-mean(w$y[-m]))^2)
NMSE[i]<-mean((w$y[m]-y1)^2)/mean((w$y[m]-mean(w$y[m]))^2)
}
R中輸出結果:
> NMSE
[1] 0.7892592 0.8857756 0.8619379 1.0072968 0.7238316
> NMSE0
[1] 0.3503767 0.3417909 0.3400387 0.3192845 0.3467186
明顯出現了過擬合現象�,應該使用剪枝函數��,對模型進行修正�。
> reg$cptable
CP n split relerror xerror xstd
1 0.29154165 0 1.0000000 1.0040015 0.05033316
2 0.08785891 1 0.7084583 0.8040962 0.04896667
3 0.05660089 2 0.6205994 0.7227529 0.04657623
4 0.02169615 3 0.5639986 0.6424826 0.04302580
5 0.02093950 4 0.5423024 0.6591446 0.04376777
6 0.01723601 50.5213629 0.6749867 0.04578783
7 0.01678503 6 0.5041269 0.6841483 0.04554068
8 0.01349365 8 0.4705568 0.6845580 0.04429950
9 0.01166564 9 0.4570632 0.7370893 0.04829371
10 0.01089168 11 0.43373190.7452419 0.05041336
11 0.01070564 12 0.42284020.7417955 0.05054043
12 0.01042308 14 0.40142890.7399988 0.05088835
13 0.01003363 15 0.39100580.7566972 0.05143535
14 0.01000000 17 0.37093860.7650728 0.05110011
參照上述結果����,選擇合適的cp值���。故修正為:
reg2<-prune(reg,cp=0.025)
rpart.plot(reg2,type=2,faclen=T)
結果為:
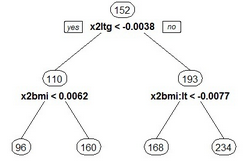
再次進行交叉驗證(代碼略)可以看到:
> NMSE
[1] 0.5982049 0.6995054 0.6826815 0.8970573 0.6407927
> NMSE0
[1] 0.5559462 0.5177565 0.4953384 0.5019682 0.5233709
過擬合現象基本消除�。
三�、boosting回歸
Boosting方法是一種用來提高弱分類算法準確度的方法,這種方法通過構造一個預測函數系列,然后以一定的方式將他們組合成一個預測函數��。他是一種框架算法,主要是通過對樣本集的操作獲得樣本子集,然后用弱分類算法在樣本子集上訓練生成一系列的基分類器�。他可以用來提高其他弱分類算法的識別率,也就是將其他的弱分類算法作為基分類算法放于Boosting
框架中,通過Boosting框架對訓練樣本集的操作,得到不同的訓練樣本子集,用該樣本子集去訓練生成基分類器;每得到一個樣本集就用該基分類算法在該樣本集上產生一個基分類器,這樣在給定訓練輪數
n 后,就可產生 n 個基分類器,然后Boosting框架算法將這 n個基分類器進行加權融合,產生一個最后的結果分類器,在這
n個基分類器中,每個單個的分類器的識別率不一定很高,但他們聯合后的結果有很高的識別率,這樣便提高了該弱分類算法的識別率�����。
Boosting方法簡而言之就是采取少數服從多數的原理����,他的合理性在于如果每個回歸樹的出錯率為40%�����,那么1000棵決策樹犯錯誤的概率就降到了4.40753e-11���,這就比較小了�����。
對diabetes數據做boosting回歸�����,使用到的函數包為mboost�����,使用函數為mboost.用法如下:
mboost(formula, data = list(), baselearner = c("bbs", "bols", "btree", "bss", "bns"), ...)
其中formular需要使用到函數btree():
btree(..., tree_controls = ctree_control(stump = TRUE, mincriterion = 0, savesplitstats = FALSE)) 試運行下列代碼:
library(mboost)
reg<-mboost(y~btree(x2.ltg)+btree(x2.bmi)+btree(x2.bmi.ltg),
data=w,control=boost_control(nu=0.1))
我們可以得到boosting回歸的信息�����,通過plot函數還有可視化結果�����。
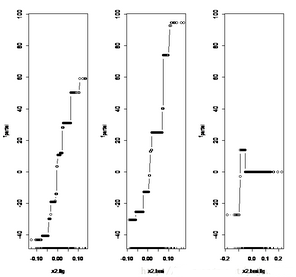
這里值得一提的是我在做boosting回歸時為了減少工作量直接做了變量選擇(這個選擇與回歸樹的最終選擇是一致的�����,所以也有一定的道理)�����。最后交叉驗證的結果為:測試集NMSE為0.5513152��,訓練集NMSE為0.4656569��。比起上次計算的回歸樹模型測試集NMSE為0.7036484�����,訓練集NMSE為0.518876好了不少��。
四����、bagging回歸
與boosting回歸想法類似���,bagging回歸的做法就是不斷放回地對訓練樣本進行再抽樣�,對每個自助樣本都建立一棵回歸樹��,對于每一個觀測����,每棵樹給一個預測��,最后將其平均����。
對diabetes數據做bagging回歸���,使用到的函數包為ipred��,使用函數為bagging()���,用法如下:
bagging(formula, data, subset, na.action=na.rpart, ...)
主要參數介紹:
Formula:回歸方程形式
Data:數據集
Control:對樹枝的控制��,使用函數rpart.control()�����,可以控制諸如cp值����,xval等參量�����。
輸入代碼:
library(ipred)
reg<-bagging(y~.,data=w,coob=TRUE,control=rpart.control(cp=0.025))
結果為:
Baggingregression trees with 25 bootstrap replications
Call:bagging.data.frame(formula = y ~ ., data = w, coob = TRUE, control =rpart.control(cp = 0.025))
Out-of-bagestimate of root mean squared error: 58.3648
使用交叉驗證(代碼略)���,得到結果:測試集NMSE為0.5705753����,訓練集NMSE為0.3906232����。比起上次計算的回歸樹模型測試集NMSE為0.7036484��,訓練集NMSE為0.518876好了不少����。
五����、隨機森林回歸
與bagging回歸相比��,隨機森林則更進一步�����,不僅對樣本進行抽樣���,還對變量進行抽樣����。
對diabetes數據做隨機森林回歸���,使用到的函數包為randomForest����,使用函數為randomForest()��,用法如下:
randomForest(formula, data=NULL, ..., subset, na.action=na.fail)
這里值得一提的是�����,隨機森林有個十分牛逼的性質�����,不會出現過擬合現象���,這也省去了我們確定樹的分類程度等一系列麻煩的事情�����。得到結果:測試集NMSE為0.08992529���,訓練集NMSE為0.08835731�����,效果顯著提升���。隨機森林還可以輸出自變量重要性度量���,試運行代碼:
library(randomForest)
reg<-randomForest(y~.,data=w,importance=TRUE)
reg$importance
得到結果:
%IncMSE IncNodePurity
x.glu 68.8034199 42207.351
x2.age 22.6784331 18569.370
x2.sex 6.2735713 2808.346
x2.bmi 1379.0675134 371372.494
x2.map 331.3925059 113411.547
x2.tc 18.6080948 14990.179
x2.ldl 24.3690847 17457.214
x2.hdl 216.2741620 64627.209
x2.tch 419.0451857 93688.855
x2.ltg 1514.0912885 379235.430
x2.glu 81.7568020 51984.121
x2.age.2 1.5242836 19364.582
x2.bmi.2 75.6345112 53635.024
x2.map.2 5.9156799 23049.475
x2.tc.2 1.6792683 15631.426
(省略部分輸出)
其中第二列為均方誤差遞減意義下的重要性��,第三列為精確度遞減意義下的重要性���。
六���、其他的回歸方法
除去我們所說的以上4種方法外��,還有人工神經網絡回歸���,SVM回歸����,他們可以通過nnet,rminer包中有關函數實現���,這里我們從略�。
在結束本文之前���,我想我們可以做一件更有意義的事����。在介紹diabetes數據集時�����,我們提到了這個數據最早是一個關于偏最小二乘的例子����。那么想必他與這個模型的契合度還是不錯的����,我們可以嘗試去算算利用偏最小二乘得到的訓練集與測試集的NMSE�����。
代碼如下:
library(lars)
library(pls)
NMSE<-rep(0,5)
NMSE0<-NMSE
for(i in 1:5){
m<-index1[index2==i]
reg.pls <- plsr(y ~ x2, 64, data = diabetes[-m,], validation ="CV")
y0<-predict(reg.pls,diabetes[-m,])
y1<-predict(reg.pls,diabetes[m,])
NMSE0[i]<-mean((diabetes$y[-m]-y0)^2)/mean((diabetes$y[-m]-mean(diabetes$y[-m]))^2)
NMSE[i]<-mean((diabetes$y[m]-y1)^2)/mean((diabetes$y[m]-mean(diabetes$y[m]))^2)
}
運行結果:測試集NMSE為0.6094071�,訓練集NMSE為0.4031211����。這里也僅僅是得到了一個優于回歸樹���,與bagging回歸相當�,不如隨機森林的一個結果�����。也說明了機器學習方法在實際問題中還是有一定優勢的����。但這絕不意味著這樣的回歸可以代替OLS�����,畢竟這些數據挖掘的方法在表達式的簡潔程度��,計算量等諸多方面還是存在著或多或少的不足���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
