機器學習領域的突破性進展(附視頻中字)
機器學習的發展涉及到各個方面�����,從語音識別到智能回復����。但這些系統中的“智能”實際上是如何工作的呢�����?還存在什么主要挑戰����?在本次講座中將一一解答�。
Google I/O 是由Google舉行的網絡開發者年會�����,Google I/O 2016 中圍繞機器學習領域的突破性進展進行了探討����。
CDA字幕組對該視頻進行了漢化��,附有中文字幕的視頻如下:
機器學習領域的突破性進展
針對不方便打開視頻的小伙伴��,CDA字幕組也貼心的整理了文字版本�,如下:

大家好����,歡迎來到講座:關于機器學習的突破性進展����。
我們探討了谷歌對于 AI 的長期愿景�����,以及過去十年對機器學習的研究����。這是十分重要的��,因為所有用戶都期待著奇跡發生�。他們希望能與科技自然地交流�,就像與人類交流一樣����。很明顯��,今天是不可能實現的�����,但是我們在向這個目標努力��。
我認為人們常常忽略的是���,谷歌不僅僅運用熟知的機器學習方法���,致力于逐步改進產品����。事實上我們有團隊負責基礎性工作���。為了改善機器學習最先進的技術����,他們在山景城以及世界各地工作�。
接下來你將聽到他們的一些工作成果����。如果你也在探索復雜的事情��,比如用Tensorflow工作�,或者致力于機器學習模型��,那么你可以通過這些演講者的經驗教訓得到一些啟示���。如果你是開發人員�����,想使用我們提供在云的機器學習API����,你會很好地理解到哪些好用��,以及你如何將其應用到自己的產品中����。希望你們能樂在其中���。下面有請Francoise�����。
語音識別
大家好�����,我叫Francoise���。我負責語音識別的工作�����。我在十年前加入谷歌��。你可能很難想起��,但十年前還沒有iPhone和安卓系統���。那時語音識別主要應用于呼叫中心�,這有些煩人并不有意思����。

我加入谷歌時有兩個目標:
一��、讓語音識別變得有趣且實用�����;
二��、讓語音識別更好地服務全球用戶�����。
如今過去了十年���,安卓手機中約20%的查詢都是通過語音�,我們將這視為一項成功��。我們剛發布了Cloud Speech API��,這能讓你們利用語音識別開發出更加有意思的產品�����。如今涵蓋了80種語言��、近40億人口�。

當然你可以問我����,達到這個成果為何花了十年? 畢竟語音識別很簡單����,用一年就能實現���,幾年后就能進行轉錄�����。但是如果看到不同的用戶和場景�����,當中有不同的需求�����、不同的說法���。
下面我想播放一些語音片段��,請點擊下視頻���。
(片段一: "大堡礁的水母季在什么時候?")
(片段二: 匈牙利語)這個人在講匈牙利語
(片段三:"大象會發出什么叫聲?")

這是我們需要預想到的數據�,不是么?我們想要為這些用戶提供服務��,無論他們是誰��。我們竭盡所能���,但有時候也會出錯����。
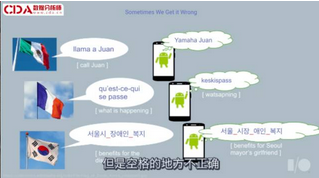
這是最近報告給我們的一個例子�,一位用戶說的是西班牙語���。他想表達的是 "打電話給朋友”���,但我們識別成了他想要買鋼琴之類的�����。
再看下一個例子����,你可能猜到了���,我講法語���。因此我用法語來測試我的產品���。我跟識別器說"發生什么了?"卻得到這個結果��。雖然聽起來一樣�,但是拼寫完全不一樣�。
隨后我在韓語也遇到這種情況���,如果看到這些字符串����,實際上它正確識別了每個韓文字符����,但是空格的地方不正確���。這就很不一樣了�����,從翻譯結果就能知道��。
我們犯錯了�����,但是這可是語言識別��。語音識別就是機器學習����,所以我們能解決這個問題����。但在我們探討如何糾正錯誤之前��,我想向你們展示語音識別的工作原理���。
首先將語音波形圖輸入系統�,你希望從中得出句子����。
系統中有三個模型:第一個是語音模型����,負責提取語音片段�,嘗試找出音素的分布概率以及語言中每個發音����;第二個是發音模型���,它從音素得出單詞�����;第三個是語言模型�,通過概率將單詞連接起來�����。
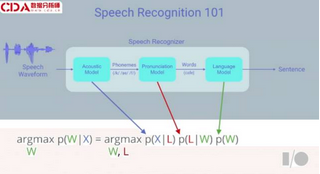
這是一個等式�,表明根據語音觀測我們試圖得出的最大概率的詞序列���。通過一些數學基礎��,對應不同的模型你能將其分解成三個概率���。這些都在表明這是統計模型�����,由三個不同模型組成 �����,當中的一切都是可統計的��。
我想多講講第一個語音模型����,因為幾十年來我們在用一種稱為高斯混和模型的技術��。多年來語音識別領域都用到該技術��。但在2012年����,我們改為使用神經網絡���。這花了一些時間�,因為神經網絡需要時間進行訓練�。它很龐大���,想從系統中得到正確的特點需要做很多優化工作��。但最終我們完成了�����。

通過轉為使用神經網絡�����,準確度得到了大幅度的改善��。除此以外����,它重啟了該領域的變革���。用了基礎設施我們開始創新神經網絡的結構�。我們使用它每個月我們都會推出新的結構��,并且比過去的版本更加強大����。
我們從深度神經網絡過渡到LSTM(長短期記憶)遞歸神經網絡��。然后我們開始添加卷積層�,這能讓我們更好地處理噪音和回響����。之后是CTC(connectionist temporal classification)�����。這個我將會仔細說明�����。這些類型的進步帶來了質量的改善����,因此在2015年對于不同的語言組�����,我們大大改善了準確度��。
回到CTC��,就像我所說的����。CTC能減少語音識別器的延遲�����,意味著當你對識別器說話時你將更快地得到回復����,這種感覺很好�。有時候事情很復雜��,作為谷歌中研究語音識別的團隊����,我們在生活中也得到了很多教訓�����。但為了讓你們從那些經驗教訓中獲益�����,我需要多講講語音識別的原理���。

正如我所說我們使用大量的數據訓練模型�,它們來源各不相同���, 將用來訓練模型�����。模型進入識別器�����,然后用識別器得出的數據�����,反饋回到模型����。因為那些數據很匹配我們要做的事情��。問題在于數據有時會出現拼寫錯誤�,各種各樣的錯誤��。數據并不干凈��,這會導致之前遇到的問題�。
有一天�����,我們看到識別器輸出中出現了韓語單詞"keu-a”�。我們并不是了解當中的原因�,于是開始分析����。我們發現那是小孩子的聲音����。人們在進行語音查詢��,背景出現了小孩子的聲音��。對于這些背景的高音識別器不知道如何處理���,所以它找到重元音的單詞就像"keu-a”�����。然后它會選出那個詞��,進行識別����。由于之前向你們展示的反饋環路�����,它會反饋到系統中����。如此反復����。
但在我們解決這個問題之前�����,我們在英式英語中開始看到"kdkdkd"這個詞���。你們能猜到它的由來嗎? 有人回答說是來自火車或地鐵����。所以是人們在火車和地鐵上使用手機���,伴隨著"tick tick"的聲音�����,然后識別器不知道如何處理�����。
最后一個有些說不出口��,是這個詞 "f*ck”�����。我們分析后發現是由于人們拿起手機然后講話��,會先吸氣呼吸��。這是吹氣的聲音��。

我意識解決這個問題需要向系統輸入更多的人類知識�。因此我們投入更多語言學家和人力資源�����,以解決這類問題�。從而對數據更好地格式化�����,然后正確地轉錄數據�����。我們建立了很復雜的準則�,為了正確地轉錄數據�。通過三百萬注釋的波形�,我們可以訓練語言模型��,從數據中學習新的發音�����,增加語言模型訓練集����,這些都會帶來改善��。
通過三百萬波形我們可以做很多工作���,如果是三千萬呢? 因此我們開始努力轉錄3萬3千小時的人類語音�����,需要600人在合理時間內完成�����。通過這些數據我們希望實現更加復雜�、更加緊密的結構�����。因此我們能夠使用����,并且實現語音識別的夢想���,即讓它服務到地球上的每個人����。
謝謝��,下面有請 Andrew���。

機器學習與圖像
謝謝 Francoise����。大家好����,我是 Andrew�。

這張是機器學習常見的圖����,圖中有一些紅點和藍點��。我們嘗試得出能夠區分紅點和藍點的模型����。當我們拿到新的輸入數據�,模型便可推測輸入的是紅點還是藍點����。

在接下來的10分鐘里����,我們將講些不一樣的內容�。這個是我����,這張照片里只有我一個人��。很難僅憑這點猜測我喜歡做什么����?���?赡芪蚁矚g戴帽子��。但是你可以收集一些特征���,訓練模型����,從而預測我喜歡做什么��。
講講另外一種做法����。不僅僅通過這個數據�,如果我把它和數據集中的相鄰數據一同考慮���,添加關聯性���。在這個例子中是加上我的孩子們?���,F在可以推斷����,也許我喜歡跟孩子們一起參加萬圣節活動�����。

通過這種直覺���,并不是獨立地對數據對象分類�����。我們可以利用不同數據點間的關系�。
谷歌有個叫做Expander的基礎設施��,專門完成這類任務����。這是利用數據對象間關聯性的平臺����。

舉個例子����,很明顯我喜歡萬圣節的"trick-or-treating”����。那么如果我能識別出南瓜將會很有用�����。在谷歌我們有個很棒的圖像理解系統��,這是它的工作原理����。輸入一組帶有訓練標簽的圖像�,接著它學習深度網絡��。這種學習能使它識別新圖像����,也能識別出未來的物體和圖像���。
現在我們給它沒有標簽的圖像�����,運用模型給這些圖像貼標簽����。你可能會問我們最開始用到的那些標簽怎么樣���。它們不錯���,但不是特別好���。
左邊的一個圖是南瓜��,右邊的是南瓜湯�。如果你使用神經網絡��,學習南瓜的形狀�,并接收這些輸入信息是很難的����。
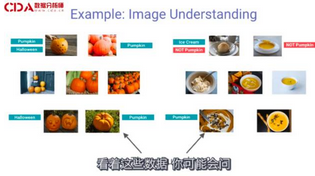
這是一個混合系統�����,它以圖片為基礎�����,學習關聯性�����,從而區分正確的訓練數據�����。并在這個基礎之上�,應用深度網絡學習來辨識出正確的模型��。
我們該怎么做呢? 我們已知這些數據對象的關系�,在這些像素陣列之間��,我們可以捕捉兩個圖形間相似點的嵌入映射�����。即這兩個圖像有多大幾率包括相同的物體����。
我們已知是南瓜的物體����,通過這些關聯線確認我們最初的判斷���,即物體為南瓜�����。當我們看到右邊的圖片����,我們也可以做同樣的操作�??梢酝卣箖蓚€不是南瓜的例子���。通過這些圖片得出結論�����,之前標記為南瓜湯的對象不太準確����。
我們可以使用這種方法���,減少訓練數據里約40%的數據�����。這樣圖像分類的度量標準提高了9%����。

讓我們看看它的工作原理�,這個是圖像傳播的一種等式形式�。我們寫一個罰函數(penalty function)得出數據中的相鄰關聯的效果����?�?吹接衛u-lv的部分���,這指數據集中U和V 節點數據相距多遠�����。Wuv為權重�����,代表它們的關聯強度���,然后加總整個數據集����。這指具有相似信息的關聯線條語句匹配度的差距��。然后我試著減少這個差距�����。

下面的這個等式表明��,如果對每個數據對象進行操作���,使用相鄰對象的標簽更新標簽��,對圖片中的所有數據都如此操作�����,如此重復���。信息在圖片中傳遞�,并得出收斂到成本函數的最佳分配��。以上是算法方面�。
還有系統方面��,構建這些系統是為了同時處理億萬量級的數據���。我們想在圖片上進行這樣的操作��,使用這些技術我們開發了相應的工具�。
另外兩個例子�����。比如短信智能回復��。這個圖片里的頂點是你可能會發送回復�����。線條代表相似信息��,即這些回復可用于相似語境��?;蛘呤窃~匯式相似�,即詞語相同�����?�;蛘咴~語嵌入為基礎的相似�����。

有這張圖之后我們就可以運行擴展器來生成簇�。這將返回相同意思的相似詞組�����。還可以針對特定用戶���,根據語境選出合適選項�����,對于不同簇的理解���,可以確保我們提供多樣的選擇����。因此我們并不是選擇三種方式表達相同的意思���。
這在英語中運用得很好����,我們也可以在其他語言中做相同操作���。比如專門用于問候的回復���。在英語中我可能會說 "Hi!""How's things?" "What's up?”��,這些句子之間有關聯��。
在法語中我可能會說"Ca Va?" "Salut!”��,我可以用谷歌翻譯的模型構建法語變量和英語變量間的關聯��。
我們能夠在其他語言中構建智能回復功能的數據結構�,比如葡萄牙語����、印度尼西亞語��、西班牙語����,甚至是印度英語中����。

再舉個例子�,搜索查詢����。我很喜歡萬圣節"trick-or-treating”����。我想給我的孩子講一些萬圣節的故事�,于是我向谷歌問一些問題�,希望谷歌能夠返回直接回答我問題的文字����。
這里是一張圖片��,其各個頂點代表查詢需求�。線條則表示兩個查詢能夠以相同的信息回復���。實線是我確定的內容��,虛線則是不太確定的內容����。完成之后�����,我們就可以自動解答億萬條搜索查詢中語義相等的問題了�。
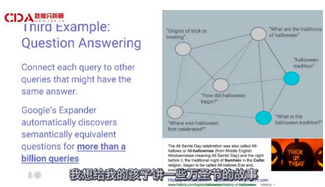
我們在圖片中使用機器學習來理解自然語言���、搜索查詢�、圖像和其他媒體對象���。你們可能還聽過照片回復�����,即用圖像回復�����,這是用的相同的技術����。我們可以使用相同的技巧生成簡要的模型��,并實際應用在安卓產品設備上��。

CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
