Python編程實現使用線性回歸預測數據
本文中��,我們將進行大量的編程——但在這之前�,我們先介紹一下我們今天要解決的實例問題����。
1) 預測房子價格

房價大概是我們中國每一個普通老百姓比較關心的問題�,最近幾年保障啊�����,小編這點微末工資著實有點受不了�。
我們想預測特定房子的價值�����,預測依據是房屋面積�����。
2) 預測下周哪個電視節目會有更多的觀眾

閃電俠和綠箭俠是我最喜歡的電視節目��,特別是綠箭俠�,當初追的昏天黑地的��,不過后來由于一些原因����,沒有接著往下看��。我想看看下周哪個節目會有更多的觀眾����。
3) 替換數據集中的缺失值
我們經常要和帶有缺失值的數據集打交道���。這部分沒有實戰例子�����,不過我會教你怎么去用線性回歸替換這些值��。
所以��,讓我們投入編程吧(馬上)
在動手之前����,去把我以前的文章(Python Packages for Data Mining)中的程序包安裝了是個好主意�����。
1) 預測房子價格
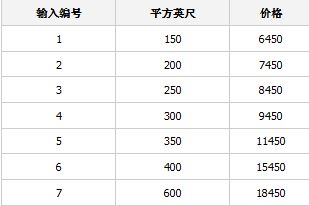
我們有下面的數據集:
步驟:
在線性回歸中����,我們都知道必須在數據中找出一種線性關系���,以使我們可以得到θ0和θ1�。 我們的假設方程式如下所示:
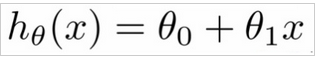
其中: hθ(x)是關于特定平方英尺的價格值(我們要預測的值)�����,(意思是價格是平方英尺的線性函數)�; θ0是一個常數����; θ1是回歸系數�����。
那么現在開始編程:
步驟1
打開你最喜愛的文本編輯器�����,并命名為predict_house_price.py���。 我們在我們的程序中要用到下面的包�,所以把下面代碼復制到predict_house_price.py文件中去���。
# Required Packages
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
運行一下你的代碼�。如果你的程序沒錯�����,那步驟1基本做完了���。如果你遇到了某些錯誤����,這意味著你丟失了一些包����,所以回頭去看看包的頁面����。 安裝博客文章中所有的包���,再次運行你的代碼���。這次希望你不會遇到任何問題���。
現在你的程序沒錯了���,我們繼續……
步驟2
把數據存儲成一個.csv文件����,名字為input_data.csv 所以讓我們寫一個函數把數據轉換為X值(平方英尺)��、Y值(價格)
# Function to get data
def get_data(file_name):
data = pd.read_csv(file_name)
X_parameter = []
Y_parameter = []
for single_square_feet ,single_price_value in zip(data['square_feet'],data['price']):
X_parameter.append([float(single_square_feet)])
Y_parameter.append(float(single_price_value))
return X_parameter,Y_parameter
第3行:將.csv數據讀入Pandas數據幀���。
第6-9行:把Pandas數據幀轉換為X_parameter和Y_parameter數據��,并返回他們����。
所以�,讓我們把X_parameter和Y_parameter打印出來:
[[150.0], [200.0], [250.0], [300.0], [350.0], [400.0], [600.0]]
[6450.0, 7450.0, 8450.0, 9450.0, 11450.0, 15450.0, 18450.0]
[Finished in 0.7s]
腳本輸出: [[150.0], [200.0], [250.0], [300.0], [350.0], [400.0], [600.0]]
[6450.0, 7450.0, 8450.0, 9450.0, 11450.0, 15450.0, 18450.0] [Finished in
0.7s]
步驟3
現在讓我們把X_parameter和Y_parameter擬合為線性回歸模型����。我們要寫一個函數��,輸入為X_parameters����、Y_parameter和你要預測的平方英尺值�����,返回θ0�、θ1和預測出的價格值�。
# Function for Fitting our data to Linear model
def linear_model_main(X_parameters,Y_parameters,predict_value):
# Create linear regression object
regr = linear_model.LinearRegression()
regr.fit(X_parameters, Y_parameters)
predict_outcome = regr.predict(predict_value)
predictions = {}
predictions['intercept'] = regr.intercept_
predictions['coefficient'] = regr.coef_
predictions['predicted_value'] = predict_outcome
return predictions
第5-6行:首先�,創建一個線性模型�,用我們的X_parameters和Y_parameter訓練它���。
第8-12行:我們創建一個名稱為predictions的字典����,存著θ0����、θ1和預測值���,并返回predictions字典為輸出��。
所以讓我們調用一下我們的函數�,要預測的平方英尺值為700����。
X,Y = get_data('input_data.csv')
predictvalue = 700
result = linear_model_main(X,Y,predictvalue)
print "Intercept value " , result['intercept']
print "coefficient" , result['coefficient']
print "Predicted value: ",result['predicted_value']
腳本輸出:Intercept value 1771.80851064 coefficient [ 28.77659574] Predicted value: [ 21915.42553191] [Finished in 0.7s]
這里��,Intercept value(截距值)就是θ0的值��,coefficient value(系數)就是θ1的值�。 我們得到預測的價格值為21915.4255——意味著我們已經把預測房子價格的工作做完了��!
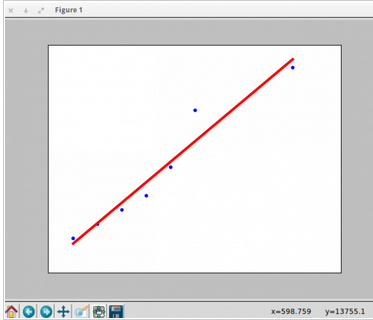
為了驗證����,我們需要看看我們的數據怎么擬合線性回歸���。所以我們需要寫一個函數�,輸入為X_parameters和Y_parameters���,顯示出數據擬合的直線�。
# Function to show the resutls of linear fit model
def show_linear_line(X_parameters,Y_parameters):
# Create linear regression object
regr = linear_model.LinearRegression()
regr.fit(X_parameters, Y_parameters)
plt.scatter(X_parameters,Y_parameters,color='blue')
plt.plot(X_parameters,regr.predict(X_parameters),color='red',linewidth=4)
plt.xticks(())
plt.yticks(())
plt.show()
那么調用一下show_linear_line函數吧:
?
1
show_linear_line(X,Y)
腳本輸出:
2)預測下周哪個電視節目會有更多的觀眾

閃電俠是一部由劇作家/制片人Greg Berlanti���、Andrew Kreisberg和Geoff
Johns創作�,由CW電視臺播放的美國電視連續劇�。它基于DC漫畫角色閃電俠(Barry
Allen)�����,一個具有超人速度移動能力的裝扮奇特的打擊犯罪的超級英雄��,這個角色是由Robert Kanigher�����、John
Broome和Carmine
Infantino創作���。它是綠箭俠的衍生作品���,存在于同一世界����。該劇集的試播篇由Berlanti��、Kreisberg和Johns寫作�����,David
Nutter執導�����。該劇集于2014年10月7日在北美首映���,成為CW電視臺收視率最高的電視節目�。
綠箭俠是一部由劇作家/制片人 Greg Berlanti�、Marc Guggenheim和Andrew
Kreisberg創作的電視連續劇�。它基于DC漫畫角色綠箭俠���,一個由Mort Weisinger和George
Papp創作的裝扮奇特的犯罪打擊戰士��。它于2012年10月10日在北美首映��,與2012年末開始全球播出�。主要拍攝于Vancouver����、British
Columbia��、Canada�,該系列講述了億萬花花公子Oliver Queen�,由Stephen
Amell扮演�����,被困在敵人的島嶼上五年之后����,回到家鄉打擊犯罪和腐敗�����,成為一名武器是弓箭的神秘義務警員�。不像漫畫書中����,Queen最初沒有使用化名”綠箭俠“�����。
由于這兩個節目并列為我最喜愛的電視節目頭銜�����,我一直想知道哪個節目更受其他人歡迎——誰會最終贏得這場收視率之戰�。
所以讓我們寫一個程序來預測哪個電視節目會有更多觀眾��。
我們需要一個數據集�����,給出每一集的觀眾�����。幸運地���,我從維基百科上得到了這個數據�����,并整理成一個.csv文件���。它如下所示��。
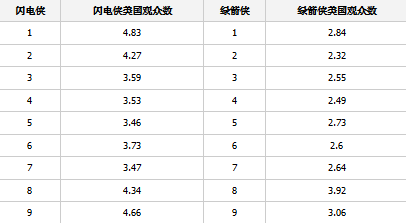
觀眾數以百萬為單位�����。
解決問題的步驟:
首先我們需要把數據轉換為X_parameters和Y_parameters�,不過這里我們有兩個X_parameters和Y_parameters�。因此�����,把他們命名為flash_x_parameter��、flash_y_parameter�、arrow_x_parameter����、arrow_y_parameter吧�����。然后我們需要把數據擬合為兩個不同的線性回歸模型——先是閃電俠���,然后是綠箭俠��。
接著我們需要預測兩個電視節目下一集的觀眾數量�����。 然后我們可以比較結果����,推測哪個節目會有更多觀眾�����。
步驟1
導入我們的程序包:
# Required Packages
import csv
import sys
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
步驟2
寫一個函數�����,把我們的數據集作為輸入�����,返回flash_x_parameter��、flash_y_parameter�、arrow_x_parameter�、arrow_y_parameter values��。
# Function to get data
def get_data(file_name):
data = pd.read_csv(file_name)
flash_x_parameter = []
flash_y_parameter = []
arrow_x_parameter = []
arrow_y_parameter = []
for x1,y1,x2,y2 in
zip(data['flash_episode_number'],data['flash_us_viewers'],data['arrow_episode_number'],data['arrow_us_viewers']):
flash_x_parameter.append([float(x1)])
flash_y_parameter.append(float(y1))
arrow_x_parameter.append([float(x2)])
arrow_y_parameter.append(float(y2))
return flash_x_parameter,flash_y_parameter,arrow_x_parameter,arrow_y_parameter
現在我們有了我們的參數����,來寫一個函數��,用上面這些參數作為輸入��,給出一個輸出��,預測哪個節目會有更多觀眾�。
# Function to know which Tv show will have more viewers
def more_viewers(x1,y1,x2,y2):
regr1 = linear_model.LinearRegression()
regr1.fit(x1, y1)
predicted_value1 = regr1.predict(9)
print predicted_value1
regr2 = linear_model.LinearRegression()
regr2.fit(x2, y2)
predicted_value2 = regr2.predict(9)
#print predicted_value1
#print predicted_value2
if predicted_value1 > predicted_value2:
print "The Flash Tv Show will have more viewers for next week"
else:
print "Arrow Tv Show will have more viewers for next week"
把所有東西寫在一個文件中�。打開你的編輯器�,把它命名為prediction.py���,復制下面的代碼到prediction.py中�����。
# Required Packages
import csv
import sys
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
# Function to get data
def get_data(file_name):
data = pd.read_csv(file_name)
flash_x_parameter = []
flash_y_parameter = []
arrow_x_parameter = []
arrow_y_parameter = []
for x1,y1,x2,y2 in
zip(data['flash_episode_number'],data['flash_us_viewers'],data['arrow_episode_number'],data['arrow_us_viewers']):
flash_x_parameter.append([float(x1)])
flash_y_parameter.append(float(y1))
arrow_x_parameter.append([float(x2)])
arrow_y_parameter.append(float(y2))
return flash_x_parameter,flash_y_parameter,arrow_x_parameter,arrow_y_parameter
# Function to know which Tv show will have more viewers
def more_viewers(x1,y1,x2,y2):
regr1 = linear_model.LinearRegression()
regr1.fit(x1, y1)
predicted_value1 = regr1.predict(9)
print predicted_value1
regr2 = linear_model.LinearRegression()
regr2.fit(x2, y2)
predicted_value2 = regr2.predict(9)
#print predicted_value1
#print predicted_value2
if predicted_value1 > predicted_value2:
print "The Flash Tv Show will have more viewers for next week"
else:
print "Arrow Tv Show will have more viewers for next week"
x1,y1,x2,y2 = get_data('input_data.csv')
#print x1,y1,x2,y2
more_viewers(x1,y1,x2,y2)
可能你能猜出哪個節目會有更多觀眾——但運行一下這個程序看看你猜的對不對�。
3) 替換數據集中的缺失值
有時候��,我們會遇到需要分析包含有缺失值的數據的情況��。有些人會把這些缺失值舍去�,接著分析����;有些人會用最大值����、最小值或平均值替換他們��。平均值是三者中最好的��,但可以用線性回歸來有效地替換那些缺失值���。
這種方法差不多像這樣進行�����。
首先我們找到我們要替換那一列里的缺失值���,并找出缺失值依賴于其他列的哪些數據��。把缺失值那一列作為Y_parameters���,把缺失值更依賴的那些列作為X_parameters�,并把這些數據擬合為線性回歸模型?��,F在就可以用缺失值更依賴的那些列預測缺失的那一列����。
一旦這個過程完成了�,我們就得到了沒有任何缺失值的數據����,供我們自由地分析數據��。
為了練習���,我會把這個問題留給你����,所以請從網上獲取一些缺失值數據�,解決這個問題��。一旦你完成了請留下你的評論���。我很想看看你的結果��。
個人小筆記:
我想分享我個人的數據挖掘經歷��。記得在我的數據挖掘引論課程上��,教師開始很慢��,解釋了一些數據挖掘可以應用的領域以及一些基本概念����。然后突然地�,難度迅速上升�����。這令我的一些同學感到非常沮喪��,被這個課程嚇到�����,終于扼殺了他們對數據挖掘的興趣��。所以我想避免在我的博客文章中這樣做�。我想讓事情更輕松隨意��。因此我嘗試用有趣的例子����,來使讀者更舒服地學習��,而不是感到無聊或被嚇到�。
總結
以上就是本文關于Python編程實現使用線性回歸預測數據的全部內容�����,希望對大家有所幫助����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
