R語言與顯著性檢驗學習筆記
一���、何為顯著性檢驗
顯著性檢驗的思想十分的簡單���,就是認為小概率事件不可能發生����。雖然概率論中我們一直強調小概率事件必然發生�����,但顯著性檢驗還是相信了小概率事件在我做的這一次檢驗中沒有發生��。
顯著性檢驗即用于實驗處理組與對照組或兩種不同處理的效應之間是否有差異�,以及這種差異是否顯著的方法��。
常把一個要檢驗的假設記作H0,稱為原假設(或零假設)��,與H0對立的假設記作H1���,稱為備擇假設��。
⑴在原假設為真時�,決定放棄原假設����,稱為第一類錯誤���,其出現的概率通常記作α�����;
⑵在原假設不真時���,決定接受原假設����,稱為第二類錯誤��,其出現的概率通常記作β�����。
通常只限定犯第一類錯誤的最大概率α�,不考慮犯第二類錯誤的概率β�����。這樣的假設檢驗又稱為顯著性檢驗���,概率α稱為顯著性水平��。
我們常用的顯著性檢驗有t檢驗�����,卡方檢驗���,相關性檢驗等�����,在做這一些檢驗時�,有什么需要注意的呢����?
二�、正態性與P值
t檢驗��,卡方檢驗�����,相關性檢驗中的pearson方法都是建立在正態樣本的假設下的����,所以在假設檢驗開始時����,一般都會做正態性分析��。在R中可以使用shapiro.test()�����。來作正態性檢驗�。當然在norm.test包中還提供了許多其他的方法供我們選擇����。
P值是可以拒絕原假設的最小水平值����。
三����、四個重要的量
綜合前面的敘述�����,我們知道研究顯著性檢驗有四個十分重要的量:樣本大小�����,顯著性水平�����,功效���,效應值�。
樣本大?���。哼@個顯然�����,樣本越多�,對樣本的把握顯然越準確��,但是鑒于我們不可能擁有無限制的樣本�,那么多少個樣本可以達到要求�?今天的分享中我們可以通過R來找到答案�。
顯著性水平:犯第一類錯誤的概率�����,這個在做檢驗前我們會提前約定��,最后根據P值來決定取舍����。
功效:這個是在顯著性檢驗中一般不提及但實際十分有用的量�。它衡量真實事件發生的概率����。也就是說功效越大��,第二類錯誤越不可能發生��。雖然顯著性假設檢驗不提及它����,但衡量假設檢驗的好壞的重要指標便是兩類錯誤盡可能小���。
效應值:備擇假設下效應的量
四��、用pwr包做功效分析
Pwr包中提供了以下函數:
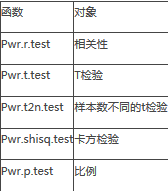
下面我們來介紹以上一些函數的用法����。
1���、 t檢驗
調用格式:
pwr.t.test(n = NULL, d = NULL, sig.level =0.05, power = NULL, type =c("two.sample", "one.sample", "paired"),alternative = c("two.sided", "less","greater"))
參數說明:
N:樣本大小
D:t檢驗的統計量
Sig.level:顯著性水平
Power:功效水平
Type:檢驗類型���,這里默認是兩樣本����,且樣本量相同
Alternative:統計檢驗是雙側還是單側����,這里默認為雙側
舉例說明:已知樣本量為60�����,單一樣本t檢驗的統計量的值為0.2(這個可以通過t.test(data)$statistic取出來)���,顯著水平α=0.1��,那么功效是多少呢�����?
R中輸入命令:
[plain] view plain copy
pwr.t.test(d=0.2,n=60,sig.level=0.10,type="one.sample",alternative="two.sided")
得到結果:
One-sample t test power calculation
n = 60
d = 0.2
sig.level = 0.1
power = 0.4555818
alternative = two.sided
我們可以看到�����,犯第二類錯誤的概率在50%以上����,我們應該相信這個結果嗎(無論根據P值來看是拒絕還是接受)����?顯然不行���,那么需要多少個樣本才能把第二類錯誤降低到10%呢���?
在R中輸入:
[plain] view plain copy
pwr.t.test(d=0.2,power=0.9,sig.level=0.10,type="one.sample",alternative="two.sided")
得到結果:
One-sample t test power calculation
n = 215.4542
d = 0.2
sig.level = 0.1
power = 0.9
alternative = two.sided
也就是說216個樣本才可以得到滿意的結果�,使得第二類錯誤概率不超過0.1.
對于兩樣本而言是類似的�,我們不在贅述���,我們下面再介紹另一種t檢驗的情況:兩樣本不相等����。
調用格式:
pwr.t2n.test(n1 = NULL, n2= NULL, d = NULL,sig.level = 0.05, power = NULL, alternative = c("two.sided","less","greater"))
參數說明:
n1 Numberof observations in the first sample
n2 Numberof observations in the second sample
d Effectsize
sig.level Significancelevel (Type I error probability)
power Powerof test (1 minus Type II error probability)
alternative acharacter string specifying the alternative hypothesis, must be one of"two.sided" (default), "greater" or "less"
例如:兩個樣本量為90�����,60�����,統計量為0.6�,單側t檢驗�,α=0.05���,為望大指標�。
R中的命令:
[plain] view plain copy
pwr.t2n.test(d=0.6,n1=90,n2=60,alternative="greater")
輸出結果:
t test power calculation
n1 = 90
n2 = 60
d = 0.6
sig.level = 0.05
power = 0.9737262
alternative = greater
可以看出功效十分大��,且α=0.05�,我們相信這次檢驗的結論很可信�����。
2��、 相關性
Pwr.r.test()函數對相關性分析進行功效分析�����。格式如下:
pwr.r.test(n = NULL, r = NULL, sig.level = 0.05, power = NULL, alternative = c("two.sided", "less","greater"))
這里和t檢驗不同的是r是線性相關系數����,可以通過cor(data1�,data2)獲取���,但需要注意的是不要輸入spearman,kendall相關系數��,他們是衡量等級相關的���。
假定我們研究抑郁與孤獨的關系�����,我們的原假設和備擇假設為:
H0:r<0.25 v.s. H1:r>0.25
假定顯著水平為0.05�,原假設不真��,我們想有90%的信心拒絕H0�,需要觀測多少呢�?
下面的代碼給出答案:
[plain] view plain copy
pwr.r.test(r=0.25,sig.level=0.05,power=0.9,alt="greater")
approximate correlation power calculation (arctangh transformation)
n = 133.8325
r = 0.25
sig.level = 0.05
power = 0.9
alternative = greater
易見�����,需要樣本134個
3��、 卡方檢驗
原假設為變量之間獨立��,備擇假設為變量不獨立��。命令為pwr.chisq.test()��,調用格式:
pwr.chisq.test(w = NULL, N = NULL, df = NULL, sig.level = 0.05, power = NULL)
其中w為效應值��,可以通過ES.w2計算出來�,df為列聯表自由度
舉例:
[plain] view plain copy
prob<-matrix(c(0.225,0.125,0.125,0.125,0.16,0.16,0.04,0.04),nrow=2,byrow=TRUE)
prob
ES.w2(prob)
pwr.chisq.test(w=ES.w2(prob),df=(2-1)*(4-1),N=200)
輸出結果:
Chi squared power calculation
w = 0.2558646
N = 200
df = 3
sig.level = 0.05
power = 0.8733222
NOTE: N is the number of observations
也就是說�����,這個觀測下反第二類錯誤的概率在13%左右����,結果較為可信�。
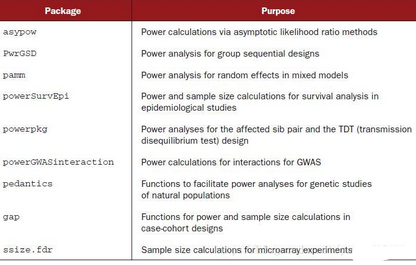
在R中還有不少與功效分析有關的包�����,我們不加介紹的把它們列舉如下:
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
