常用排序算法比較與分析
一���、常用排序算法簡述
下面主要從排序算法的基本概念�、原理出發,分別從算法的時間復雜度��、空間復雜度���、算法的穩定性和速度等方面進行分析比較����。依據待排序的問題大小(記錄數量 n)的不同���,排序過程中需要的存儲器空間也不同����,由此將排序算法分為兩大類:【內排序】���、【外排序】�。
內排序:指排序時數據元素全部存放在計算機的隨機存儲器RAM中����。
外排序:待排序記錄的數量很大����,以致內存一次不能容納全部記錄��,在排序過程中還需要對外存進行訪問的排序過程�。
先了解一下常見排序算法的分類關系(見圖1-1)
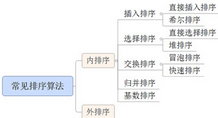
圖1-1 常見排序算法
二���、內排序相關算法
2.1 插入排序
核心思想:將一個待排序的數據元素插入到前面已經排好序的數列中的適當位置��,使數據元素依然有序���,直到待排序數據元素全部插入完為止��。
2.1.1 直接插入排序
核心思想:將欲插入的第i個數據元素的關鍵碼與前面已經排序好的i-1��、i-2 ���、i-3�����、 … 數據元素的值進行順序比較��,通過這種線性搜索的方法找到第i個數據元素的插入位置 ����,并且原來位置 的數據元素順序后移�����,直到全部排好順序��。
直接插入排序中����,關鍵詞相同的數據元素將保持原有位置不變�,所以該算法是穩定的�,時間復雜度的最壞值為平方階O(n2)����,空間復雜度為常數階O(l)�。
Python源代碼:
-
#-------------------------直接插入排序--------------------------------
-
def insert_sort(data_list):
-
#遍歷數組中的所有元素����,其中0號索引元素默認已排序�,因此從1開始
-
for x in range(1, len(data_list)):
-
#將該元素與已排序好的前序數組依次比較�����,如果該元素小���,則交換
-
#range(x-1,-1,-1):從x-1倒序循環到0
-
for i in range(x-1, -1, -1):
-
#判斷:如果符合條件則交換
-
if data_list[i] > data_list[i+1]:
-
temp = data_list[i+1]
-
data_list[i+1] = data_list[i]
-
data_list[i] = temp
2.1.2 希爾排序
核心思想:是把記錄按下標的一定增量分組����,對每組使用直接插入排序算法排序;隨著增量逐漸減少����,每組包含的關鍵詞越來越多����,當增量減至1時��,整個文件恰被分成一組����,算法便終止�����。
希爾排序時間復雜度會比O(n2)好一些�,然而��,多次插入排序中��,第一次插入排序是穩定的�,但在不同的插入排序過程中�����,相同的元素可能在各自的插入排序中移動����,所以希爾排序是不穩定的�����。
Python源代碼:
-
#-------------------------希爾排序-------------------------------
-
def insert_shell(data_list):
-
#初始化step值�����,此處利用序列長度的一半為其賦值
-
group = int(len(data_list)/2)
-
#第一層循環:依次改變group值對列表進行分組
-
while group > 0:
-
#下面:利用直接插入排序的思想對分組數據進行排序
-
#range(group,len(data_list)):從group開始
-
for i in range(group, len(data_list)):
-
#range(x-group,-1,-group):從x-group開始與選定元素開始倒序比較�����,每個比較元素之間間隔group
-
for j in range(i-group, -1, -group):
-
#如果該組當中兩個元素滿足交換條件��,則進行交換
-
if data_list[j] > data_list[j+group]:
-
temp = data_list[j+group]
-
data_list[j+group] = data_list[j]
-
data_list[j] = temp
-
#while循環條件折半
-
group = int(group / 2)
2.2 選擇排序
核心思想:每一趟掃描時����,從待排序的數據元素中選出關鍵碼最小或最大的一個元素�����,順序放在已經排好順序序列的最后�,直到全部待排序的數據元素排完為止���。
2.2.1 直接選擇排序
核心思想:給每個位置選擇關鍵碼最小的數據元素���,即:選擇最小的元素與第一個位置的元素交換�,然后在剩下的元素中再選擇最小的與第二個位置的元素交換���,直到倒數第二個元素和最后一個元素比較為止�����。
根據其基本思想���,每當掃描一趟時���,如果當前元素比一個元素小�,而且這個小元素又出現在一個和當前元素相等的元素后面�����,則它們的位置發生了交換���,所以直接選擇排序時不穩定的��,其時間復雜度為平方階O(n2)�,空間復雜度為O(l)�。
Python源代碼:
-
#-------------------------直接選擇排序-------------------------------
-
def select_sort(data_list):
-
#依次遍歷序列中的每一個元素
-
for i in range(0, len(data_list)):
-
#將當前位置的元素定義此輪循環當中的最小值
-
minimum = data_list[i]
-
#將該元素與剩下的元素依次比較尋找最小元素
-
for j in range(i+1, len(data_list)):
-
if data_list[j] < minimum:
-
temp = data_list[j];
-
data_list[j] = minimum;
-
minimum = temp
-
#將比較后得到的真正的最小值賦值給當前位置
-
data_list[i] = minimum
2.2.2 堆排序
堆排序時對直接選擇排序的一種有效改進�����。
核心思想:將所有的數據建成一個堆�,最大的數據在堆頂�,然后將堆頂的數據元素和序列的最后一個元素交換;接著重建堆���、交換數據�,依次下去���,從而實現對所有的數據元素的排序����。完成堆排序需要執行兩個動作:建堆和堆的調整����,如此反復進行��。
堆排序有可能會使得兩個相同值的元素位置發生互換����,所以是不穩定的����,其平均時間復雜度為0(nlog2n)��,空間復雜度為O(l)����。
Python源代碼:
-
#-------------------------堆排序--------------------------------
-
#**********獲取左右葉子節點**********
-
def LEFT(i):
-
return 2*i + 1
-
-
def RIGHT(i):
-
return 2*i + 2
-
-
#********** 調整大頂堆 **********
-
#data_list:待調整序列 length: 序列長度 i:需要調整的結點
-
def adjust_max_heap(data_list,length,i):
-
#定義一個int值保存當前序列最大值的下標
-
largest = i
-
#執行循環操作:兩個任務:1 尋找最大值的下標��;2.最大值與父節點交換
-
while 1:
-
#獲得序列左右葉子節點的下標
-
left, right = LEFT(i), RIGHT(i)
-
#當左葉子節點的下標小于序列長度 并且 左葉子節點的值大于父節點時���,將左葉子節點的下標賦值給largest
-
if (left < length) and (data_list[left] > data_list[i]):
-
largest = left
-
#print('左葉子節點')
-
else:
-
largest = i
-
#當右葉子節點的下標小于序列長度 并且 右葉子節點的值大于父節點時�����,將右葉子節點的下標值賦值給largest
-
if (right < length) and (data_list[right] > data_list[largest]):
-
largest = right
-
#print('右葉子節點')
-
#如果largest不等于i 說明當前的父節點不是最大值��,需要交換值
-
if (largest != i):
-
temp = data_list[i]
-
data_list[i] = data_list[largest]
-
data_list[largest] = temp
-
i = largest
-
#print(largest)
-
continue
-
else:
-
break
-
-
#********** 建立大頂堆 **********
-
def build_max_heap(data_list):
-
length = len(data_list)
-
for x in range(int((length-1)/2),-1,-1):
-
adjust_max_heap(data_list,length,x)
-
-
#********** 堆排序 **********
-
def heap_sort(data_list):
-
#先建立大頂堆����,保證最大值位于根節點��;并且父節點的值大于葉子結點
-
build_max_heap(data_list)
-
#i:當前堆中序列的長度.初始化為序列的長度
-
i = len(data_list)
-
#執行循環:1. 每次取出堆頂元素置于序列的最后(len-1,len-2,len-3...)
-
# 2. 調整堆��,使其繼續滿足大頂堆的性質�,注意實時修改堆中序列的長度
-
while i > 0:
-
temp = data_list[i-1]
-
data_list[i-1] = data_list[0]
-
data_list[0] = temp
-
#堆中序列長度減1
-
i = i-1
-
#調整大頂堆
-
adjust_max_heap(data_list, i, 0)
2.3交換排序
核心思想:顧名思義��,就是一組待排序的數據元素中�����,按照位置的先后順序相互比較各自的關鍵碼�����,如果是逆序���,則交換這兩個數據元素�����,直到該序列數據元素有序為止���。
2.3.1 冒泡排序
核心思想:對于待排序的一組數據元素��,把每個數據元素看作有重量的氣泡����,按照輕氣泡不能在重氣泡之下的原則�,將未排好順序的全部元素自上而下的對相鄰兩個元素依次進行比較和調整���,讓較重的元素往下沉����,較輕的往上冒����。
根據基本思想�,只有在兩個元素的順序與排序要求相反時才將調換它們的位置�����,否則保持不變��,所以冒泡排序時穩定的����。時間復雜度為平方階O(n2)���,空間復雜度為O(l)����。
Python源代碼:
-
#-------------------------冒泡排序--------------------------------
-
def bubble_sort(data_list):
-
length = len(data_list)
-
#序列長度為length����,需要執行length-1輪交換
-
for x in range(1,length):
-
#對于每一輪交換�����,都將序列當中的左右元素進行比較
-
#每輪交換當中�,由于序列最后的元素一定是最大的����,因此每輪循環到序列未排序的位置即可
-
for i in range(0,length-x):
-
if data_list[i] > data_list[i+1]:
-
temp = data_list[i]
-
data_list[i] = data_list[i+1]
-
data_list[i+1] = temp
2.3.2 快速排序
快速排序是對冒泡排序本質上的改進�。
核心思想:是一個就地排序�,分而治之����,大規模遞歸的算法�。即:通過一趟掃描后確?����;鶞庶c的這個數據元素的左邊元素都比它小�、右邊元素都比它大���,接著又以遞歸方法處理左右兩邊的元素��,直到基準點的左右只有一個元素為止�����。
快速排序時一個不穩定的算法�����,其最壞值的時間復雜度為平方階O(n2)�����,空間復雜度為O(log2n)���。
Python源代碼:
-
#-------------------------快速排序--------------------------------
-
#data_list:待排序的序列�;start排序的開始index,end序列末尾的index
-
#對于長度為length的序列:start = 0;end = length-1
-
def quick_sort(data_list,start,end):
-
if start < end:
-
i , j , pivot = start, end, data_list[start]
-
while i < j:
-
#從右開始向左尋找第一個小于pivot的值
-
while (i < j) and (data_list[j] >= pivot):
-
j = j-1
-
#將小于pivot的值移到左邊
-
if (i < j):
-
data_list[i] = data_list[j]
-
i = i+1
-
#從左開始向右尋找第一個大于pivot的值
-
while (i < j) and (data_list[i] < pivot):
-
i = i+1
-
#將大于pivot的值移到右邊
-
if (i < j):
-
data_list[j] = data_list[i]
-
j = j-1
-
#循環結束后����,說明 i=j�����,此時左邊的值全都小于pivot,右邊的值全都大于pivot
-
#pivot的位置移動正確�����,那么此時只需對左右兩側的序列調用此函數進一步排序即可
-
#遞歸調用函數:依次對左側序列:從0 ~ i-1//右側序列:從i+1 ~ end
-
data_list[i] = pivot
-
#左側序列繼續排序
-
quick_sort(data_list,start,i-1)
-
#右側序列繼續排序
-
quick_sort(data_list,i+1,end)
2.4歸并排序
核心思想:把數據序列遞歸地分成短序列�,即把1分成2����、2分成4���、依次分解��,當分解到只有1個一組的時候排序這些分組��,然后依次合并回原來的序列��,不斷合并直到原序列全部排好順序����。
合并過程中可以確保兩個相等的當前元素中�����,把處在前面的元素保存在結果序列的前面����,因此歸并排序是穩定的���,其時間復雜度為O(nlog2n)�����,空間復雜度為O(n)�。
Python源代碼:
-
#-------------------------歸并排序--------------------------------
-
#這是合并的函數
-
# 將序列data_list[first...mid]與序列data_list[mid+1...last]進行合并
-
def mergearray(data_list,first,mid,last,temp):
-
#對i,j,k分別進行賦值
-
i,j,k = first,mid+1,0
-
#當左右兩邊都有數時進行比較�����,取較小的數
-
while (i <= mid) and (j <= last):
-
if data_list[i] <= data_list[j]:
-
temp[k] = data_list[i]
-
i = i+1
-
k = k+1
-
else:
-
temp[k] = data_list[j]
-
j = j+1
-
k = k+1
-
#如果左邊序列還有數
-
while (i <= mid):
-
temp[k] = data_list[i]
-
i = i+1
-
k = k+1
-
#如果右邊序列還有數
-
while (j <= last):
-
temp[k] = data_list[j]
-
j = j+1
-
k = k+1
-
#將temp當中該段有序元素賦值給data_list待排序列使之部分有序
-
for x in range(0,k):
-
data_list[first+x] = temp[x]
-
# 這是分組的函數
-
def merge_sort(data_list,first,last,temp):
-
if first < last:
-
mid = (int)((first + last) / 2)
-
#使左邊序列有序
-
merge_sort(data_list,first,mid,temp)
-
#使右邊序列有序
-
merge_sort(data_list,mid+1,last,temp)
-
#將兩個有序序列合并
-
mergearray(data_list,first,mid,last,temp)
-
# 歸并排序的函數
-
def merge_sort_array(data_list):
-
#聲明一個長度為len(data_list)的空列表
-
temp = len(data_list)*[None]
-
#調用歸并排序
-
merge_sort(data_list,0,len(data_list)-1,temp)
2.5 基數排序
核心思想:首先是低位排序�����,然后收集;其次是高位排序���,然后再收集;依次類推�,直到最高位����。
Python源代碼:
-
#-------------------------基數排序--------------------------------
-
#確定排序的次數
-
#排序的順序跟序列中最大數的位數相關
-
def radix_sort_nums(data_list):
-
maxNum = data_list[0]
-
#尋找序列中的最大數
-
for x in data_list:
-
if maxNum < x:
-
maxNum = x
-
#確定序列中的最大元素的位數
-
times = 0
-
while (maxNum > 0):
-
maxNum = (int)(maxNum/10)
-
times = times+1
-
return times
-
#找到num從低到高第pos位的數據
-
def get_num_pos(num,pos):
-
return ((int)(num/(10**(pos-1))))%10
-
#基數排序
-
def radix_sort(data_list):
-
count = 10*[None] #存放各個桶的數據統計個數
-
bucket = len(data_list)*[None] #暫時存放排序結果
-
#從低位到高位依次執行循環
-
for pos in range(1,radix_sort_nums(data_list)+1):
-
#置空各個桶的數據統計
-
for x in range(0,10):
-
count[x] = 0
-
#統計當前該位(個位���,十位�����,百位....)的元素數目
-
for x in range(0,len(data_list)):
-
#統計各個桶將要裝進去的元素個數
-
j = get_num_pos(int(data_list[x]),pos)
-
count[j] = count[j]+1
-
#count[i]表示第i個桶的右邊界索引
-
for x in range(1,10):
-
count[x] = count[x] + count[x-1]
-
#將數據依次裝入桶中
-
for x in range(len(data_list)-1,-1,-1):
-
#求出元素第K位的數字
-
j = get_num_pos(data_list[x],pos)
-
#放入對應的桶中����,count[j]-1是第j個桶的右邊界索引
-
bucket[count[j]-1] = data_list[x]
-
#對應桶的裝入數據索引-1
-
count[j] = count[j]-1
-
# 將已分配好的桶中數據再倒出來����,此時已是對應當前位數有序的表
-
for x in range(0,len(data_list)):
-
data_list[x] = bucket[x]
三�、排序算法實測
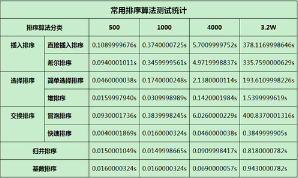
圖3-1 常用排序算法測試統計
四��、排序算法對比與分析
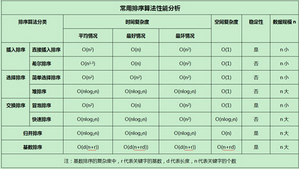
表4-1各個排序算法比較
[直接插入排序]是對冒泡排序的改進�����,比冒泡排序快��,但是只適用于數據量較小(1000 ) 的排序
[希爾排序]比較簡單�,適用于小數據量(5000以下)的排序��,比直接插入排序快��、冒泡排序快���,因此��,希爾排序適用于小數據量的����、排序速度要求不高的排序�����。
[直接選擇排序]和冒泡排序算法一樣��,適用于n值較小的場合��,而且是排序算法發展的初級階段�����,在實際應用中采用的幾率較小����。
[堆排序]比較適用于數據量達到百萬及其以上的排序�����,在這種情況下�����,使用遞歸設計的快速排序和歸并排序可能會發生堆棧溢出的現象��。
[冒泡排序]是最慢的排序算法��,是排序算法發展的初級階段�����,實際應用中采用該算法的幾率比較小�。
[快速排序]是遞歸的�����、速度最快的排序算法���,但是在內存有限的情況下不是一個好的選擇;而且�����,對于基本有序的數據序列排序���,快速排序反而變得比較慢�。
[歸并排序]比堆排序要快�����,但是需要的存儲空間增加一倍���。
[基數排序]適用于規模n值很大的場合��,但是只適用于整數的排序�����,如果對浮點數進行基數排序����,則必須明確浮點數的存儲格式��,然后通過某種方式將其映射到整數上��,最后再映射回去�����,過程復雜����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
