R語言回歸分析之影響分析
說明
影響分析就是探查對估計有異常影響的數據��,如果一個樣本不遵從某個模型��,但是其余數據遵從這個模型�,稱為這個樣本點為強影響點�����,也稱為高杠桿點�����,影響分析的一個重要功能就是區分這樣的數據�。
影響分析的方法有 dffits,dfbeta,dfbetas,cooks.distance,covratio,hatvalues,hat.
## 1. 回歸分析
21個兒童測試值��,x為月份�,y為智力
intellect<-data.frame(
x=c(15, 26, 10, 9, 15, 20, 18, 11, 8, 20, 7,
9, 10, 11, 11, 10, 12, 42, 17, 11, 10),
y=c(95, 71, 83, 91, 102, 87, 93, 100, 104, 94, 113,
96, 83, 84, 102, 100, 105, 57, 121, 86, 100)
)
lm.sol<-lm(y~1+x, data=intellect)
summary(lm.sol)
Call:
lm(formula = y ~ 1 + x, data = intellect)
Residuals:
Min 1Q Median 3Q Max
-15.604 -8.731 1.396 4.523 30.285
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 109.8738 5.0678 21.681 7.31e-15 ***
x -1.1270 0.3102 -3.633 0.00177 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 11.02 on 19 degrees of freedom
Multiple R-squared: 0.41, Adjusted R-squared: 0.3789
F-statistic: 13.2 on 1 and 19 DF, p-value: 0.001769
分別通過了t檢驗與F檢驗
#回歸診斷�����,調用influence.measures()并做回歸診斷圖
influence.measures(lm.sol)
Influence measures of
lm(formula = y ~ 1 + x, data = intellect) :
dfb.1_ dfb.x dffit cov.r cook.d hat inf
1 0.01664 0.00328 0.04127 1.166 8.97e-04 0.0479
2 0.18862 -0.33480 -0.40252 1.197 8.15e-02 0.1545
3 -0.33098 0.19239 -0.39114 0.936 7.17e-02 0.0628
4 -0.20004 0.12788 -0.22433 1.115 2.56e-02 0.0705
5 0.07532 0.01487 0.18686 1.085 1.77e-02 0.0479
6 0.00113 -0.00503 -0.00857 1.201 3.88e-05 0.0726
7 0.00447 0.03266 0.07722 1.170 3.13e-03 0.0580
8 0.04430 -0.02250 0.05630 1.174 1.67e-03 0.0567
9 0.07907 -0.05427 0.08541 1.200 3.83e-03 0.0799
10 -0.02283 0.10141 0.17284 1.152 1.54e-02 0.0726
11 0.31560 -0.22889 0.33200 1.088 5.48e-02 0.0908
12 -0.08422 0.05384 -0.09445 1.183 4.68e-03 0.0705
13 -0.33098 0.19239 -0.39114 0.936 7.17e-02 0.0628
14 -0.24681 0.12536 -0.31367 0.992 4.76e-02 0.0567
15 0.07968 -0.04047 0.10126 1.159 5.36e-03 0.0567
16 0.02791 -0.01622 0.03298 1.187 5.74e-04 0.0628
17 0.13328 -0.05493 0.18717 1.096 1.79e-02 0.0521
18 0.83112 -1.11275 -1.15578 2.959 6.78e-01 0.6516 *
19 0.14348 0.27317 0.85374 0.396 2.23e-01 0.0531 *
20 -0.20761 0.10544 -0.26385 1.043 3.45e-02 0.0567
21 0.02791 -0.01622 0.03298 1.187 5.74e-04 0.0628
influence.measures(lm.sol)
op <- par(mfrow=c(2,2), mar=0.4+c(4,4,1,1),
oma= c(0,0,2,0))
plot(lm.sol, 1:4)
par(op)
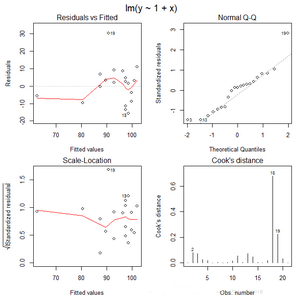
influence.measures(lm.sol)函數得到的回歸診斷共有7列�����,
其中1���,2列是dfbetas值(對應常數與變量x)���,
第三例是dffits的準則值�,
第三例是covratio的準則值,
第五例是cook值,第6例是帽子值(高杠桿值)����,
第七例影響點的標記����,
inf表明18�����,19號是強影響點�。
對診斷圖分析:
第一張圖是殘差圖����,殘差的方差滿足齊性���。
第二張圖是正態QQ圖��,除19號外基本都在直線上�����,也就是說除19號點外殘差滿足正態性��。
第三張圖標準差的平方根與預測值的散點圖���,19號樣本的值大于1.5���,說明19號樣本可能是異常值點(0.95范圍外)
第四張圖給出了COOK距離值�����,說明18號點可能是強影響點(高杠桿點)
處理強影響點:首先�����,是否錄入有誤�����。其次���,修正數據����。如果無法判斷是否有誤�����,采用剔除與加權的辦法進行修正數據�。
n<-length(intellect$x)
weights<-rep(1, n); weights[18]<-0.5
lm.correct<-lm(y~1+x, data=intellect, subset=-19,
weights=weights)
summary(lm.correct)
Call:
lm(formula = y ~ 1 + x, data = intellect, subset = -19, weights = weights)
Weighted Residuals:
Min 1Q Median 3Q Max
-14.300 -7.539 2.700 5.183 12.229
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 108.8716 4.4290 24.58 2.67e-15 ***
x -1.1572 0.2937 -3.94 0.000959 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 8.617 on 18 degrees of freedom
Multiple R-squared: 0.4631, Adjusted R-squared: 0.4333
F-statistic: 15.53 on 1 and 18 DF, p-value: 0.0009594
在程序中��,subset = -19表示去掉19樣本�����。weights<-rep(1, n)所有點權賦為1����,weights[18]<- 0.5���,18號點為0.5�,這樣可以直觀認為18號點對方程影響減少一半�����。
驗證:兩次計算的回歸直線�,和數據的散點圖����。
attach(intellect)
par(mai=c(0.8, 0.8, 0.2, 0.2))
plot(x, y, cex=1.2, pch=21, col="red", bg="orange")
abline(lm.sol, col="blue", lwd=2)
text(x[c(19, 18)], y[c(19, 18)],
label=c("19", "18"), adj=c(1.5, 0.3))
detach()
abline(lm.correct, col="red", lwd=2, lty=5)
legend(30, 120, c("Points", "Regression", "Correct Reg"),
pch=c(19, NA, NA), lty=c(NA, 1,5),
col=c("orange", "blue", "red"))
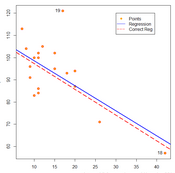
從圖中可以看出�����,19號樣本的殘差過大�����,而18號樣本對整體回歸直線有較大的影響��。
檢驗:看修正之后是否有效
op <- par(mfrow=c(2,2), mar=0.4+c(4,4,1,1), oma= c(0,0,2,0))
plot(lm.correct, 1:4)
par(op)
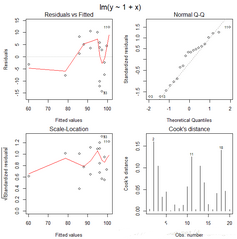
修正后的診斷圖
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330
