R語言對回歸模型進行回歸診斷
在R語言中���,對數據進行回歸建模是一件很簡單的事情�����,一個lm()函數就可以對數據進行建模了��,但是建模了之后大部分人很可能忽略了一件事情就是����,對回歸模型進行診斷���,判斷這個模型到低是否模型的假定��;如果不符合假定���,模型得到的結果和現實中會有巨大的差距����,甚至一些參數的檢驗因此失效�����。
因為在對回歸模型建模的時候我們使用了最小二乘法對模型參數的估計����,什么是最小二乘法�,通俗易懂的來說就是使得估計的因變量和樣本的離差最小�����,說白了就是估計出來的值誤差最?��?��;但是在使用最小二乘法的前提是有幾個假設的��。
這里我就引用《R語言實戰》的內容了��,在我大學中的《計量經濟學》這本書講的更為詳細�����,不過這里主要是介紹使用R語言對模型進行回歸診斷����,所以我們就不說太詳細了��;
假定
正態性:對于固定的自變量值����,因變量值成正態分布�����,也就是說因變量的是服從正態分布的
獨立性:Yi值之間相互獨立�����,也就是說Yi之間不存在自相關
線性:因變量和自變量是線性相關的�����,如果是非線性相關的話就不可以了
同方差:因變量的方法不隨著自變量的水平還不同而變化��,也可稱之為同方差
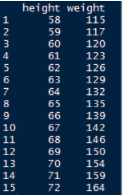
為了方便大家使用和對照�,這里就使用書上的例子給大家介紹了��,在系統自帶的安裝包中women數據集���,我們就想通過身高來預測一下體重���;在做回歸診斷之前我們得先建模�;
首先我們先看一下數據是長什么樣子的�,因為我們不能盲目的拿到數據后建模���,一般稍微規范的點流程是先觀察數據的分布情況�����,判斷線性相關系數�����,然后在考慮是否建立回歸模型���,然后在進行回歸診斷����;
R代碼如下:
data('women')
women
結果如下
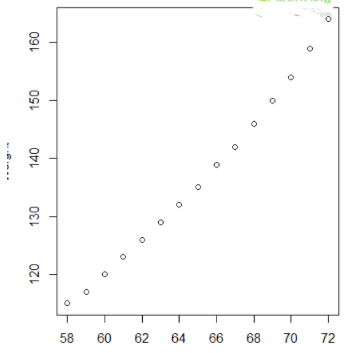
初步觀察數據大概告訴我們體重就是跟隨著身高增長而增長的��,再通過畫一下散點圖觀察��。
R代碼如下
plot(women)
然后我們在判斷一下各個變量之間的線性相關系數�,然后再考慮要不要建模
R代碼如下
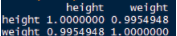
cor(women)
結果如下
從相關系數的結果上看��,身高和體重的相關程度高達0.9954��,可以認為是完全有關系的�����。
根據以上的判斷我們認為可以建立模型去預測了����,這時候我們使用LM()函數去建模��,并通過summary函數去得到完整的結果��。
R代碼如下
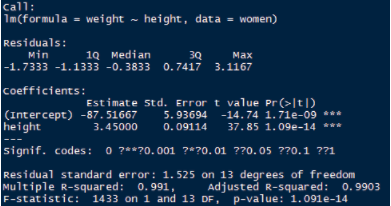
model <- lm(weight~height,data=women)
summary(model)
出現這個問號原因是由于電腦字符集問題����;稍微解讀一下這個結果����,RESIDUALS是殘差的五分位數��,不知道五分位的可以百度一下���,這里不多說����,下面的結果height的回歸系數是3.45�,標準差是0.09114��,T值為37.85�,P值為1.09e-14,并顯著通過假設檢驗�,殘差的標準差為1.525���,可決系數為0.991,認為自變量可以解釋總體方差的99.1%�����,調整后的可決系數為0.9903,這是剔除掉自變量的個數后的可決系數����,這個比較有可比性�����,一般我都看這個調整后的可決系數���。結果就解讀那么多�����,因此得到的結果就是
上面只是借用了一個小小例子來講解了一下R語言做回歸模型的過程���,接下來我們將一下如何進行回歸診斷���,還是原來的那個模型�,因為使用LM函數中會有一些對結果評價的內容���,因此我們用PLOT函數將畫出來���;
R代碼如下
par(mfrow=c(2,2))
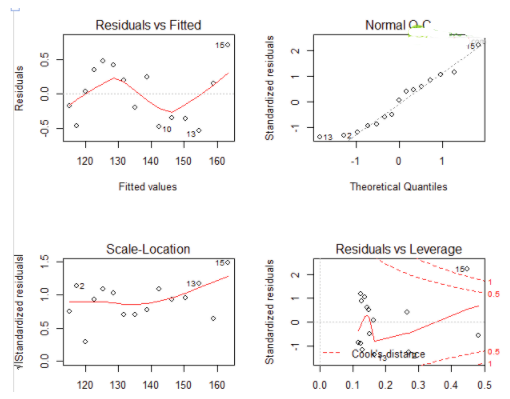
plot(model)
結果如下
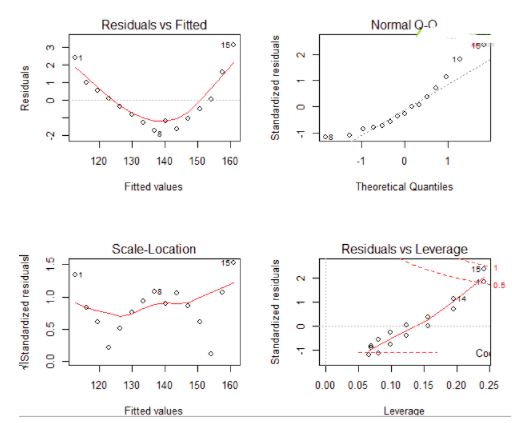
左上:代表的殘差值和擬合值的擬合圖���,如果模型的因變量和自變量是線性相關的話�����,殘差值和擬合值是沒有任何關系的�,他們的分布應該是也是在0左右隨機分布��,但是從結果上看�����,是一個曲線關系���,這就有可能需要我們家一項非線性項進去了
右上:代表正態QQ圖���,說白了就是標準化后的殘差分布圖���,如果滿足正態假定����,那么點應該都在45度的直線上�����,若不是就違反了正態性假
左下:位置尺度圖�����,主要是檢驗是否同方差的假設�����,如果是同方差���,周圍的點應該隨機分布
右下:主要是影響點的分析��,叫殘差與杠桿圖�,鑒別離群值和高杠桿值和強影響點���,說白了就是對模型影響大的點
根據左上的圖分布我們可以知道加個非線性項�,R語言實戰里面是加二次項����,這里我取對數��,主要是體現理解
R代碼如下
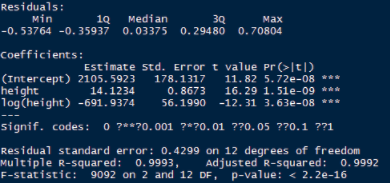
model1 <- lm(weight~height+log(height),data=women)
plot(model1)
summary(model1)
結果如下
診斷圖
模型擬合結果圖
綜合起來我們新模型貌似更優了��;我就介紹到這里��,具體大家可以看書籍
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
