R語言處理缺失數據的高級方法
主要用到VIM和mice包
[plain]view plaincopy
install.packages(c("VIM","mice"))
1.處理缺失值的步驟
步驟:
(1)識別缺失數據�;
(2)檢查導致數據缺失的原因����;
(3)刪除包含缺失值的實例或用合理的數值代替(插補)缺失值
缺失值數據的分類:
(1)完全隨機缺失:若某變量的缺失數據與其他任何觀測或未觀測變量都不相關�����,則數據為完全隨機缺失(MCAR)�����。
(2)隨機缺失:若某變量上的缺失數據與其他觀測變量相關�,與它自己的未觀測值不相關��,則數據為隨機缺失(MAR)����。
(3)非隨機缺失:若缺失數據不屬于MCAR或MAR�,則數據為非隨機缺失(NIMAR)�����。
2.識別缺失值
NA:代表缺失值�;
NaN:代表不可能的值�;
Inf:代表正無窮�;
-Inf:代表負無窮��。
is.na():識別缺失值���;
is.nan():識別不可能值��;
is.infinite():無窮值����。
is.na()�、is.nan()和is.infinte()函數的返回值示例
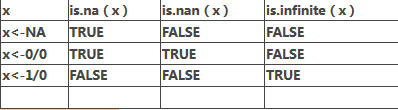
complete.cases()可用來識別矩陣或數據框中沒有缺失值的行���,若每行都包含完整的實例����,則返回TRUE的邏輯向量���,若每行有一個或多個缺失值�����,則返回FALSE���;
3.探索缺失值模式
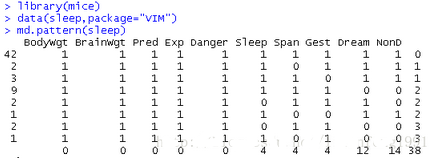
(1)列表顯示缺失值
mice包中的md.pattern()函數可以生成一個以矩陣或數據框形式展示缺失值模式的表格
[plain] view plain copy
library(mice)
data(sleep,package="VIM")
md.pattern(sleep)
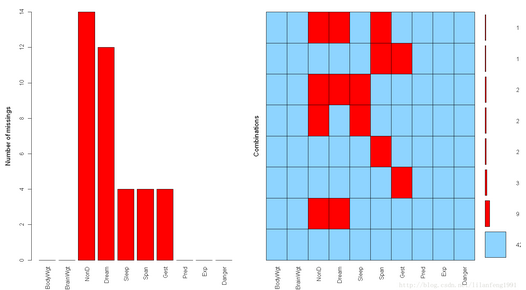
(2)圖形探究缺失數據
VIM包中提供大量能可視化數據集中缺失值模式的函數:aggr()��、matrixplot()���、scattMiss()
[plain] view plain copy
library("VIM")
aggr(sleep,prop=FALSE,numbers=TRUE)
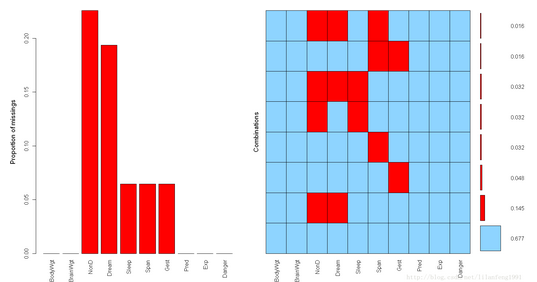
[plain] view plain copy
library("VIM")
aggr(sleep,prop=TRUE,numbers=TRUE)#用比例代替了計數
matrixplot()函數可生成展示每個實例數據的圖形
[plain] view plain copy
matrixplot(sleep)

淺色表示值小�,深色表示值大���;默認缺失值為紅色�����。
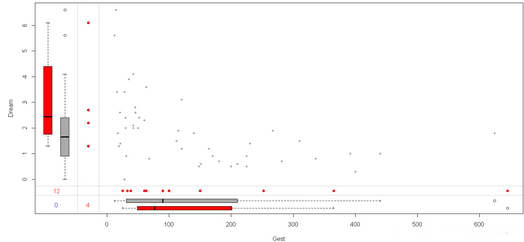
marginplot()函數可生成一幅散點圖�,在圖形邊界展示兩個變量的缺失值信息����。
[plain] view plain copy
library("VIM")
marginplot(sleep[c("Gest","Dream")],pch=c(20),col=c("darkgray","red","blue"))
(3)用相關性探索缺失值
影子矩陣:用指示變量替代數據集中的數據(1表示缺失����,0表示存在)���,這樣生成的矩陣有時稱作影子矩陣����。
求這些指示變量間和它們與初始(可觀測)變量間的相關性��,有且于觀察哪些變量常一起缺失��,以及分析變量“缺失”與其他變量間的關系����。
[plain] view plain copy
head(sleep)
str(sleep)
x<-as.data.frame(abs(is.na(sleep)))
head(sleep,n=5)
head(x,n=5)
y<-x[which(sd(x)>0)]
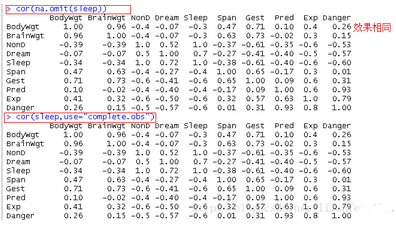
cor(y)
cor(sleep,y,use="pairwise.complete.obs")
4.理解缺失值數據的來由和影響
識別缺失數據的數目��、分布和模式有兩個目的:
(1)分析生成缺失數據的潛在機制����;
(2)評價缺失數據對回答實質性問題的影響���。
即:
(1)缺失數據的比例有多大��?
(2)缺失數據是否集中在少數幾個變量上�,抑或廣泛存在���?
(3)缺失是隨機產生的嗎�����?
(4)缺失數據間的相關性或與可觀測數據間的相關性�,是否可以表明產生缺失值的機制呢��?
若缺失數據集中在幾個相對不太重要的變量上��,則可以刪除這些變量��,然后再進行正常的數據分析�����;
若有一小部分數據隨機分布在整個數據集中(MCAR)�,則可以分析數據完整的實例�,這樣仍可得到可靠有效的結果����;
若以假定數據是MCAR或MAR����,則可以應用多重插補法來獲得有鏟的結論��。
若數據是NMAR����,則需要借助專門的方法��,收集新數據�,或加入一個相對更容易��、更有收益的行業���。
5.理性處理不完整數據
6.完整實例分析(行刪除)
函數complete.cases()��、na.omit()可用來存儲沒有缺失值的數據框或矩陣形式的實例(行):
[plain] view plain copy
newdata<-mydata[complete.cases(mydata),]
newdata<-na.omit(mydata)
[plain] view plain copy
options(digits=1)
cor(na.omit(sleep))
cor(sleep,use="complete.obs")
[plain] view plain copy
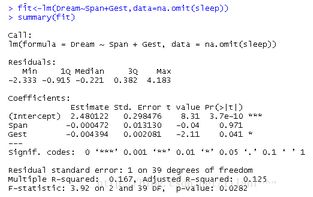
fit<-lm(Dream~Span+Gest,data=na.omit(sleep))
summary(fit)
7.多重插補
多重插補(MI)是一種基于重復模擬的處理缺失值的方法�。
MI從一個包含缺失值的數據集中生成一組完整的數據集���。每個模擬數據集中�,缺失數據將使用蒙特卡洛方法來填補�。
此時��,標準的統計方法便可應用到每個模擬的數據集上�,通過組合輸出結果給出估計的結果��,以及引入缺失值時的置信敬意��。
可用到的包Amelia����、mice和mi包
mice()函數首先從一個包含缺失數據的數據框開始�,然后返回一個包含多個完整數據集的對象�。每個完整數據集都是通過對原始數據框中的缺失數據進行插而生成的��。
with()函數可依次對每個完整數據集應用統計模型
pool()函數將這些單獨的分析結果整合為一組結果�。
最終模型的標準誤和p值都將準確地反映出由于缺失值和多重插補而產生的不確定性����。
基于mice包的分析通常符合以下分析過程:
[plain] view plain copy
library(mice)
imp<-mice(mydata,m)
fit<-with(imp,analysis)
pooled<-pool(fit)
summary(pooled)
[plain] view plain copy
mydata是一個飲食缺失值的矩陣或數據框�;
[plain] view plain copy
imp是一個包含m個插補數據集的列表對象�,同時還含有完成插補過程的信息�,默認的m=5
[plain] view plain copy
analysis是一個表達式對象�����,用來設定應用于m個插補的統計分析方法����。方法包括做線回歸模型的lm()函數�����、做廣義線性模型的glm()函數����、做廣義可加模型的gam()���、及做負二項模型的nbrm()函數����。
[plain] view plain copy
fit是一個包含m個單獨統計分析結果的列表對象���;
[plain] view plain copy
pooled是一個包含這m個統計分析平均結果的列表對象����。
[plain] view plain copy
</pre><pre name="code" class="plain">library(mice)
data(sleep,package="VIM")
imp<-mice(sleep,seed=1234)

[plain] view plain copy
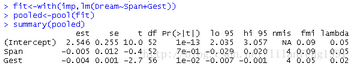
fit<-with(imp,lm(Dream~Span+Gest))
pooled<-pool(fit)
summary(pooled)
[plain] view plain copy
imp
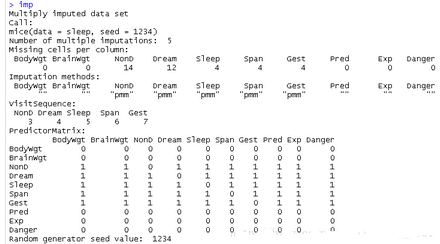
[plain] view plain copy
imp$imp$Dream

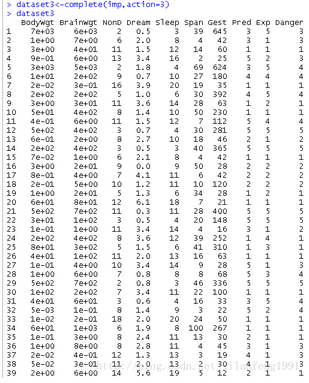
利用complete()函數可觀察m個插補數據集中的任意一個�,格式為:complete(imp,action=#)
eg:
[plain] view plain copy
dataset3<-complete(imp,action=3)
dataset3
8.處理缺失值的其他方法
處理缺失數據的專業方法

(1)成對刪除
處理含缺失值的數據集時��,成對刪除常作為行刪除的備選方法使用�����。對于成對刪除�����,觀測只是當它含缺失數據的變量涉及某個特定分析時才會被刪除�。
[plain] view plain copy
cor(sleep,use="pairwise.complete.obs")
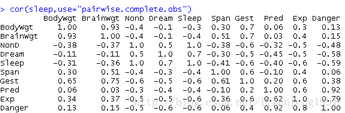
雖然成對刪除似乎利用了所有可用數據��,但實際上每次計算只用了不同的數據集�����,這將會導致一些扭曲��,故建議不要使用該方法�����。
(2)簡單(非隨機)插補
簡單插補����,即用某個值(如均值�����、中位數或眾數)來替換變量中的缺失值��。注意���,替換是非隨機的��,這意味著不會引入隨機誤差(與多重襯托不同)�����。
簡單插補的一個優點是��,解決“缺失值問題”時不會減少分析過程中可用的樣本量��。雖然 簡單插補用法簡單��,但對于非MCAR的數據會產生有偏的結果��。若缺失數據的數目非常大��,那么簡單插補很可能會低估標準差����、曲解變量間的相關性�����,并會生成不正確的統計檢驗的p值����。應盡量避免使用該方法�。
9.R中制作出版級品質的輸出
常用方法:Sweave和odfWeave���。
Sweave包可將R代碼及輸出嵌入到LaTeX文檔中���,從而得到 PDF�、PostScript和DVI格式的高質量排版報告����。
odfWeave包可將R代碼及輸出嵌入到ODF(Open Documents Format)的文檔中
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
