關于R從不同數據源導入數據的幾種方式總結
1 使用鍵盤輸入數據
(1) 創建一個空數據框(或矩陣)��,其中變量名和變量的模式需與理想中的最終數據集一致����;
(2)針對這個數據對象調用文本編輯器�,輸入你的數據���,并將結果保存回此數據對象中���。
在下例中����,你將創建一個名為mydata的數據框����,它含有三個變量:age(數值型)��、gender(字符型)和weight(數值型)���。然后你將調用文本編輯器���,鍵入數據��,最后保存結果�。
>mydata<-data.frame(age=numeric(0),gender=character(0),weight=numeric(0))
>mydata<-edit(mydata)
2 從帶分隔符的文本文件中導入數據
你可以使用read.table()從帶分隔符的文本文件中導入數據��。此函數可讀入一個表格格式
的文件并將其保存為一個數據框����。其語法如下:
mydataframe<-read.table(file.header=logical_value,sep="delimiter",row,names="name")
其中����,file是一個帶分隔符的ASCII文本文件��,header是一個表明首行是否包含了變量名的邏輯值(TRUE或FALSE)�,sep用來指定分隔數據的分隔符�����,row.names是一個可選參數�,用以指定一個或多個表示行標識符的變量����。
請注意��,參數sep允許你導入那些使用逗號以外的符號來分隔行內數據的文件�。你可以使用
sep="\t"讀取以制表符分隔的文件�。此參數的默認值為sep=""�����,即表示分隔符可為一個或多個空格�、制表符��、換行符或回車符.
默認情況下���,字符型變量將轉換為因子�����。我們并不總是希望程序這樣做(例如處理一個含有被調查者評論的變量時)���。有許多方法可以禁止這種轉換行為���。其中包括設置選項stringsAsFactors=FALSE��,這將停止對所有字符型變量的此種轉換��。另一種方法是使用選項
colClasses為每一列指定一個類����,例如logical(邏輯型)�����、numeric(數值型)�����、character
(字符型)���、factor(因子)��。
函數read.table()還擁有許多微調數據導入方式的追加選項�。
3 導入 Excle數據
讀取一個Excel文件的最好方式�����,就是在Excel中將其導出為一個逗號分隔文件(csv)����,并使用前文描述的方式將其導入R中��。在Windows系統中�,你也可以使用RODBC包來訪問Excel文件����。
電子表格的第一行應當包含變量/列的名稱�。
首先�,下載并安裝RODBC包�����。
你可以使用以下代碼導入數據:
>install.packages("RODBC")
library(RODBC)
channel<-odbcConnectExcel("myfile.xls")
mydataframe<-sqlFetch(hannel,"mysheet")
odbcClose(channel)
這里的myfile.xls是一個Excel文件�����,mysheet是要從這個工作簿中讀取工作表的名稱����,
channel是一個由odbcConnectExcel()返回的RODBC連接對象�,mydataframe是返回的數據框
注意:Excel2007使用了一種名為XLSX的文件格式��,實質上是多個XML文件組成的壓縮包����。xlsx包可以用來讀取這種格式的電子表格�����。在第一次使用此包之前請務必先下載并安裝好�����。包中的函數read.xlsx()可將XLSX文件中的工作表導入為一個數據框����。其最簡單的調用格式是read.xlsx(file,n)����,其中file是Excel2007工作簿的所在路徑���,n則為要導入的工作表序號��。
library(xlsx)
workbook<-"c:/mywoehbook.xlsx"
mydataframe<-read.xlsx(workbook,1)
從位于C盤根目錄的工作簿myworkbook.xlsx中導入了第一個工作表.
4從網頁抓取數據
在Web數據抓?���。╓ebscraping)的過程中�,用戶從互聯網上提取嵌入在網頁中的信息�,并將其保存為R中的數據結構以做進一步的分析�。完成這個任務的一種途徑是使用函數readLines()下載網頁��,然后使用如grep()和gsub()一類的函數處理它�����。對于結構復雜的網頁��,可以使用RCurl包和XML包來提取其中想要的信息�����。
5 導入SPSS數據
SPSS數據集可以通過foreign包中的函數read.spss()導入到R中���,也可以使用Hmisc包中的spss.get()函數��。函數spss.get()是對read.
spss()的一個封裝��,它可以為你自動設置后者的許多參數���,讓整個轉換過程更加簡單一致��,最后得到數據分析人員所期望的結果����。
首先�,下載并安裝Hmisc包(foreign包已被默認安裝):
>install.packages("Hmisc")
>library(Hmisc)
>mydatframe<-spss.get("mydata.sav",use.value.lables="TRUE")
這段代碼中��,mydata.sav是要導入的SPSS數據文件�,use.value.labels=TRUE表示讓函數將帶有值標簽的變量導入為R中水平對應相同的因子�,mydataframe是導入后的R數據框��。
6導入SAS數據
R中設計了若干用來導入SAS數據集的函數�,包括foreign包中的read.ssd()和Hmisc包中的sas.get()����。遺憾的是�����,如果使用的是SAS的較新版本(SAS
9.1或更高版本)�����,你很可能會發現這些函數并不能正常工作��,因為R尚未跟進SAS對文件結構的改動�����。個人推薦兩種解決方案�����。
你可以在SAS中使用PROC EXPORT將SAS數據集保存為一個逗號分隔的文本文件�����,并使用下敘述的方法將導出的文件讀取到R中:
SAS程序:
proc export data=mydata
outfile="mydata.csv"
dbms=csv
run;
R程序:
mydata<-read.table("mydata.csv",header=TRUE,sep=",")
7導入Stata數據
> library(foreign)
> mydata<-read.dta("mydata.dta")
這里���,mydata.dta是Stata數據集���,mydataframe是返回的R數據框.
8導入netCDF數據
Unidata項目主導的開源軟件庫netCDF(network Common Data Form���,網絡通用數據格式)定
義了一種機器無關的數據格式��,可用于創建和分發面向數組的科學數據�����。netCDF格式通常用來存儲地球物理數據�����。ncdf包和ncdf4包為netCDF文件提供了高層的R接口�����。ncdf包為通過Unidata的netCDF庫(版本3或更早)創建的數據文件提供了支持����,而且在Windows���、MacOS
X和Linux上均可使用�����。ncdf4包支持netCDF 4或更早的版本��,但在Windows上尚不可用��。
考慮如下代碼:

在本例中���,對于包含在netCDF文件mynetCDFfile中的變量myvar�����,其所有數據都被讀取并保存到了一個名為myarray的R數組中�。
9導入HDF5數據
HDF5(Hierarchical
Data
Format���,分層數據格式)是一套用于管理超大型和結構極端復雜數據集的軟件技術方案���。hdf5包能夠以那些理解HDF5格式的軟件可以讀取的格式�����,將R對象寫入到一個文件中����。這些文件可以在之后被讀回R中�。這個包是實驗性質的.
10訪問數據庫管理系統
R中有多種面向關系型數據庫管理系統(DBMS)的接口�����,包括MicrosoftSQL
Server�����、MicrosoftAccess�、MySQL�����、Oracle�、PostgreSQL���、DB2��、Sybase��、Teradata以及SQLite��。使用R來訪問存儲在外部數據庫中的數據是一種分析大數據集的有效手段(參見附錄G)�����,并且能夠發揮SQL和R各自的優勢��。
1. ODBC接口
在R中通過RODBC包訪問一個數據庫也許是最流行的方式��,這種方式允許R連接到任意一種擁有ODBC驅動的數據庫��,其實幾乎就是市面上的所有數據庫�����。
第一步是針對你的系統和數據庫類型安裝和配置合適的ODBC驅動——它們并不是R的一部分���。如果你的機器尚未安裝必要的驅動���,上網搜索一下應該就可以找到����。針對選擇的數據庫安裝并配置好驅動后���,請安裝RODBC包�。你可以使用命令
install.packages("RODBC")來安裝它�。
RODBC包中的主要函數列于表2-2中�。
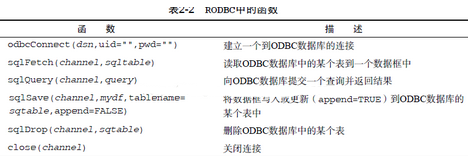
RODBC包允許R和一個通過ODBC連接的SQL數據庫之間進行雙向通信��。這就意味著你不僅可
以讀取數據庫中的數據到R中�,同時也可以使用R修改數據庫中的內容��。假設你想將某個數據庫
中的兩個表(Crime和Punishment)分別導入為R中的兩個名為crimedat和pundat的數據框�����,
可以通過如下代碼完成這個任務:
library(RODBC)
myconn<-odbcConnect("mydsn",uid="Rob",pwd="aardvark")
crimedat<-sqlFetch(myconn,Crime)
pundat<-sqlQuery(myconn,"select*from Punishment")
close(myconn)
這里首先載入了RODBC包����,并通過一個已注冊的數據源名稱(mydsn)和用戶名(rob)以及密碼(aardvark)打開了一個ODBC數據庫連接�����。連接字符串被傳遞給sqlFetch�����,它將Crime表復制到R數據框crimedat中���。然后我們對Punishment表執行了SQL語句select并將結果保存到數據框pundat中�。最后�����,我們關閉了連接���。函數sqlQuery()非常強大�,因為其中可以插入任意的有效SQL語句�。這種靈活性賦予了你選擇指定變量�����、對數據取子集�����、創建新變量���,以及重編碼和重命名現有變量的能力���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
