揭秘10個大數據神話 為你排除幾個誤區
如果數據有一點點就不錯了�,那么數據是海量的話就一定棒極了���,對不對 這就好比說�, 如果一個炎日夏日里的微風讓你感覺涼爽�,那么你會為一陣一陣的涼風感到欣喜若狂��。以下為譯文:
也許對大數據更好的一個類比是它就像一匹意氣風發的冠軍賽馬: 通過適當的訓練和天賦的騎師�����,良種賽馬可以創造馬場記錄–但沒有訓練和騎手����,這個強大的動物根本連起跑門都進不了��。
為了確保你組織的大數據計劃保持正軌����,你需要消除以下10種常見的誤解���。
1. 大數據就是‘很多數據’
大數據從其核心來講�����,它描述了結構化或非結構化數據如何結合社交媒體分析�,物聯網的數據和其他外部來源�����,來講述一個”更大的故事”����。該故事可能是一個組織運營的宏觀描述�����,或者是無法用傳統的分析方法捕獲的大局觀��。從情報收集的角度來看����,其所涉及的數據的大小是微不足道的��。
2.大數據必須非常干凈
在商業分析的世界里�,沒有“太快”之類的東西�。相反��,在IT世界里�����,沒有“進垃圾����,出金子”這樣的東西�����,你的數據有多干凈 一種方法是運行你的分析應用程序�����,它可以識別數據集中的弱點����。一旦這些弱點得到解決�����,再次運行分析以突出 “清理過的” 區域�����。
3.所有人類分析人員會被機器算法取代
數據科學家的建議并不總是被前線的業務經理們執行��。行業高管Arijit
Sengupta在 TechRepublic
的一篇文章中指出�����,這些建議往往比科學項目更難實施�。然而���,過分依賴機器學習算法也同樣具有挑戰性�����。Sengupta說�����,機器算法告訴你該怎么做�,但它們沒有解釋你為什么要這么做����。這使得很難將數據分析與公司戰略規劃的其余部分結合起來�。
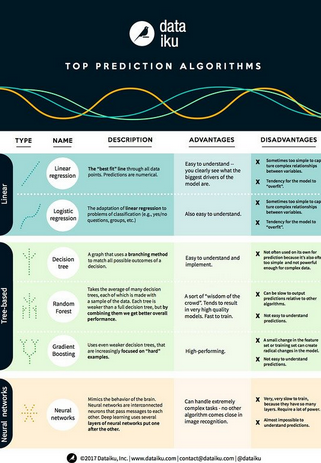
預測算法的范圍從相對簡單的線性算法到更復雜的基于樹的算法����,最后是極其復雜的神經網絡�。
4.數據湖是必須的
據豐田研究所數據科學家Jim
Adler說��,巨量存儲庫�,一些IT經理們設想用它來存儲大量結構化和非結構化數據��,根本就不存在��。企業機構不會不加區分地將所有數據存放到一個共享池中�����。Adler說���,這些數據是
“精心規劃”的�����,存儲于獨立的部門數據庫中����,鼓勵”專注的專業知識”�。這是實現合規和其他治理要求所需的透明度和問責制的唯一途徑���。
5.算法是萬無一失的預言家
不久前�,
谷歌流感趨勢項目 被大肆炒作�,聲稱比美國疾病控制中心和其他健康信息服務機構更快��、更準確地預測流感疫情的發生地�。正如《紐約客》的Michele
Nijhuis 在 2017年6月3日的文章 中所寫的那樣�,
人們認為與流感有關詞語的搜索會準確地預測疫情即將爆發的地區����。事實上���,簡單地繪制本地溫度是一個更準確的預測方法���。
谷歌的流感預測算法陷入了一個常見的大數據陷阱——它產生了無意義的相關性���,比如將高中籃球比賽和流感爆發聯系起來����,因為兩者都發生在冬季���。當數據挖掘在一組海量數據上運行時���,它更可能發現具有統計意義而非實際意義的信息之間的關系��。一個例子是將緬因州的離婚率與美國人均人造黃油的消費量掛鉤:盡管沒有任何現實意義�,但這兩個數字之間確實存在“統計上顯著”的關系�����。
6.你不能在虛擬化基礎架構上運行大數據應用
大約10年前�,當”大數據”首次出現在人們眼前時�����,它就是Apache
hadoop的代名詞�。就像VMware的Justin Murray在 2017年5月12日的文章
中所寫的��,大數據這一術語現在包括一系列技術��,從NoSQL(MongoDB�,Apache Cassandra)到Apache Spark����。
此前�,批評者們質疑Hadoop在虛擬機上的性能���,但Murray指出�����,Hadoop在虛擬機上的性能與物理機相當����,而且它能更有效地利用集群資源���。Murray還炮轟了一種誤解���,即認為虛擬機的基本特性需要存儲區域網絡(SAN)��。實際上�,供應商們經常推薦直接連接存儲�,這提供了更好的性能和更低的成本�����。
7��、機器學習是人工智能的同義詞
一個識別大量數據中模式的算法和一個能夠根據數據模式得出邏輯結論的方法之間的差距更像是一個鴻溝���。ITProPortal
的Vineet Jain在 2017年5月26日的文章
中寫道����,機器學習使用統計解釋來生成預測模型�����。這是算法背后的技術��,它可以根據一個人過去的購買記錄來預測他可能購買什么���,或者根據他們的聽歌歷史來預測他們喜歡的音樂�����。
雖然這些算法很聰明�,但它們遠遠不能達到人工智能的目的����,即復制人類的決策過程�����?����;诮y計的預測缺乏人類的推理���、判斷和想象力�����。從這個意義上說�,機器學習可能被認為是真正AI的必要先導��。即使是迄今為止最復雜的AI
系統�����,比如 IBM沃森 �����,也無法提供人類數據科學家所提供的大數據的洞察力����。
8.大多數大數據項目至少實現了一半的目標
IT經理們知道沒有數據分析項目是100%成功的�����。當這些項目涉及大數據時����,成功率就會直線下降�����,NewVantage
Partners最近的調查結果顯示了這一點���。在過去的五年中���,95%的企業領導人表示�,他們的公司參與了一個大數據項目�����,但只有48.4%的項目取得了”可衡量的結果”���。
NewVantage Partners的大數據執行調查顯示��, 只有不到一半的大數據項目實現了目標���,而 “文化”變化是最難實現的���。資料來源: Data Informed �。
事實上�,根據2016年10月發布的 Gartner的研究結果 ��,大數據項目很少能跨過試驗階段����。Gartner的調查發現����,只有15%的大數據實現被部署到生產中���,與去年調查報告的14%的成功率相對持平�����。
9.大數據的增長將減少對數據工程師的需求
如果你公司大數據計劃的目標是盡量減少對數據科學家的需求�����,你可能會得到令人不快的驚喜��。
2017 Robert Half 技術薪資指南 指出���, 數據工程師的年薪平均躍升到13萬美元和19.6萬美元之間����,
而數據科學家的薪資目前平均在11.6萬美元和16.3萬美元之間�, 而商業情報分析員的薪資目前平均在11.8萬美元到13.875萬美元之間���。
10.員工和一線經理將張開雙臂擁抱大數據
NewVantage
Partners的調查發現����,85.5%的公司都致力于創造一個“數據驅動的文化”����。然而�����,新的數據計劃的整體成功率僅為37.1%����。這些公司最常提到的三個障礙是缺乏組織一致性(42.6%)����,缺乏中層管理人員的采納和理解(41%)���,以及業務阻力或缺乏理解(41%)�。
未來可能屬于大數據���,但獲得這一技術的好處需要大量的針對多樣人性的老式辛勤工作�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
