主成分分析�����、因子分析��、聚類的概覽與比較
主成分分析:利用降維(線性變換)的思想�,在損失很少信息的前提下把多個指標轉化為幾個綜合指標(主成分)�����,用綜合指標來解釋多變量的方差——協方差結構�,即每個主成分都是原始變量的線性組合�,且各主成分之間互不相關�����,使得主成分比原始變量具有某些更優越的性能(主成分必須保留原始變量90%以上的信息)���,從而達到簡化系統結構�,抓住問題實質的目的綜合指標即為主成分�。
求解主成分的方法:從協方差陣出發(協方差陣已知)����,從相關陣出發(相關陣R已知)��。
(實際研究中��,總體協方差陣與相關陣是未知的����,必須通過樣本數據來估計)
注意事項:
1.由協方差陣出發與由相關陣出發求解主成分所得結果不一致時�����,要恰當的選取某一種方法���;
2.對于度量單位或是取值范圍在同量級的數據���,可直接求協方差陣���;對于度量單位不同的指標或是取值范圍彼此差異非常大的指標��,應考慮將數據標準化���,再由協方差陣求主成分��;
3.主成分分析不要求數據來源于正態分布���;
4.在選取初始變量進入分析時應該特別注意原始變量是否存在多重共線性的問題(最小特征根接近于零���,說明存在多重共線性問題)�����。
優點:首先它利用降維方法用少數幾個綜合變量來代替原始多個變量����,這些綜合變量集中了原始變量的大部分信息����。其次它通過計算綜合主成分函數得分���,對客觀經濟現象進行科學評價����。再次它在應用上側重于信息貢獻影響力綜合評價���。
缺點:當主成分的因子負荷的符號有正有負時�����,綜合評價函數意義就不明確�����,命名清晰性低����。
聚類分析:將個體(樣品)或者對象(變量)按相似程度(距離遠近)劃分類別����,使得同一類中的元素之間的相似性比其他類的元素的相似性更強��。目的在于使類間元素的同質性最大化和類與類間元素的異質性最大化�。
其主要依據是聚到同一個數據集中的樣本應該彼此相似��,而屬于不同組的樣本應該足夠不相似��。
常用聚類方法:系統聚類法�����,K-均值法�,模糊聚類法���,有序樣品的聚類��,分解法�,加入法����。
注意事項:
1.系統聚類法可對變量或者記錄進行分類�,K-均值法只能對記錄進行分類�;
2. K-均值法要求分析人員事先知道樣品分為多少類���;
3.對變量的多元正態性��,方差齊性等要求較高�����。
應用領域:細分市場�,消費行為劃分�����,設計抽樣方案等
優點:聚類分析模型的優點就是直觀�����,結論形式簡明��。
缺點:在樣本量較大時�����,要獲得聚類結論有一定困難����。由于相似系數是根據被試的反映來建立反映被試間內在聯系的指標�,而實踐中有時盡管從被試反映所得出的數據中發現他們之間有緊密的關系��,但事物之間卻無任何內在聯系�,此時��,如果根據距離或相似系數得出聚類分析的結果����,顯然是不適當的��,但是�����,聚類分析模型本身卻無法識別這類錯誤�����。
因子分析:利用 降維思想����,由研究原始變量相關矩陣內部的依賴關系出發�,把一些具有錯綜復雜關系的變量歸結為少數幾個綜合因子��。因子分析是主成分的推廣��,相對于主成分分析��,更傾向于描述原始變量之間的相關關系�����,就是研究如何以最少的信息丟失����,將眾多原始變量濃縮成少數幾個因子變量�����,以及如何使因子變量具有較強的可解釋性的一種多元統計分析方法��。
求解因子載荷的方法:主成分法����,主軸因子法����,極大似然法�����,最小二乘法����,a因子提取法�����。
注意事項:
因子分析中各個公共因子之間不相關��,特殊因子之間不相關��,公共因子和特殊因子之間不相關����。(均不相關)
應用領域:解決共線性問題��,評價問卷的結構效度����,尋找變量間潛在的結構����,內在結構證實����。
優點:1)它不是對原有變量的取舍�����,而是根據原始變量的信息進行重新組合�,找出影響變量的共同因子��,化簡數據�����;2)它通過旋轉使得因子變量更具有可解釋性����,命名清晰性高�����。
缺點:在計算因子得分時�,采用的是最小二乘法�����,此法有時可能會失效�。
判別分析:從已知的各種分類情況中總結規律(訓練出判別函數)���,當新樣品進入時��,判斷其與判別函數之間的相似程度�����。
判別準則:概率最大��,距離最近���,離差最小等�。
常用判別方法:最大似然法��,距離判別法�,Fisher判別法��,Bayes判別法����,逐步判別法等�����。
注意事項:
1.判別分析的基本條件:分組類型在兩組以上����,解釋變量必須是可測的��;
2.每個解釋變量不能是其它解釋變量的線性組合(比如出現多重共線性情況時�����,判別權重會出現問題)�����;
3.各 解釋變量之間服從多元正態分布(不符合時����,可使用Logistic回歸替代)��,且各組解釋變量的協方差矩陣相等(各組 協方方差矩陣有顯著差異時����,判別函數不相同)�����。
4.相對而言���,即使判別函數違反上述適用條件���,也很穩健�,對結果影響不大����。
應用領域:對客戶進行信用預測�����,尋找潛在客戶(是否為消費者�����,公司是否成功���,學生是否被錄用等等)����,臨床上用于鑒別診斷�。
對應分析/最優尺度分析:利用降維思想以達到簡化數據結構的目的���,同時對數據表中的行與列 進行處理�,尋求以低維圖形表示數據表中行與列之間的關系�����。
對應分析:用于展示變量(兩個/多個分類)間的關系(變量的分類數較多時較佳)���;
最優尺度分析:可同時分析多個變量間的關系���,變量的類型可以是無序多分類�����,有序多分類或連續性變量��,并對多選題的分析提供了支持�。
典型相關分析:借用主成分分析 降維思想��,分別對兩組變量提取主成分����,且使從兩組變量提取的主成分之間的相關程度達到最大��,而從同一組內部提取的各主成分之間互不相關�。
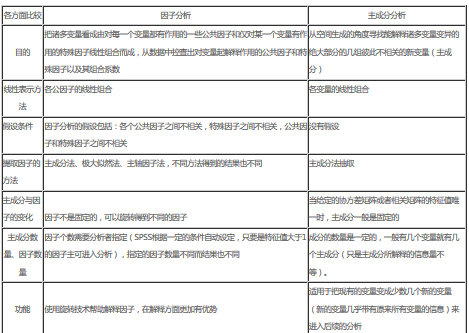
相同點:
1.主成分分析法和因子分析法都是用少數的幾個變量(因子)
來綜合反映原始變量(因子)的主要信息��,變量雖然較原始變量少�,但所包含的信息量卻占原始信息的85
%以上��,所以即使用少數的幾個新變量���,可信度也很高����,也可以有效地解釋問題�����。并且新的變量彼此間互不相關����,消除了多重共線性��。
2.這兩種分析法得出的新變量�,并不是原始變量篩選后剩余的變量��。在主成分分析中���,最終確定的新變量是原始變量的線性組合��,如原始變量為x1
�����,x2 ���,. . . �,x3 �,經過坐標變換���,將原有的p個相關變量xi 作線性變換�,每個主成分都是由原有p個變量線性組合得到�。在諸多主成分Zi
中����,Z1 在方差中占的比重最大��,說明它綜合原有變量的能力最強��,越往后主成分在方差中的比重也小�����,綜合原信息的能力越弱��。
因子分析是要利用少數幾個公共因子去解釋較多要觀測變量中存在的復雜關系�,它不是對原始變量的重新組合�,而是對原始變量進行分解����,分解為公共因子與特殊因子兩部分�����。公共因子是由所有變量共同具有的少數幾個因子�����;特殊因子是每個原始變量獨自具有的因子��。
3.對新產生的主成分變量及因子變量計算其得分�,就可以將主成分得分或因子得分代替原始變量進行進一步的分析����,因為主成分變量及因子變量比原始變量少了許多����,所以起到了降維作用����。
4.聚類分析是把研究對象視作多維空間中的許多點���,并合理地分成若干類�����,因此它是一種根據變量域之間的相似性而逐步歸群成類的方法����,它能客觀地反映這些變量或區域之間的內在組合關系�。它是通過一個大的對稱矩陣來探索相關關系的一種數學分析方法�����,是多元統計分析方法���,分析的結果為群集���。對向量聚類后���,我們對數據的處理難度也自然降低���,所以從某種意義上說�����,聚類分析也起到了降維作用���。
不同之處:
1.主成分分析是求出少數幾個主成分(變量) 通過少數幾個主成分來解釋多變量的方差——協方差結構的分析方法��,使它們盡可能多地保留原始變量的信息��,且彼此不相關�。它是一種把給定的一組變量通過線性變換��,轉換為一組不相關的變量(兩兩相關系數為0 ����,或樣本向量彼此相互垂直的隨機變量)的數學變換方法�。在這種變換中�,保持變量的總方差(方差之和) 不變����,同時具有最大方差���,稱為第一主成分�����;具有次大方差����,稱為第二主成分�。依次類推�。若共有p
個變量����,實際應用中一般不是找p 個主成分��,而是找出m (m < p) 個主成分就夠了��,只要這m 個主成分能反映原來所有變量的絕大部分的方差�����。主成分分析可以作為因子分析的一種方法出現����。
2.因子分析是尋找潛在的起支配作用的因子模型的方法�。因子分析是根據相關性大小把變量分組���,使得同組內的變量之間相關性較高����,但不同的組的變量相關性較低��,每組變量代表一個基本結構�,這個基本結構稱為公共因子��。對于所研究的問題就可試圖用最少個數的不可測的所謂公共因子的線性函數與特殊因子之和來描述原來觀測的每一分量�����。通過因子分析得來的新變量是對每個原始變量進行內部剖析��。因子分析不是對原始變量的重新組合���,而是對原始變量進行分解��,分解為公共因子和特殊因子兩部分�����。具體地說�,就是要找出某個問題中可直接測量的具有一定相關性的諸指標���,如何受少數幾個在專業中有意義�����、又不可直接測量到����、且相對獨立的因子支配的規律����,從而可用各指標的測定來間接確定各因子的狀態����。因子分析只能解釋部分變異�����,主成分分析能解釋所有變異��。
3.聚類分析算法是給定m 維空間R 中的n
個向量����,把每個向量歸屬到k個聚類中的某一個�,使得每一個向量與其聚類中心的距離最小�����。聚類可以理解為:
類內的相關性盡量大�,類間相關性盡量小�����。聚類問題作為一種無指導的學習問題�����,目的在于通過把原來的對象集合分成相似的組或簇����,來獲得某種內在的數據規律��。
從三類分析的基本思想可以看出�,聚類分析中并沒于產生新變量�,但是主成分分析和因子分析都產生了新變量���。
數據標準化方面的區別:

總結:
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
