什么是列聯表
列聯表又稱交互分類表�����,所謂交互分類���,是指同時依據兩個變量的值���,將所研究的個案分類���。交互分類的目的是將兩變量分組�����,然后比較各組的分布狀況���,以尋找變量間的關系��。
這里是按兩個變量交叉分類的���,該列聯表稱為兩維列聯表���,若按3個變量交叉分類��,所得的列聯表稱為3維列聯表���,依次類推��。3維及以上的列聯表通常稱為“多維列聯表”或“高維列聯表”��,而一維列聯表就是頻數分布表��。
列聯表的結構

二維列聯表

r * c 列聯表
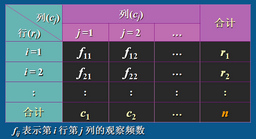
觀察值的分布
百分比分布

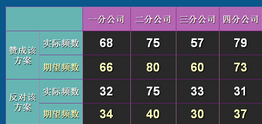
期望頻數的分布

假設檢驗
獨立性檢驗
假設觀察頻數與期望頻數沒有差別���,而統計量χ2值表示二者間的偏離程度��。

相關系數
ψ相關系數

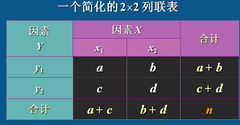


皮爾遜定義的列聯系數

V相關系數

Fisher精確檢驗
卡方統計量是近似的��,而Fisher精確檢驗使用的是超幾何分布���。
相對危險度(Relative Risk, RR)
參考下面的SPSS實例
優勢比(Odds Ratio, OR)
參考下面的SPSS實例
Kappa一致性檢驗
在數據分析中����,比較兩種預測方法預測結果的一致性用到Kappa檢驗�。
配對χ2檢驗
通過Kappa檢驗���,解決了兩種測量間究竟有無關聯的問題�����,但是通過列聯表的觀察�����,發現兩位顧問的評價是否不太一致���,這種假設又如何來加以分析呢���?
McNemar配對χ2檢驗 就是經典的配對檢驗�,專門用于解決這類問題����。
分層χ2檢驗
分層χ2檢驗是把研究對象分解成不同層次��,按各層對象來進行行變量與列變量的獨立性研究�����。Statistics中Cochran’s and Mantel-Haenszel statistics會自動給出結果��。
分層χ2檢驗是一種很好的控制其他因素的方法��,使分析者能得到更準確的結果��。如果數據量足夠大 �,還可以引入更多的分層因素加以控制�����。 但是�����,和SAS中的CMH χ2不同����,SPSS提供的CMH χ2檢驗只能進行二分類變量的檢驗�����,而不能進行多分類變量的檢驗�����。
檢驗比較
χ2檢驗
假設觀察頻數與期望頻數沒有差別���,而統計量χ2值表示二者間的偏離程度����。
卡方檢驗方法的適用條件

關聯程度的度量
χ2檢驗從定性的角度分析是否存在相關行����,而各種關聯指標(相對危險度RR與優勢比OR)從定量的角度分析相關的程度如何�����。
Kappa一致性檢驗與配對χ2檢驗
Kappa一致性檢驗對兩種方法結果的一致程度進行評價����,而配對χ2檢驗則用于分析兩種分類方法的分類結果是否有差異���。
分層χ2檢驗
分層χ2檢驗是把研究對象分解成不同層次���,按各層對象來進行行變量與列變量的獨立性研究����。Statistics中Cochran’s and Mantel-Haenszel statistics會自動給出結果���。
SPSS分析
菜單
Analyze -> Descriptive Statistics -> Crosstabs
實例一:卡方檢驗和風險評估
數據集(site.sav)
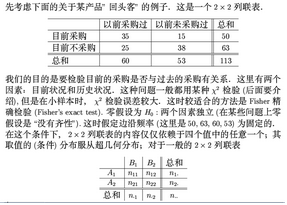
某公司實行數據庫營銷��,其雜志銷售部每個月向數據庫中的人們發送征訂郵件�����,但是回應率極低����。他們希望找到一種好的方法來定位潛在的客戶���,只向這些客戶發放郵件���,從而節省人力物力���。數據庫中的資料包括:個人一般信息(年齡�、性別��、婚姻狀況�、收入���、受教育水平及是否退休等)�,個人行為特征(主要交通工具�、有無手機�、呼機�、電視����、CD及是否訂閱報紙)�。另外���,在發送郵件后����,還有一個變量也加入到了數據庫中:是否對郵件進行回應��,即是否在郵件的提示性進行雜志購買�。經研究發現����,報紙訂閱與郵件發送有相關性�����。該部門經理想了解報紙訂閱者回應郵件的概率是非訂閱者的幾倍�����。
參數設置
統計量
結果分析
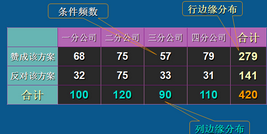
交叉制表

列聯表分析表明���,并沒有太多人對雜志的郵件做出回應�,但是其中訂閱人占了較大比例����。
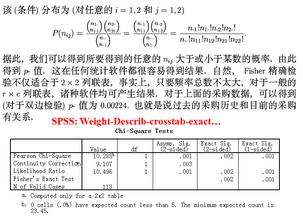
卡方檢驗

p值為0.000����,故認為訂閱報紙與郵件回應是相關的�。那么報紙訂閱者的回應概率是未訂閱者的多少倍呢�?通過計算RR來解決�。
風險估計

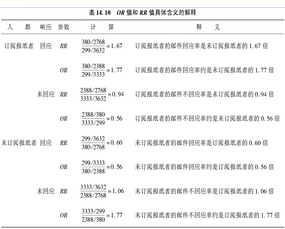
對于報紙訂閱者而言��,郵件響應的相對危險度是其回應概率與非報紙訂閱者的回應概率的比值�����,其估計值是(380/2768) /
(299/3632) = 13.7% / 8.2%=1.668�����,表明報紙訂閱者對郵件的響應概率是非報紙訂閱者的1.668倍���。
或者說報紙訂閱者對郵件的無響應的概率是非報紙訂閱者的0.94倍��。
而優勢比即一個事件的Odds Ratio是它發生的概率除以不發生的概率
實例二:Kappa一致性檢驗和配對卡方檢驗
數據集(site.sav)
某公司期望擴展業務����,增開幾家分店�,但對開店地址不太確定��。于是選了20個地址����,請兩位資深顧問分別對20個地址作了一個評價��,把它們評為好�、中��、差三個等級�����,以便確定應對哪些地址進行更進一步調查�����,那么這兩位資深顧問的評價結果是否一致���。
參數設置
統計量
結果分析
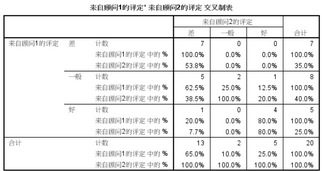
交叉制表
Kappa一致性檢驗

Kappa檢驗的原假設:Kappa=0�����,即兩者完全無關�����。結果顯示Kappa=0.478���,P<0.05�����,拒絕原假設����,認為兩位顧問的評價結果存在一致性��。
配對卡方檢驗
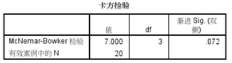
Kappa一致性檢驗對兩種方法結果的一致程度進行評價��,而配對χ2檢驗則用于分析兩種分類方法的分類結果是否有差異�����。
此處原假設:兩顧問的評價結果無差別��,而p=0.072>0.05�,故接受原假設���,認為基本上相同
實例三:分層卡方檢驗
數據集(cmh.sav)
某零售連鎖店對3家分店的客戶滿意度進行了調查�,數據見cmh.sav�����,其中一項指標是在購物時是否經常向店員尋求幫助�����,現希望分析尋求幫助與性別有無聯系�����。
統計結果
未分層的卡方檢驗
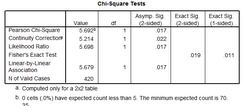
將gender和contact分別作為行變量和列變量����,并做χ2檢驗�����,p<0.05����,認為兩者間有聯系�����。
因為每家分店的結果可能不一樣�����,上面的卡方檢驗收到分店因素的影響可能不準確��,需要根據分店進行分層統計�����。
但是分層因素在幾個組之間的分布不均����,既可能削弱了原本存在的行變量與列變量間的關系�����,也可能使得原本不存在關系的兩個變量關系呈現統計學顯著性��。
按分店分層卡方檢驗
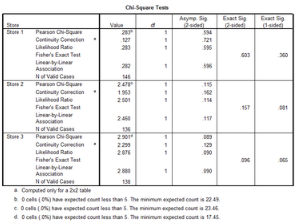
可以看到分店的卡方檢驗并無顯著性(p > 0.05)����,說明每個分店的尋求幫助與性別之間沒有強關聯����。
但是���,由于分層后樣本量大大減小���,這究竟是因為檢驗效能不足導致的無差異��,還是真的無差異�����?
為此可以使用Cochran’s and Mantel-Haenszel χ2檢驗來分析����。這種方法可以在考慮了分層因素的影響后給出檢驗結果����。
Cochran’s and Mantel-Haenszel χ2檢驗
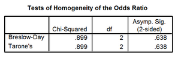
首先給出的是層間差異的檢驗����,即考察不同層間gender與contact的聯系是否相同����。
原假設H0: 分店之間的聯系是相同的����。
p = 0.638說明���,在不同分店層間�����, gender與contact的聯系是相同的�。
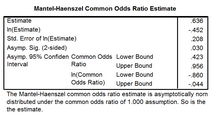
調整了分層因素作用后的綜合OR值=0.636�����,即去除了不同分店的混雜效應后�����,和女性相比���,男性顧客尋求幫助的優勢比為0.636����,或者說更不容易尋求幫助����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
