Python實現二叉堆
二叉堆是一種特殊的堆����,二叉堆是完全二元樹(二叉樹)或者是近似完全二元樹(二叉樹)��。二叉堆有兩種:最大堆和最小堆���。最大堆:父結點的鍵值總是大于或等于任何一個子節點的鍵值��;最小堆:父結點的鍵值總是小于或等于任何一個子節點的鍵值����。
優先隊列的二叉堆實現
在前面的章節里我們學習了“先進先出”(FIFO)的數據結構:隊列(Queue)�。隊列有一種變體叫做“優先隊列”(Priority Queue)�����。優先隊列的出隊(Dequeue)操作和隊列一樣��,都是從隊首出隊���。但在優先隊列的內部�,元素的次序卻是由“優先級”來決定:高優先級的元素排在隊首����,而低優先級的元素則排在后面��。這樣��,優先隊列的入隊(Enqueue)操作就比較復雜�,需要將元素根據優先級盡量排到隊列前面��。我們將會發現�,對于下一節要學的圖算法中的優先隊列是很有用的數據結構���。
我們很自然地會想到用排序算法和隊列的方法來實現優先隊列�����。但是���,在列表里插入一個元素的時間復雜度是O(n)���,對列表進行排序的時間復雜度是O(nlogn)�。我們可以用別的方法來降低時間復雜度�。一個實現優先隊列的經典方法便是采用二叉堆(Binary Heap)�。二叉堆能將優先隊列的入隊和出隊復雜度都保持在O(logn)����。
二叉堆的有趣之處在于���,其邏輯結構上像二叉樹��,卻是用非嵌套的列表來實現�����。二叉堆有兩種:鍵值總是最小的排在隊首稱為“最小堆(min heap)”�,反之��,鍵值總是最大的排在隊首稱為“最大堆(max heap)”��。在這一節里我們使用最小堆���。
二叉堆的操作
二叉堆的基本操作定義如下:
BinaryHeap():創建一個空的二叉堆對象
insert(k):將新元素加入到堆中
findMin():返回堆中的最小項�,最小項仍保留在堆中
delMin():返回堆中的最小項����,同時從堆中刪除
isEmpty():返回堆是否為空
size():返回堆中節點的個數
buildHeap(list):從一個包含節點的列表里創建新堆
下面所示代碼是二叉堆的示例�����?���?梢钥吹綗o論我們以哪種順序把元素添加到堆里���,每次都是移除最小的元素�。我們接下來要來實現這個過程�����。
from pythonds.trees.binheap import BinHeap
bh = BinHeap()
bh.insert(5)
bh.insert(7)
bh.insert(3)
bh.insert(11)
print(bh.delMin())
print(bh.delMin())
print(bh.delMin())
print(bh.delMin())
為了更好地實現堆�,我們采用二叉樹����。我們必須始終保持二叉樹的“平衡”�����,就要使操作始終保持在對數數量級上�。平衡的二叉樹根節點的左右子樹的子節點個數相同����。在堆的實現中�,我們采用“完全二叉樹”的結構來近似地實現“平衡”�����。完全二叉樹��,指每個內部節點樹均達到最大值�,除了最后一層可以只缺少右邊的若干節點�����。圖 1 所示是一個完全二叉樹��。

圖 1:完全二叉樹
有意思的是我們用單個列表就能實現完全樹�。我們不需要使用節點����,引用或嵌套列表���。因為對于完全二叉樹����,如果節點在列表中的下標為 p���,那么其左子節點下標為 2p����,右節點為 2p+1�����。當我們要找任何節點的父節點時����,可以直接使用 python 的整除����。如果節點在列表中下標為n���,那么父節點下標為n//2.圖 2 所示是一個完全二叉樹和樹的列表表示法�����。注意父節點與子節點之間 2p 與 2p+1 的關系�。完全樹的列表表示法結合了完全二叉樹的特性���,使我們能夠使用簡單的數學方法高效地遍歷一棵完全樹�。這也使我們能高效實現二叉堆�。
堆次序的性質
我們在堆里儲存元素的方法依賴于堆的次序����。所謂堆次序��,是指堆中任何一個節點 x�����,其父節點 p 的鍵值均小于或等于 x 的鍵值����。圖 2 所示是具備堆次序性質的完全二叉樹�����。
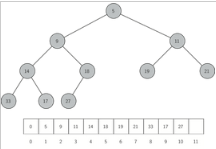
圖 2:完全樹和它的列表表示法
二叉堆操作的實現
接下來我們來構造二叉堆��。因為可以采用一個列表保存堆的數據�����,構造函數只需要初始化一個列表和一個currentSize來表示堆當前的大小���。Listing 1 所示的是構造二叉堆的 python 代碼����。注意到二叉堆的heaplist并沒有用到�����,但為了后面代碼可以方便地使用整除�����,我們仍然保留它����。
Listing 1
class BinHeap:
def __init__(self):
self.heapList = [0]
self.currentSize = 0
我們接下來要實現的是insert方法��。首先���,為了滿足“完全二叉樹”的性質����,新鍵值應該添加到列表的末尾���。然而新鍵值簡單地添加在列表末尾��,顯然無法滿足堆次序���。但我們可以通過比較父節點和新加入的元素的方法來重新滿足堆次序�。如果新加入的元素比父節點要小�����,可以與父節點互換位置�。圖 3 所示的是一系列交換操作來使新加入元素“上浮”到正確的位置����。
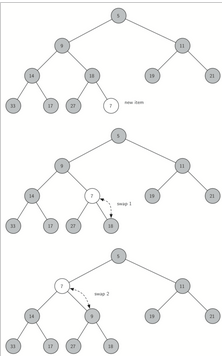
圖 3:新節點“上浮”到其正確位置
當我們讓一個元素“上浮”時�����,我們要保證新節點與父節點以及其他兄弟節點之間的堆次序�����。當然���,如果新節點非常小����,我們仍然需要將它交換到其他層�����。事實上��,我們需要不斷交換����,直到到達樹的頂端�。Listing 2 所示的是“上浮”方法�,它把一個新節點“上浮”到其正確位置來滿足堆次序��。這里很好地體現了我們之前在headlist中沒有用到的元素 0 的重要性���。這樣只需要做簡單的整除�,將當前節點的下標除以 2���,我們就能計算出任何節點的父節點����。
在Listing 3 中����,我們已經可以寫出insert方法的代碼����。insert里面很大一部分工作是由percUp函數完成的���。當樹添加新節點時���,調用percUp就可以將新節點放到正確的位置上���。
Listing 2
def percUp(self,i):
while i // 2 > 0:
if self.heapList[i] < self.heapList[i // 2]:
tmp = self.heapList[i // 2]
self.heapList[i // 2] = self.heapList[i]
self.heapList[i] = tmp
i = i // 2
Listing 3
def insert(self,k):
self.heapList.append(k)
self.currentSize = self.currentSize + 1
self.percUp(self.currentSize)
我們已經寫好了insert方法����,那再來看看delMin方法�。堆次序要求根節點是樹中最小的元素�,因此很容易找到最小項����。比較困難的是移走根節點的元素后如何保持堆結構和堆次序���,我們可以分兩步走�����。首先�����,用最后一個節點來代替根節點�。移走最后一個節點保持了堆結構的性質����。這么簡單的替換�,還是會破壞堆次序�。那么第二步��,將新節點“下沉”來恢復堆次序�。圖 4 所示的是一系列交換操作來使新節點“下沉”到正確的位置�。
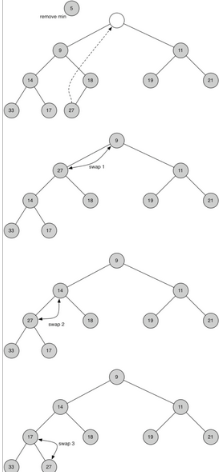
圖 4:替換后的根節點下沉
為了保持堆次序��,我們需將新的根節點沿著一條路徑“下沉”�����,直到比兩個子節點都小�。在選擇下沉路徑時���,如果新根節點比子節點大���,那么選擇較小的子節點與之交換�。Listing 4 所示的是新節點下沉所需的percDown和minChild方法的代碼��。
Listing 4
def percDown(self,i):
while (i * 2) <= self.currentSize:
mc = self.minChild(i)
if self.heapList[i] > self.heapList[mc]:
tmp = self.heapList[i]
self.heapList[i] = self.heapList[mc]
self.heapList[mc] = tmp
i = mc
def minChild(self,i):
if i * 2 + 1 > self.currentSize:
return i * 2
else:
if self.heapList[i*2] < self.heapList[i*2+1]:
return i * 2
else:
return i * 2 + 1
Listing 5 所示的是delMin操作的代碼���?��?梢钥吹奖容^麻煩的地方由一個輔助函數來處理�����,即percDown�。
Listing 5
def delMin(self):
retval = self.heapList[1]
self.heapList[1] = self.heapList[self.currentSize]
self.currentSize = self.currentSize - 1
self.heapList.pop()
self.percDown(1)
return retval
關于二叉堆的最后一部分便是找到從無序列表生成一個“堆”的方法���。我們首先想到的是����,將無序列表中的每個元素依次插入到堆中�����。對于一個排好序的列表����,我們可以用二分搜索找到合適的位置��,然后在下一個位置插入這個鍵值到堆中����,時間復雜度為O(logn)��。另外插入一個元素到列表中需要將列表的一些其他元素移動�,為新節點騰出位置��,時間復雜度為O(n)�����。因此用insert方法的總開銷是O(nlogn)����。其實我們能直接將整個列表生成堆��,將總開銷控制在O(n)����。Listing 6 所示的是生成堆的操作���。
Listing 6
def buildHeap(self,alist):
i = len(alist) // 2
self.currentSize = len(alist)
self.heapList = [0] + alist[:]
while (i > 0):
self.percDown(i)
i = i - 1
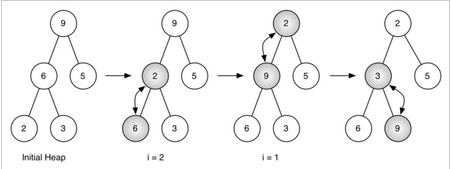
圖 5:將列表[ 9, 6, 5, 2, 3]生成一個二叉堆
圖 5 所示的是利用buildHeap方法將最開始的樹[ 9, 6, 5, 2, 3]中的節點移動到正確的位置時所做的交換操作�。盡管我們從樹中間開始�����,然后回溯到根節點����,但percDown方法保證了最大子節點總是“下沉”�����。因為堆是完全二叉樹�,任何在中間的節點都是葉節點�,因此沒有子節點��。注意����,當i=1時�����,我們從根節點開始下沉���,這就需要進行大量的交換操作�?���?梢钥吹?���,圖 5 最右邊的兩顆樹�,首先 9 從根節點的位置移走�����,移到下一層級之后����,percDown進一步檢查它此時的子節點�����,保證它下降到不能再下降為止���,即下降到正確的位置����。然后進行第二次交換�����,9 和 3 的交換��。由于 9 已經移到了樹最底層的層級�����,便無法進一步交換了�����。比較一下列表表示法和圖 5 所示的樹表示法進行的一系列交換還是很有幫助的��。
i = 2 [0, 9, 5, 6, 2, 3]
i = 1 [0, 9, 2, 6, 5, 3]
i = 0 [0, 2, 3, 6, 5, 9]
下列所示的代碼是完全二叉堆的實現�。
def insert(self,k):
self.heapList.append(k)
self.currentSize = self.currentSize + 1
self.percUp(self.currentSize)
def percDown(self,i):
while (i * 2) <= self.currentSize:
mc = self.minChild(i)
if self.heapList[i] > self.heapList[mc]:
tmp = self.heapList[i]
self.heapList[i] = self.heapList[mc]
self.heapList[mc] = tmp
i = mc
def minChild(self,i):
if i * 2 + 1 > self.currentSize:
return i * 2
else:
if self.heapList[i*2] < self.heapList[i*2+1]:
return i * 2
else:
return i * 2 + 1
def delMin(self):
retval = self.heapList[1]
self.heapList[1] = self.heapList[self.currentSize]
self.currentSize = self.currentSize - 1
能在O(n)的開銷下能生成二叉堆看起來有點不可思議���,其證明超出了本書的范圍��。但是�����,要理解用O(n)的開銷能生成堆的關鍵是因為logn因子基于樹的高度���。而對于buildHeap里的許多操作�,樹的高度比logn要小���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
