讓Python猜猜你是否能約會成功
我是一個婚戀網站的數據分析師�,新入職的第二天�����,接到老板的任務�,讓我預測來婚戀網站新注冊的男生&女生是否會約會成功�。
如何預測一個新來的男生是否會約會成功呢�?這很簡單���,只需要調出一下數據庫中之前注冊網站的會員信息及跟蹤情況�����,看看和這個新來的男生條件最接近的男生是否約會成功了��,那么就可以大致預估新來的男生是否會約會成功��。中國有句老話叫做“近朱者赤��,近墨者黑”���,正是這個道理��。比如下圖��,假設我們將男生的條件劃分為三個維度����,顏值�����、背景和收入����。藍色點代表約會成功�����,灰色點代表未約會成功���。紅色點代表新來的男生�����,他和兩個藍色點�����,一個灰色點最接近���,因此點約會成功的可能性是2/3����。
KNN算法簡介
上述思路所用到的數據挖掘算法為KNN算法�, KNN(K Nearest Nighbor)�,K最鄰域法屬于惰性算法����,其特點是不事先建立全局的判別公式和規則���。當新數據需要分類的時候�,根據每個樣本和原有樣本的距離��,取最近K個樣本點的眾數(Y為分類變量)或者均值(Y為連續變量)作為新樣本的預測值�。實做KNN只需要考慮以下三件事情:
1. 數據的前處理
數據的屬性有Scale的問題��,比如收入和年齡的量綱單位不同�,則不能簡單的加總來計算距離���,需要進行極值的正規化�,將輸入變量維度的數據都轉換到【0,1】之間�����,這樣才能進行距離的計算��。計算公式如下:
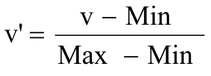
2. 距離的計算
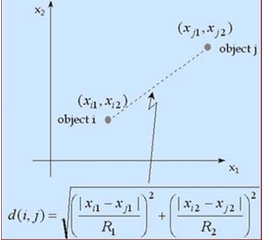
一般使用歐幾里得距離�,勾股定理大家都學過���,計算兩點之間的距離���,不多說��。
3. 預測結果的推估
預測過程中我們會同時輸出預測的概率值���,同時我們需要去了解幾個指標的含義����。
回應率(precision):
捕捉率(recall):
F指標(f1-score):F指標 同時考慮Precision & Recall
使用Python進行實做
此部分的思路如下:
1. 讀入數據集
2. 描述性分析與探索性分析
3. KNN模型建立
4. 模型的效果評估
數據集描述:此數據集為取自某婚戀網站往期用戶信息庫���,含100個觀測��,8個變量���。
# 加載所需包
%matplotlib inline
import os
import numpy as np
from scipy import stats
import pandas as pd
import sklearn.model_selection as cross_validation
import matplotlib.pyplot as plt
import seaborn as sns
import math
from scipy import stats,integrate
import statsmodels.api as sm
# 加載數據并查看前5行
orgData = pd.read_csv('date_data2.csv')
orgData.head()
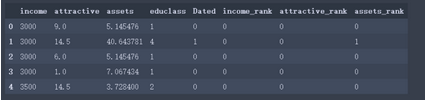
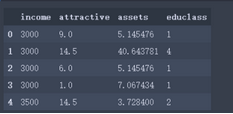
我從數據庫中挑選了收入�����、魅力值�、資產���、教育等級變量�,并對收入��、魅力值和資產進行了分類排序�����。
# 查看數據集的信息
orgData.info()

從上述信息可以看出數據集總共有100個觀測���,8個變量�����。其中浮點型2個��,整型6個��。還可以看出這個數據集占用了我電腦7k的內存���。
# 對數值型變量做描述性統計分析
orgData.describe()
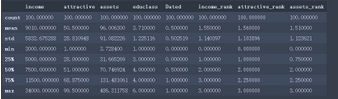
Python的語法就是這么簡潔到令人發指��。從上述信息我們可以觀察到各變量的計數����、最大值��、最小值�、平均值等信息�。以income為例����,平均值為9010元��,中位數為7500元�����。我們猜想是收入被平均了����,如何更直觀的看到呢�����?很簡單����,我們畫個直方圖�����。
# 數據可視化探索
# 查看收入分布情況 直方圖
sns.distplot(orgData['income'],fit=stats.norm);
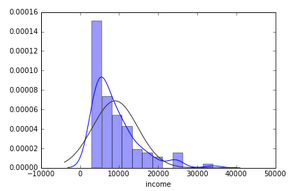
果然���,我們的收入被平均了����。其他的數值型變量也可以照同樣方法畫畫看��。同時���,我們想看看類別型的字段和目標變量的關系����。
# 查看教育等級和是否約會成功 條形圖
sns.barplot(x='educlass',y='Dated',data=orgData);
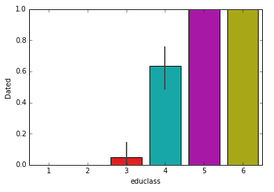
果然�,教育等級越高的人約會成功的概率越高���。這么多分類變量����,我如何在一張圖中呈現呢�����?很簡單����,設定面板數�,這里我們分類的計數圖���。
# 查看各分類變量和目標變量關系
fig, (axis1,axis2,axis3,axis4) = plt.subplots(1,4,figsize=(15,5))
sns.countplot(x='Dated', hue="educlass", data=orgData, order=[1,0], ax=axis1)
sns.countplot(x='Dated', hue="income_rank", data=orgData, order=[1,0], ax=axis2)
sns.countplot(x='Dated', hue="attractive_rank", data=orgData, order=[1,0], ax=axis3)
sns.countplot(x='Dated', hue="assets_rank", data=orgData, order=[1,0], ax=axis4)
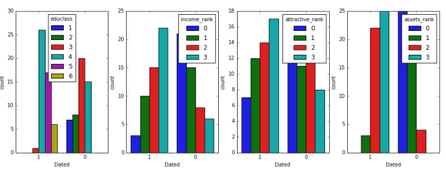
可以看出����,教育等級�,收入���,魅力值���,資產都和是否約會成功有密切關系�����。
說了這么多�����,下面我們開始用KNN建模�����,讓機器告訴我們結果吧���。
# 選取自變量和因變量
X = orgData.ix[:, :4]
Y = orgData[['Dated']]
X.head()
# 進行極值的標準化
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
X_scaled = min_max_scaler.fit_transform(X)
X_scaled[1:5]

此部分返回了自變量進行標準化之后的2~5行值���。
#劃分訓練集和測試集
train_data, test_data, train_target, test_target = cross_validation.train_test_split(
X_scaled, Y, test_size=0.2, train_size=0.8, random_state=123)
劃分訓練集和測試集����,訓練集用來訓練模型���,測試集用來測試模型�����,訓練集樣本和測試集樣本量比例為8:2.同時設定隨機種子數�����。
# 建模
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3) # 默認歐氏距離
model.fit(train_data, train_target.values.flatten())
test_est = model.predict(test_data)
我們首先從導入了KNN分類器����,k值設置為3�,然后用模型去訓練訓練集�����,并且用測試數據集來測試模型結果�,輸出到test_est對象中�����。
# 模型評估
import sklearn.metrics as metrics
print(metrics.confusion_matrix(test_target, test_est, labels=[0, 1])) # 混淆矩陣
print(metrics.classification_report(test_target, test_est))
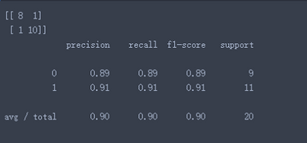
可以看出�����,模型的命中率和回應率均值都達到了90%��。F指標為0.9
好了����,模型的結果還勉強滿意�,美滋滋��,做個報告去和老板交差了��。
【后話】當然��,這里面只是用了一個簡單的數據集去實操了一下KNN的做法����,操作和語法都比較簡單易用理解����,同時遍歷了一下我們數據挖掘的流程�����,相應的知識及后續的知識沒有做過多的展開�,比如前端的數據如何清洗���,KNN中K值如何設定和交叉驗證�����,使用樸素貝葉斯預測模型的準確率�����,特征選擇���,模型融合等���。希望大家能有所收獲�����。
~ From CDA學員
CDA LEVEL II-Python數據挖掘課程�����,10.14開課���,本課程以案例為主線����,結合開源Python工具����,全面金融��、電信�、銀行等行業的主要數據挖掘主題���。而且注重業務與算法的深入結合�����,在輕松的氛圍內體會算法的奇妙之處����。
【課程信息】
北京&遠程直播:10月14~10月29
授課安排:現場班5900元�,遠程班4400元
(1) 授課方式:面授直播兩種形式��,中文多媒體互動式授課方式
(2) 授課時間:上午9:00-12:00����,下午13:30-16:30�����,16:30-17:00(答疑)
(3) 學習期限:現場與視頻結合���,長期學習加練習答疑���。
【課程階段】
第一階段:[10.14] 數據挖掘與Python入門
第二階段:[10.15] 數據挖掘模型與組合算法
第三階段:[10.21] KNN與線性回歸
第四階段:[10.22] 邏輯回歸與SVM
第五階段:[10.28] 文本分析與社會網絡分析
第六階段:[10.29] 綜合案例分析
第七階段:[線上選修] 數據分析統計基礎理論(一周)
第八階段:[線上選修] Mysql數據庫基礎知識(一周)
第九階段:[線上選修] Python數據可視化(一周)
【課程講師】
王小川
CDA數據分析師講師/同濟大學管理學博士
現就職于國內某大型券商研究所��,從事量化投資相關工作���,并承擔了部分高校統計課程教學任務��。長期研究機器學習在統計學中的應用�����,精通MATLAB����、Python��、SAS等統計軟件����,熱衷數據分析和數據挖掘工作���,有著扎實的理論基礎和豐富的實戰經驗�。著有《MATLAB神經網絡30個案例分析》一書�����。
趙仁乾
CDA數據分析研究院講師/京郵電大學管理科學與工程碩士
現就職于北京電信規劃設計院���,從事移動�、聯通集團及各省分公司市場�����、業務�����、財務規劃���、經濟評價及運營咨詢����。重點研究方向包括離網用戶挖掘��、市場細分與精準營銷����、移動網絡價值區域分析���、潛在價值客戶挖掘等��。
聯系方式:
王老師
Tel:18511302788
QQ:2881989710
Mail:wzd@cda.cn
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
