SPSS實例教程:有序多分類Logistic回歸
1�����、問題與數據
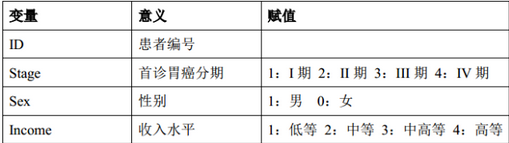
在某胃癌篩查項目中�����,研究者想了解首診胃癌分期(Stage)與患者的經濟水平的關系����,以確定胃癌篩查的重點人群�。為了避免性別因素對結論的混雜影響���,研究者將性別(Sex)也納入分析(本例僅為舉例說明如何進行軟件操作����,實際研究中需控制的混雜因素可以更多)�����。研究者將所有篩查人群的結果如表1�����,變量賦值如表2�����。
表1. 原始數據
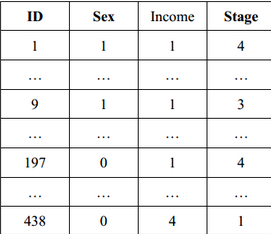
表2. 變量賦值情況
2��、對數據結構的分析
該設計中���,因變量為四分類�����,且分類間有次序關系��,針對因變量為分類型數據的情況應該選用Logistic回歸���,故應采用有序多分類的Logistic回歸分析模型進行分析��。
有序多分類的Logistic回歸原理是將因變量的多個分類依次分割為多個二元的Logistic回歸�,例如本例中因變量首診胃癌分期有1-4期����,分析時拆分為三個二元Logistic回歸����,分別為(1
vs 2+3+4) ��、(1+2 vs 3+4)����、(1+2+3 vs
4)���,均是較低級與較高級對比��。需注意的是�,有序多分類Logistic回歸的假設是��,拆分后的幾個二元Logistic回歸的自變量系數相等���,僅常數項不等�����。其結果也只輸出一組自變量的系數�。
因此�,有序多分類的Logistic回歸模型中�,必須對自變量系數相等的假設進行檢驗(又稱平行線檢驗)����。如果不滿足平行線假設��,則考慮使用無序多分類Logistic回歸或其他統計方法���。
3����、SPSS分析方法
(1)數據錄入SPSS
首先在SPSS變量視圖(Variable View)中新建四個變量:ID代表患者編號�,Sex代表性別����,Income代表收入水平�����,Stage代表首診胃癌分期�����。賦值參考表1����。然后在數據視圖(Data View)中錄入數據����。

(2)選擇Analyze → Regression → Ordinal Logistic

(3)選項設置
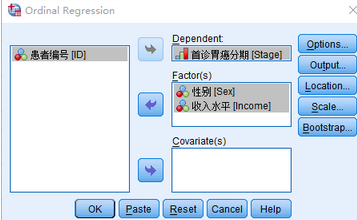
將因變量Stage放入因變量(Dependent)位置���,自變量性別(Sex)����、收入水平(Income)為分類變量�����,故放入因子(Factors)位置�����。若研究中還有連續型變量需要調整���,則放入協變量(Covariate)位置��。
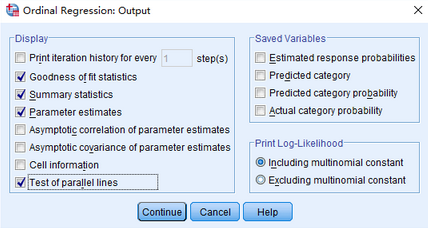
點擊輸出(Output)選項����,勾選平行線檢驗(Test of parallel lines)����。其余選項維持默認�。點擊確定(OK)��。
4���、結果解讀
(1)Case Processing Summary
給出的是數據的一般情況��,這里不進行介紹��。
(2)模型擬合優度檢驗
有兩個���,一個是似然比檢驗結果(Model Fitting Information).該檢驗的原假設是所有納入自變量的系數為0�,P(Sig.)<0.001���,說明至少一個變量系數不為0����,且具有統計學顯著性��。也就是模型整體有意義�����。
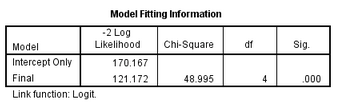
另一個結果是擬合優度檢驗(Goodness-of-Fit)結果����,提供了Pearson卡方和偏差(Deviance)卡方兩個檢驗結果��。但是�,這兩個檢驗結果不如上圖的似然比檢驗結果穩健�����,尤其是納入的自變量存在連續型變量時����,因此推薦以似然比檢驗結果為準��。
(3)偽決定系數(Pseudo R-Square)
對于分類數據的統計分析����,一般情況下偽決定系數都不會很高��,對此不必在意���。
(4)參數估計(Parameter Estimates)
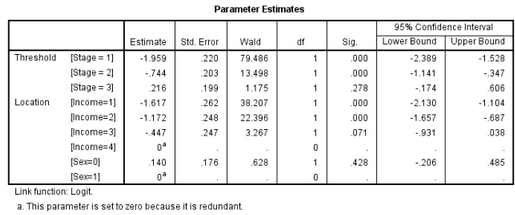
閾值(Threshold)對應的Stage=1,2,3三個估計值(Estimate)分別是本次分析中拆分的三個二元Logistic回歸的常數項��。位置(Location)中Sex和Income變量對應的參數估計值為自變量的估計值��。其中Income為多分類�����,在分析中被拆分成了三個啞變量(即Income
取值1�、2����、3)�����,分別與Income=4的組進行對比���。且有序多分類Logistic回歸假定拆分的多個二元回歸中自變量系數均相等����,因此結果只給出了一組自變量系數���。
Income=1系數估計值(Estimate)為-1.617意味著����,在調整性別變量的情況下�,Income=1(即收入水平最低)的組�,相比于Income=4(收入水平最高)的組���,初診胃癌分期至少低一個等級的可能性是exp(-1.617)=0.198倍���。其他系數解釋相同�。這說明��,收入水平低的人群���,其初診胃癌時病情更嚴重�����。
Sex變量系數無統計學意義(P=0.428)�����,如果沒有其他證據證明不同性別的初診胃癌分期有區別���,那么從模型精簡的角度考慮��,應當將Sex變量從模型中去掉再次進行回歸��,得到收入水平的參數估計值��。如果研究者比較肯定不同性別初診胃癌分期會產生區別����,那么即使在本研究中其系數無統計學意義也應保留在模型中(因為無統計學意義有可能是因為樣本量小造成的�,并不能說明該變量不產生影響)�。本研究中予以保留��。
(5)平行線假設檢驗(Test of Parallel Lines)

該檢驗的原假設是三個二元Logistic回歸自變量系數相等����,檢驗P(Sig.)值為0.052�����,不拒絕原假設��,可以認為假設成立��,可以使用多重有序Logistic回歸�����。如果將參數無統計學意義的Sex變量去掉��,會發現平行線假定檢驗P值會增大(P=0.175)(是否去掉Sex變量重回歸�,取決于是否有充足研究證據證明Sex是一個混雜變量���,如果是�����,Sex變量應保留在模型中)�����。
5����、結果匯總
胃癌患者的初診分期與患者的收入水平有關����。低等收入����、中等收入與中高等收入人群與高等收入人群相比����,初診胃癌分期低至少一個等級的可能性分別為0.198(P<0.001)�����、0.310(P<0.001)���、0.640(P=0.071)倍�。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
