R語言建立時間序列的兩個函數
金融數據必須是時間序列���,才可進行經濟統計分析�。建立時間序列�,必須有日期作為數據框的一列����。R語言建立時間序列的兩個函數是ts()和as.xts()�����。
1.ts()
library(stats) #stats軟件包是R語言環境啟動的7個軟件包
ts(gm,frequency=12,start=c(1975,1))
這個命令表示:
(1) frequency=12表明時間單位為年��,而且在每一個時間單位中有12個均勻間隔的觀察值�����。
因此gm是月數據����,在金融數據中����,常用的有月收益率數據��。
(2) start=c(1975,1)表示開始時間為1975年1月�。
(3) gm應是列數據����,而不能是多列金融數據��。而且gm在數據框中選擇出來時���,應有日期在同一個數據框中�����。
frequency和start是R中ts()函數產生時間序列對象需要的兩個基本參數����。frequency的用法��,
(a)frequency=4表明時間單位是年�,每一個時間單位中有4個季節觀察值�。
(b)frequency=365表明時間單位是年��,每一個時間單位中有365個日期觀察值����。
若樣本容量T<365��,則可用frequency=T表示�。
start的用法�。
(a)若ts(gm,frequency=365,start=c(2014,1,1))建立時間序列�。
但是�,若用 ts(gm,frequency=365,start=c(2014,1,1),end(2014,12,31))結果將不同�。
(b)若用ts(gm,frequency=1,start=c(2014,1,1))則�,創建的時間序列start和end不同���,將1年的時間單位用1天表示�。
這個用法一般是gm只有一年的數據�,對此年的數據進行以天為單位的經濟統計���。
然而金融數據大多數并不是以365個數據為一年的數據��,比如股市一年的有效數據一般在240多天��,因此frequence的選擇應該與一年的實際數據為準���。
完整的函數表示:
ts(data = NA, start = 1, end = numeric(0), frequency = 1, deltat = 1,
ts.eps = getOption("ts.eps"), class = , names = )
詳細信息可見R語言系統
>?ts
e.g. 參數class
|
class to be given to the result, or none ifNULLor"none". The default is"ts"for a single series,c("mts", "ts", "matrix")for multiple series.
|
2.as.xts()
as.xts()與ts()不同����,要求行名是日期�。因此數據框中的日期必須賦值到行名�����,
而且刪除日期所在的列���。
eg1. as.xts()建立時間序列的主要命令
da=read.table("m-gm3dxjsh2016.txt",header=T)
gm2016=da[,1:2] #da[1]是日期�����,da[2]是金融數據
rownames(gm2016)=gm2016[,1] #將日期賦值到行名����,注意不能用gm2016[1]����,否則長度不同
gm=gm2016[-1] # 去掉第一列
gm1=as.xts(gm[,1]) # 建立金融數據的時間序列����,實際上這個語句并能運行���,原因見eg2.
將日期賦值到行名的編程方法有很多��,第二個程序的數據文件不同��。
eg2.as.xts()建立時間序列的完整程序
> da=read.table("D:/programsdata/financialCapital/m-gm3dx2016.txt",head=T)
>head(da)
date gm vw ew sp
1 19750131 0.252033 0.141600 0.299260 0.122812
2 19750228 0.028571 0.058411 0.053918 0.059886
3 19750331 0.054487 0.030191 0.081497 0.021694
4 19750430 0.045593 0.046497 0.031093 0.047265
5 19750530 0.037209 0.055140 0.072876 0.044101
6 19750630 0.107955 0.051473 0.071792 0.044323
>gm2016=da[,1:2] #gm2016是數據框
>head(gm2016)
date gm
1 19750131 0.252033
2 19750228 0.028571
3 19750331 0.054487
4 19750430 0.045593
5 19750530 0.037209
6 19750630 0.107955
> dim(gm2016)
[1] 408 2
> str(gm2016) #成員date是int型
'data.frame': 408 obs. of 2 variables:
$ date: int 19750131 19750228 19750331 19750430 19750530 19750630 19750731 19750829 19750930 19751031 ...
$ gm : num 0.252 0.0286 0.0545 0.0456 0.0372 ...
> d=as.character(gm2016[,1]) #將int型日期轉換成Date型
> d1=as.Date(d,format="%Y%m%d")
> head(d1)
[1] "1975-01-31" "1975-02-28" "1975-03-31" "1975-04-30" "1975-05-30"
[6] "1975-06-30"
> class(d1)
[1] "Date"
> gm=gm2016[,2,drop=FALSE] #獲得數據框gm2016的第二列�����,drop=FALSE防止出現向量
> class(gm) #gm是數據框
[1] "data.frame"
> head(gm)
gm
1 0.252033
2 0.028571
3 0.054487
4 0.045593
5 0.037209
6 0.107955
> str(gm) #成員gm的類型是num數值型
'data.frame': 408 obs. of 1 variable:
$ gm: num 0.252 0.0286 0.0545 0.0456 0.0372 ...
> rownames(gm)=d1 #gm的行名是R語言標準時間表示
> head(gm)
gm
1975-01-31 0.252033 #注意19750131是不允許的
1975-02-28 0.028571
1975-03-31 0.054487
1975-04-30 0.045593
1975-05-30 0.037209
1975-06-30 0.107955
>library(xts)
>gm2=as.xts(gm)
比較
ts()和as.xts()兩個函數產生的時間序列的plot圖略有不同�����。然而acf圖和pacf圖則相同�。
nm1=as.xts(data1)
nm2=ts(data1,frequency=365,start=c(2014,1,1),end=c(2014,12,31))
acf(nm1,lag=20)
pacf(nm1,lag=20)
acf(nm2,lag=20)
pacf(nm2,lag=20)
plot(nm1)
plot(nm2)

圖1 acf和pacf圖
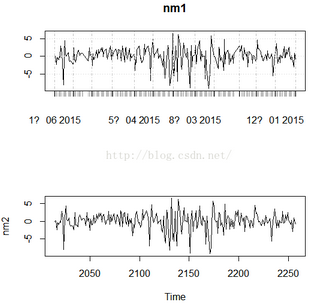
圖2 兩個函數產生的時間序列的plot圖
可以看到plot圖中�,ts()產生的時間序列更為精細����,而as.xts()的時間序列則略微粗糙��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
