數據分析行業薪資的秘密���,你想知道的都在這里(二)
接上篇:數據分析行業薪資的秘密�����,你想知道的都在這里(1)
第二部分:職位信息清洗及數據提取
數據分析師的收入怎么樣?哪些因素對于數據分析的薪資影響最大?哪些行業對數據分析人才的需求量最高?我想跳槽�,應該選擇大公司大平臺還是初創的小公司?按我目前的教育程度����,工作經驗�����,和掌握的工具和技能���,能獲得什么樣水平的薪資呢?
我們使用python抓取了2017年6月26日拉鉤網站內搜索“數據分析”關鍵詞下的450條職位信息����。通過對這些職位信息的分析和建模來給你答案���。
本系列文章共分為五個部分��,分別是數據分析職位信息抓取�����,數據清洗及預處理��,數據分析職位分布分析���,數據分析薪資影響因素分析�����,以及數據建模和薪資預測�。這是第二篇:職位信息清洗及數據提取���。
第二篇文章是對獲取的數據進行清洗�����,預處理和特征提取�����。在第一篇文章中我們抓取了拉勾網的450條職位信息及職位描述�。但這些信息無法直接用于數據分析���,我們需要對抓取到的信息進行清洗��,規范現有數據的格式����,提取信息中的數據及特征�����,為后續的數據分析和建模做準備���。下面開始介紹苦逼的
數據清洗流程介紹����。
數據清洗前的準備工作
首先是開始前的準備工作���,導入所需要的庫文件���,包括常用的numpy和pandas庫用于計算平均薪資以及對字符進行分列等操作���,正則表達式re庫用于字符的查找和替換操作����,結巴分詞庫jieba用于對職位描述進行分詞操作��,自然語言處理nltk庫用于計算職位描述的文字豐富度指標�,還有KMeans用于對平均
薪資進行聚類操作�����。
-
#導入所需庫文件
-
import re
-
import numpy as np
-
import pandas as pd
-
import jieba as jb
-
import jieba.analyse
-
import jieba.posseg as pseg
-
import nltk
-
from sklearn import preprocessing
-
from sklearn.cluster import KMeans
導入我們之前抓取并保存的數據表�,并查看數據表的維度以及各字段名稱����。后面我們會經常使用這些字段名稱��。
-
#導入之前抓取并保存的數據表
-
lagou=pd.DataFrame(pd.read_csv('lagou_data_analysis_2017-06-26.csv',header=0,encoding='GBK'))
-
-
#查看數據表維度及字段名稱
-
lagou.columns,lagou.shape

職位信息清洗及預處理
開始對職位信息的各個字段進行清洗和預處理����,主要清洗的內容包括文本信息提取和處理��,內容搜索和替換�����,字段內的空格處理���,數值信息提取和計算���,英文字母統一大小寫等等����。我們將先展示清洗前的原始字段�,然后在展示清洗后的新字段內容���。
行業字段清洗及處理
第一個清洗的字段是行業字段�����,抓取到的行業字段比較混亂���,有些只有一個行業名稱��,有些則有兩級的行業名稱��。我們保留行業字段第一部分的信息���,對有兩部分行業名稱的字段取前一個��。
-
#查看原始industryField字段信息
-
-
lagou[['industryField']].head()

由于行業名稱之間有的以頓號分割���,有的以逗號分割����,我們先將所有的分隔符統一為逗號����,然后對這個字段進行分列���。并將分列后的字段重新拼接回原數據表中���。
-
#對industryField字段進行清洗及分列
-
#創建list存儲清洗后的行業字段
-
industry=[]
-
#將頓號分隔符替換為逗號
-
for x in lagou['industryField']:
-
c=x.replace("���、", ",")
-
industry.append(c)
-
#替換后的行業數據改為Dataframe格式
-
industry=pd.DataFrame(industry,columns=["industry"])
-
#對行業數據進行分列
-
industry_s=pd.DataFrame((x.split(',') for x in industry["industry"]),index=industry["industry"].index,columns=['industry_1','industry_2'])
-
#將分列后的行業信息匹配回原數據表
-
lagou=pd.merge(lagou,industry_s,right_index=True, left_index=True)
-
#清除字段兩側空格
-
lagou["industry_1"]=lagou["industry_1"].map(str.strip)
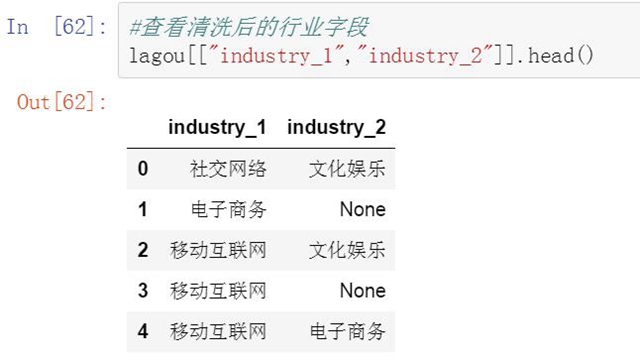
以下是清洗后的行業字段���。
-
#查看清洗后的行業字段
-
-
lagou[["industry_1","industry_2"]].head()
融資階段字段清洗及處理
第二個清洗的字段是融資階段字段�����,抓取下來的原始信息中對融資階段進行了雙重標識�����,例如成長型(A輪)��。由于第一個標識”成長型”定義比較寬泛�,我們提取第二個括號中的標識����。
-
#查看清洗前的financeStage字段
-
-
lagou[['financeStage']].head()

首先建立一個字典��,將數據表中融資階段的每一條信息與字典中的Key進行查找��。如果融資階段信息中包含字典中的任何一個key�����,我們就把這個key對應的value記錄下來���。
-
#提取并處理financeStage中的融資信息
-
#創建一個字典
-
f_dict = {'未融資':'未融資',
-
'天使輪':'天使輪',
-
'A輪':'A輪',
-
'B輪':'B輪',
-
'C輪':'C輪',
-
'D輪':'D輪',
-
'不需要':'不需要融資',
-
'上市公司':'上市公司'
-
}
-
#創建list存儲清洗后的信息
-
financeStage2=[]
-
#逐一提取financeStage字段中的每一條信息
-
for i in range(len(lagou['financeStage'])):
-
#逐一提取字典中的每一條信息
-
for (key, value) in f_dict.items():
-
#判斷financeStage字段中是否包含字典中的任意一個key
-
if key in lagou['financeStage'][i]:
-
#如何包含某個key��,則把對應的value保存在list中
-
financeStage2.append(value)
-
#把新保存的list添加到原數據表中
-
lagou["financeStage1"]=financeStage2
-
#查看清洗后的financeStage字段
-
-
lagou[["financeStage1"]].head()

職位名稱字段清洗及處理
第三個清洗的字段是職位名稱�����,這里我們要提取職位里的title信息���。沒有title信息的都統一歸為其他���。具體方法是將每個職位名稱與現有的title列表逐一判斷���,如果職位名稱中含有title關鍵字就被劃分到這個類別下�。否則被歸為其他類����。
-
#查看清洗前的positionName字段
-
-
lagou[['positionName']].head()

-
#提取并處理positionName中的職位信息
-
#創建list存儲清洗后的信息
-
positionName3=[]
-
#對職位名稱進行判斷歸類
-
for i in range(len(lagou['positionName'])):
-
if '實習' in lagou['positionName'][i]:
-
positionName3.append("實習")
-
elif '助理' in lagou['positionName'][i]:
-
positionName3.append("助理")
-
elif '專員' in lagou['positionName'][i]:
-
positionName3.append("專員")
-
elif '主管' in lagou['positionName'][i]:
-
positionName3.append("主管")
-
elif '經理' in lagou['positionName'][i]:
-
positionName3.append("經理")
-
elif '專家' in lagou['positionName'][i]:
-
positionName3.append("專家")
-
elif '總監' in lagou['positionName'][i]:
-
positionName3.append("總監")
-
elif '工程師' in lagou['positionName'][i]:
-
positionName3.append("工程師")
-
else:
-
#以上關鍵詞都不包含的職位歸為其他
-
positionName3.append("其他")
-
#把新保存的list添加到原數據表中
-
lagou["positionName1"]=positionName3
-
#查看清洗后的positionName字段
-
-
lagou[["positionName1"]].head()

薪資范圍字段清洗及處理
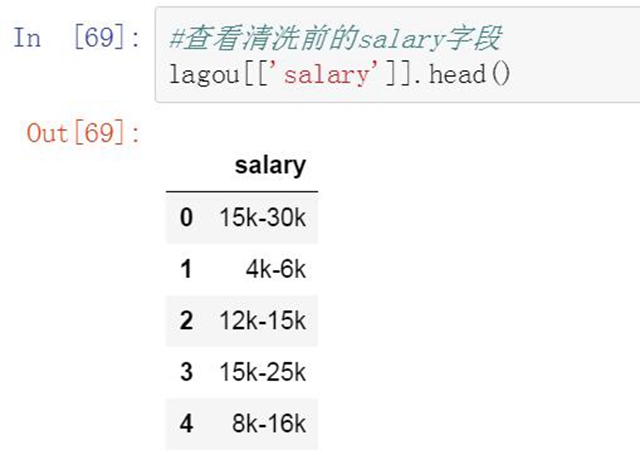
第四個清洗的字段是薪資范圍�����。抓取到的數據中薪資范圍是一個區間值��,比較分散����,無法直接使用����。我們對薪資范圍進行清洗�����,去掉無關的信息并只保留薪資上限和下限兩個數字�����,然后使用這兩個數字計算出平均薪資值�����。
-
#查看清洗前的salary字段
-
-
lagou[['salary']].head()
-
#提取并計算平均薪資
-
#創建list用于存儲信息
-
salary1=[]
-
#對salary字段進行清洗
-
for i in lagou['salary']:
-
#設置要替換的正則表達式k|K
-
p = re.compile("k|K")
-
#按正則表達式對salary字段逐條進行替換(替換為空)
-
salary_date = p.sub("", i)
-
#完成替換的信息添加到前面創建的新list中
-
salary1.append(salary_date)
-
#將清洗后的字段合并到原數據表中
-
lagou['salary1']=salary1
-
#對薪資范圍字段進行分列
-
salary_s=pd.DataFrame((x.split('-') for x in lagou['salary1']),index=lagou['salary1'].index,columns=['s_salary1','e_salary1'])
-
#更改字段格式
-
salary_s['s_salary1']=salary_s['s_salary1'].astype(int)
-
#更改字段格式
-
salary_s['e_salary1']=salary_s['e_salary1'].astype(int)
-
#計算平均薪資
-
-
#創建list用于存儲平均薪資
-
-
salary_avg=[]
-
-
#逐一提取薪資范圍字段
-
-
for i in range(len(salary_s)):
-
-
#對每一條信息字段計算平均薪資��,并添加到平均薪資list中���。
-
-
salary_avg.append((salary_s['s_salary1'][i] + salary_s['e_salary1'][i])/2)
-
-
#將平均薪資拼接到薪資表中
-
-
salary_s['salary_avg']=salary_avg
-
-
#將薪資表與原數據表進行拼接
-
-
lagou=pd.merge(lagou,salary_s,right_index=True, left_index=True)
-
#查看清洗以后的salary_avg字段
-
-
lagou[["salary_avg"]].head()

職位信息中的數據提取
在職位描述字段中���,包含了非常詳細和豐富的信息�。比如數據分析人才的能力要求和對各種數據分析工具的掌握程度等�����。我們對這個字段的一些特征進行指標化�,對有價值的信息進行提取和統計��。
職位描述字段中的數據提取
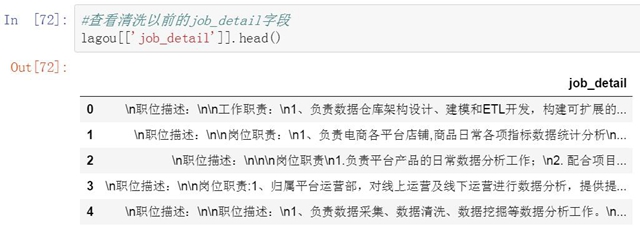
第五個清洗的字段是職位描述���,準確的說從職位描述字段中提取信息�����。職位描述中包含了大量關于職位信息�,工作內容����,和個人能力方面的信息����,非常有價值����。但無法直接拿來使用����。需要進行信息提取�����。我們將對職位描述字段進行三方面的信息提取�����。
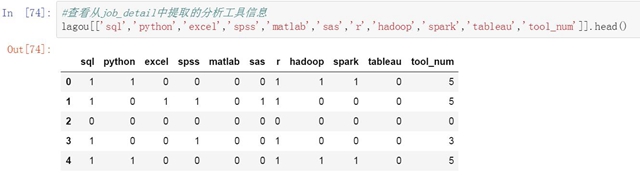
第一是提取職位描述中對于個人能力的要求����,換句話說就是數據分析人員使用工具的能力����。我們整理了10個最常見的數據分析工具�。來看下每個職位描述中都出行了哪些工具名稱�。由于一些工具間存在可替代性�,所以每個職位描述中可能會出現多個工具的名稱���。沒出現一個工具名稱���,我們就會在相應的工具下表示1��,如果沒有出現則標識為0��。
-
#查看清洗以前的job_detail字段
-
-
lagou[['job_detail']].head()
-
#提取職位描述字段�����,并對英文統一轉化為小寫
-
lagou['job_detail']=lagou['job_detail'].map(str.lower)
-
#提取職位描述中的工具名稱
-
tools=['sql','python','excel','spss','matlab','sas','r','hadoop','spark','tableau']
-
#創建list用于存儲數據
-
tool=np.array([[0 for i in range(len(tools))] for j in range(len((lagou['job_detail'])))])
-
#逐一提取職位描述信息
-
for i in range(len(lagou['job_detail'])):
-
#逐一提取工具名稱
-
for t in tools:
-
#獲得工具名稱的索引位置(第幾個工具)
-
index=tools.index(t)
-
#判斷工具名稱是否出現在職位描述中
-
if t in lagou['job_detail'][i]:
-
#如果出現����,在該工具索引位置(列)填1
-
tool[i][index]=1
-
else:
-
#否則在該工具索引位置(列)填0
-
tool[i][index]=0
-
#將獲得的數據轉換為Dataframe格式
-
analytics_tools=pd.DataFrame(tool,columns=tools)
-
#按行(axis=1)對每個職位描述中出現的工具數量進行求和
-
tool_num=analytics_tools.sum(axis=1)
-
#將工具數量求和拼接到原數據表中
-
analytics_tools["tool_num"]=tool_num
-
#將表與原數據表進行拼接
-
lagou=pd.merge(lagou,analytics_tools,right_index=True, left_index=True)
-
#查看從job_detail中提取的分析工具信息
-
-
lagou[['sql','python','excel','spss','matlab','sas','r','hadoop','spark','tableau','tool_num']].head()
職位描述所使用的字數統計
第二是計算職位描述所使用的字數�����,我們猜測初級簡單的工作描述會比較簡單�,而高級復雜的工作描述則會更復雜一些�。因此職位描述中不同的字數里也可能隱藏著某種信息或關聯�����。
-
#計算職位描述的字數
-
#創建list用于存儲新數據
-
jd_num=[]
-
#逐一提取職位描述信息
-
for i in range(len(lagou['job_detail'])):
-
#轉換數據格式(list轉換為str)
-
word_str = ''.join(lagou['job_detail'][i])
-
#對文本進行分詞
-
word_split = jb.cut(word_str)
-
#使用|分割結果并轉換格式
-
word_split1 = "| ".join(word_split)
-
#設置字符匹配正則表達式
-
pattern=re.compile('\w')
-
#查找分詞后文本中的所有字符并賦值給word_w
-
word_w=pattern.findall(word_split1)
-
#計算word_w中字符數量并添加到list中
-
jd_num.append(len(word_w))
-
#對字符數量進行歸一化
-
min_max_scaler = preprocessing.MinMaxScaler()
-
min_max_jd_num = min_max_scaler.fit_transform(jd_num)
-
#將歸一化的數據添加到原數據表中
-
lagou['jd_num']=min_max_jd_num
-
#查看職位描述字數
-
-
jd_num[:10]

-
#查看歸一化的職位描述字段
-
-
lagou[['jd_num']].head()

職位描述的詞匯豐富度統計
第三是計算職位描述中的文字豐富度指標��。和前面的字數統計一樣��。初級職位所對應的工作會相對簡單���,在描述上也會比較簡單�����。高級職位則可能需要更詳細的和負責的描述���。因此文字豐富度指標上也會更高一些�����。
-
#計算職位描述文字豐富度
-
#創建新list用于存儲數據
-
diversity=[]
-
#逐一提取職位描述信息
-
for i in range(len(lagou['job_detail'])):
-
#轉換數據格式(list轉換為str)
-
word_str = ''.join(lagou['job_detail'][i])
-
#將文本中的英文統一轉化為小寫
-
word_str=word_str.lower()
-
#查找職位描述中的所有中文字符
-
word_list=re.findall(r'[\u4e00-\u9fa5]', word_str)
-
#轉換數據格式(list轉換為str)
-
word_str1=''.join(word_list)
-
#對文本進行分詞
-
word_split = jb.cut(word_str1)
-
#使用空格分割結果并轉換格式
-
word_split1 = " ".join(word_split)
-
#使用nltk對句子進行分詞
-
tokens = nltk.word_tokenize(word_split1)
-
#轉化為text對象
-
text = nltk.Text(tokens)
-
#計算職位描述的文字豐富度(唯一詞/所有詞)
-
word_diversity=len(set(text)) / len(text)
-
#將文本詞匯豐富度數據添加到list中
-
diversity.append(word_diversity)
-
#將文字豐富度匹配到原數據表中
-
lagou["diversity"]=diversity
-
#查看職位描述豐富度字段
-
-
lagou[["diversity"]].head()

對數據分析的薪資進行聚類
完成清洗和數據提取后���,平均薪資已經比薪資范圍要具體的多了�����,但仍然比較離散��。我們對這些平均薪資進行聚類來支持后面的建模和預測工作����。以下是具體的代碼和聚類結果�����。我們將類別標簽添加到原始數據表中�。
-
#提取平均工作年限��,平均薪資和平均公司規模字段
-
salary_type = np.array(lagou[['salary_avg']])
-
#進行聚類分析
-
clf=KMeans(n_clusters=3)
-
#訓練模型
-
clf=clf.fit(salary_type)
-
#將距離結果標簽合并到原數據表中
-
lagou['cluster_label']= clf.labels_
-
#輸出聚類結果
-
clf.cluster_centers_

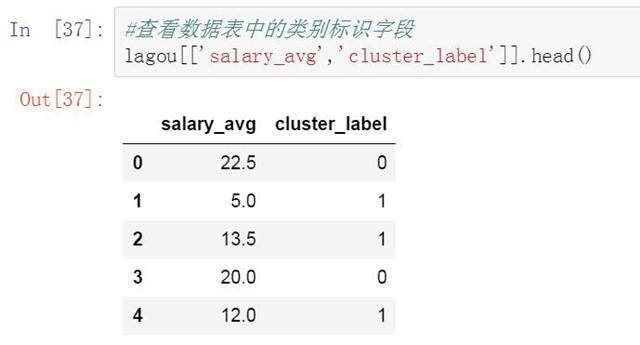
聚類后平均薪資被分為三個類別�����,第1類是薪資均值為19.3K的區間���,分類標記為0�����。第二類是薪資均值為8.2K的區間�����,分類標記為1,����。第三類是薪資均值為32.1的區間���,分類標記為3����。
-
#對平均薪資進行聚類預測
-
clf.predict(9),clf.predict(25),clf.predict(30)

-
#查看數據表中的類別標識字段
-
-
lagou[['salary_avg','cluster_label']].head()
查看清洗及處理后的數據表
到這里我們完成了對450個職位信息的字段清洗和數據提取工作�����。下面我們再來查看下數據表的維度���,名稱以及數據表中的數據�。在下一篇文章中我們將使用這個數據表對數據分析職位的分布情況以及薪資的影響因素進行分析�,并通過建模對薪資收入進行預測�。
-
#查看數據表維度及字段名稱
-
-
lagou.columns,lagou.shape

-
#查看清洗完的數據表
-
-
lagou.head()
本篇文章我們對抓取到的職位信息進行了清洗和數據提取����。數據清洗是一個苦逼的工作�����,但卻是分析和建模過程中必不可少的一個步驟�����。經過清洗后我們就可以對職位數據進行分析和建模了�,后面的文章中我們將從職位需求分布和薪資影響因素兩個方面進行分析���,并在最后對數據分析行業的薪資進行建模�����,對薪資分類和具體的薪資值進行預測���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
